Si deseas distinguir tus productos, servicios o ambos de los de otra empresa, es posible que necesites una marca o nombre comercial. Descubre qué son, en qué consiste su procedimiento de registro y qué implica.

Información sobre los plazos de presentación de solicitudes de transformación de marcas de la Unión Europea en marca nacional española. Más información


Si tienes un nuevo dispositivo, producto o procedimiento que resuelva un problema técnico o tenga una ventaja práctica, existen distintas formas de protegerlo en España y en otros países. Descubre cómo hacerlo.

¿Tu innovación reside en la estética, la ornamentación o la apariencia de tu producto? Protégela mediante un diseño industrial. Descubre qué derechos confiere el registro y cómo realizar la tramitación.

Las indicaciones geográficas protegen el nombre de un producto originario de una zona geográfica, a la cual le debe una determinada calidad, reputación u otra característica. Descubre qué son, en qué consiste su procedimiento de registro y qué beneficios conceden.

Las patentes publicadas en todo el mundo son una valiosa fuente de información científica, técnica y comercial.

Si eres emprendedor/a o una empresa y quieres potenciar y mejorar la rentabilidad de tu negocio protegiendo de forma adecuada los activos intangibles de tu organización, en este espacio encontrarás lo necesario.



 76
resultados
76
resultados
 Última actualización
02/05/2026 [08:31:00]
Última actualización
02/05/2026 [08:31:00]



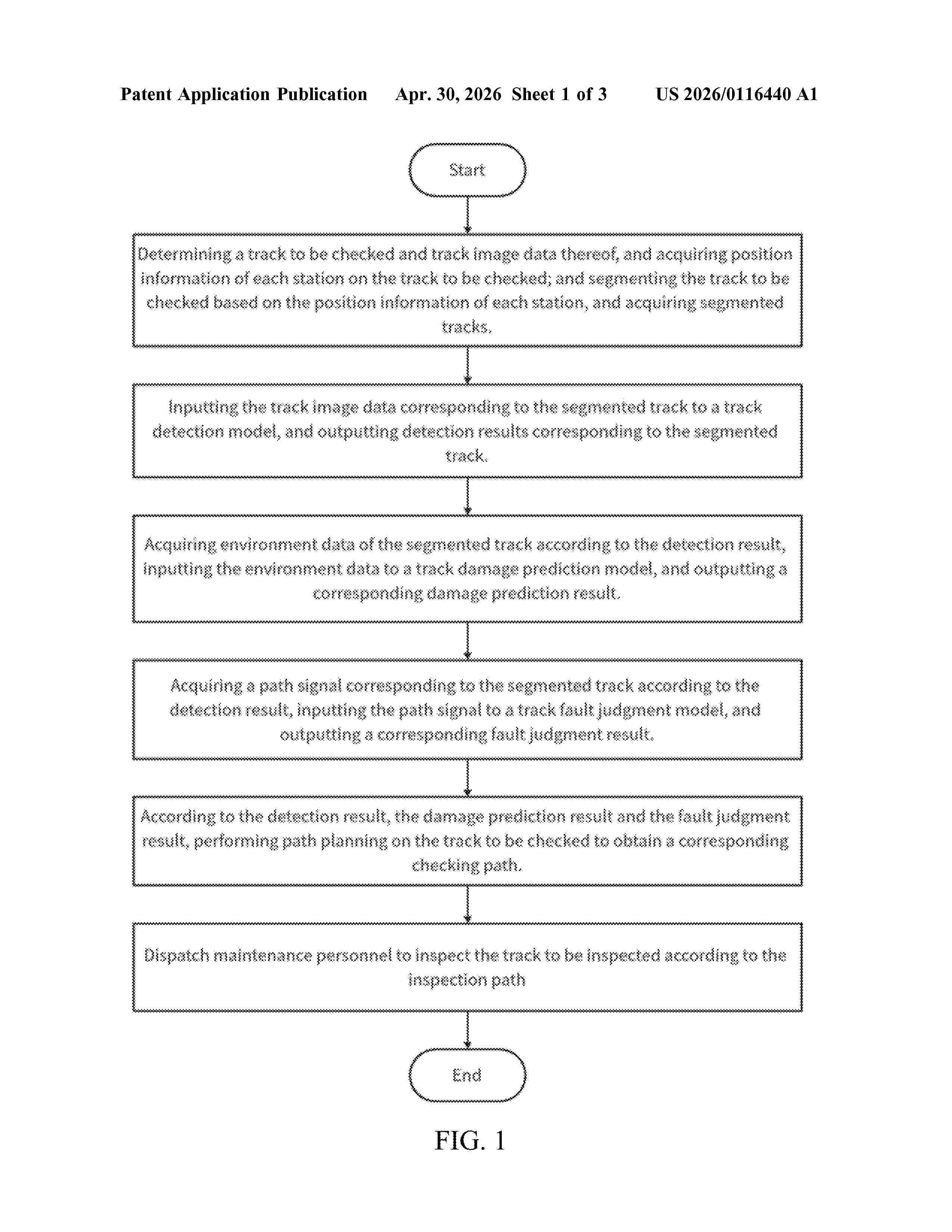
Resumen de: US20260116440A1
The invention discloses a method and system for identifying track risks based on big data analysis. The invention uses the YOLO model and SVM classifier to detect the track, extracts the multi-scale features of the track image, and can quickly and effectively detect the deformation and damage positions in the track. Based on the detection results, the RF model and BP neural network are used to further analyze the fault points of the track, and the output of each model is combined to accurately determine the fault points in the track, thereby reducing the misjudgment and omission of the fault points and providing effective support for subsequent inspection path planning. According to the fault points, the inspection path is formulated in combination with the greedy algorithm and the ant algorithm, which can effectively reduce inspection time, improve efficiency and safety of the train operation, and assist in train operation management.

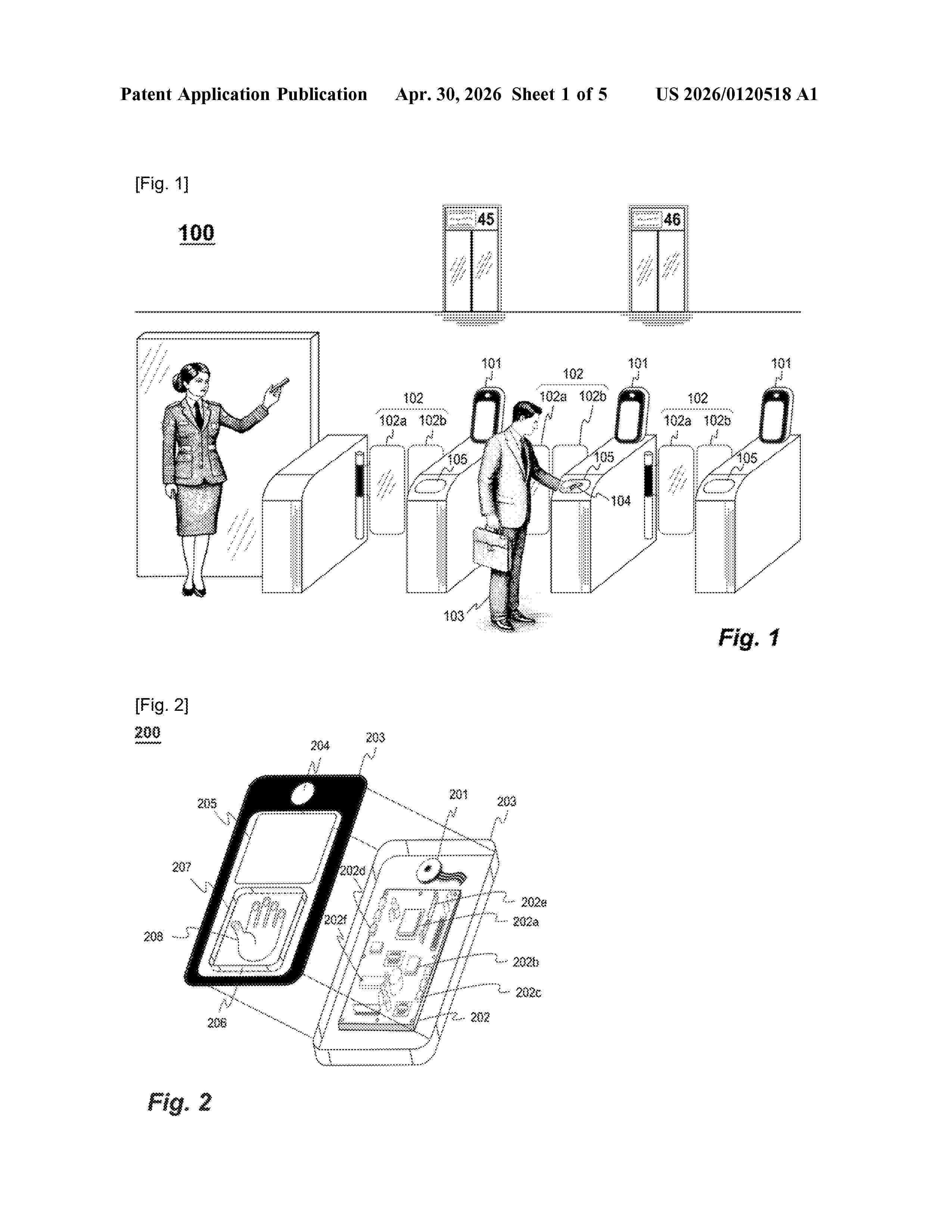
Resumen de: US20260120518A1
A method performed by a data processing device, for generating a biometric encoding matrix, the method taking, as input data, a vector, of an activation map of a neural network applied to at least one image of at least one biometric datum relating to an individual, and supplying, as output datum, an encoding matrix, the method comprising generating, from the activation map, a projection matrix along a reference direction; generating a rotation matrix that leaves the reference direction invariant; and computing a composite matrix from the projection matrix and the rotation matrix, the composite matrix being the encoding matrix.
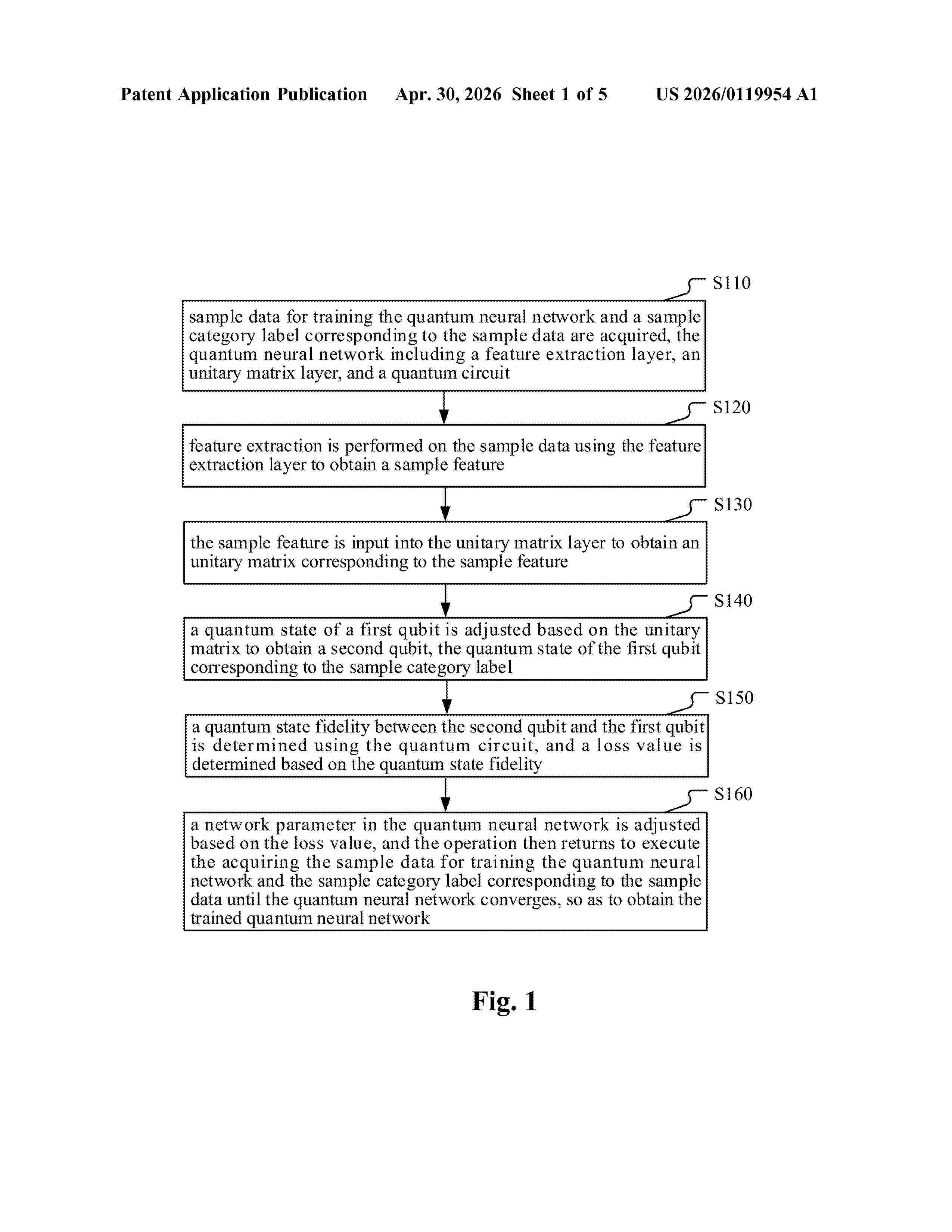
Resumen de: US20260119954A1
A method for training a quantum neural network and a method for classifying data are disclosed in the present disclosure. The method for training the quantum neural network includes acquiring sample data and a sample category label corresponding to the sample data, performing feature extraction on the sample data using a feature extraction layer of the quantum neural network, inputting the sample feature obtained by extracting into a unitary matrix layer to obtain a unitary matrix corresponding to the sample feature, adjusting a quantum state of a first qubit based on the unitary matrix to obtain a second qubit, the quantum state of the first qubit corresponds to the sample category label; determining a quantum state fidelity between the second qubit and the first qubit using the quantum circuit and then determining a loss value.
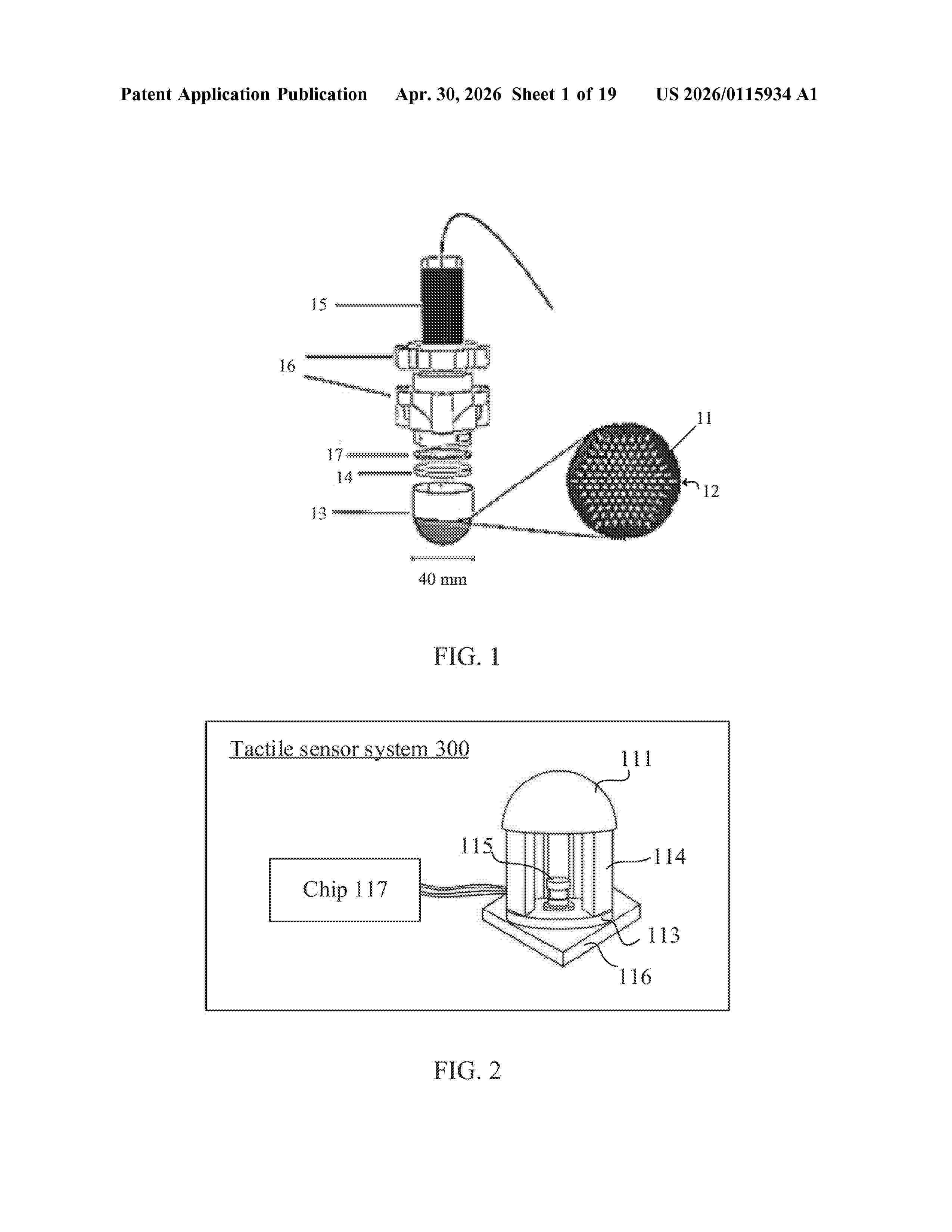
Resumen de: US20260115934A1
A vision-based tactile measurement method is provided, performed by a computer device (e.g., a chip) connected to a tactile sensor, the tactile sensor including a sensing face and an image sensing component, and the sensing face being provided with a marking pattern. The method includes: obtaining an image sequence of marking patterns distributed on a tactile sensor in physical contact with an object, wherein the marking patterns comprise a plurality of grid points connected by a plurality of grid lines; calculating a difference feature of the marking patterns between adjacent images of the image sequence, where the difference feature of the marking patterns corresponds to a displacement of the plurality of grid points and a deformation of the plurality of grid lines; and processing the difference feature of the marking patterns using a feedforward neural network to obtain a tactile measurement result of the tactile sensor.
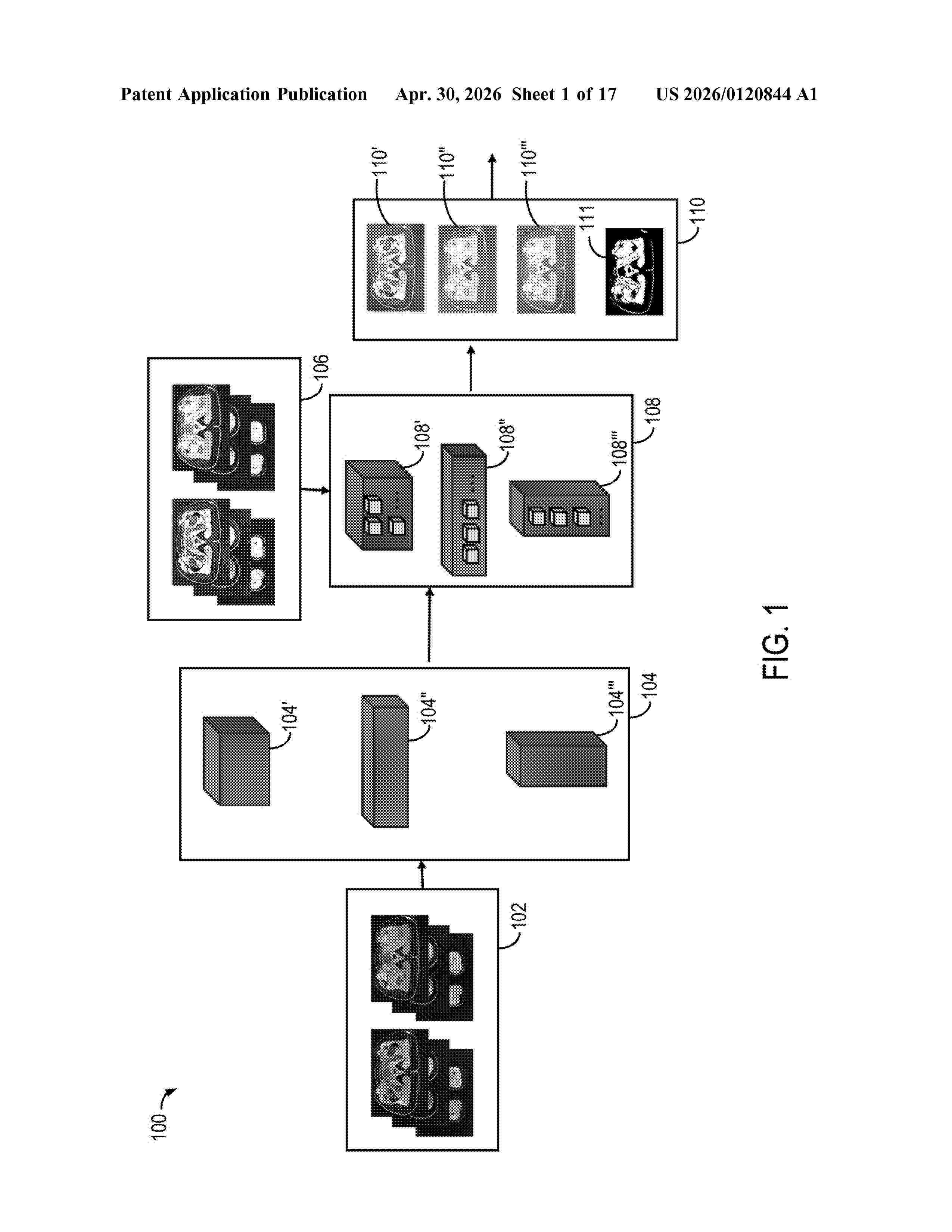
Resumen de: US20260120844A1
The present disclosure relates to systems and methods for segmenting one or more regions of interest (ROI) in medical image data. These include segmenting a plurality of medical images by inputting the plurality of medical images into each of a plurality of trained convolutional neural networks (CNNs) to identify a group of the plurality of voxels belonging to one or more ROI; calculating a plurality of variables from each of the segmented plurality of medical images on a voxel-by-voxel basis or on a ROI-by-ROI basis; generating a segmentation accuracy score from the calculated variables; and outputting a label for the one or more ROI.
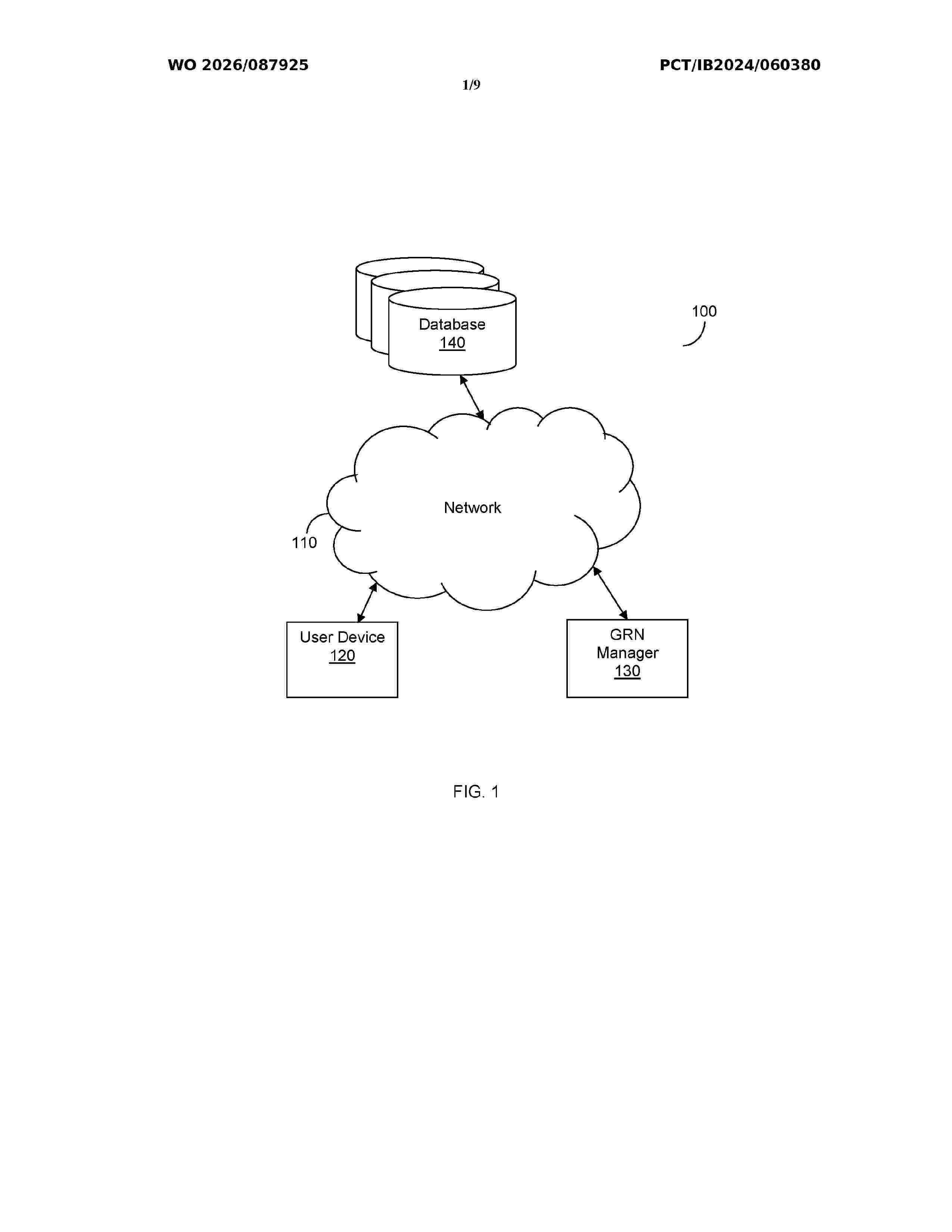
Resumen de: WO2026087925A1
A system and method for training relational networks. A method includes applying a self-organizing map (SOM) to training data in order to create a visualization. The SOM is a neural network configured to transform relationships between data items. The visualization has a lower dimensionality than the training data. The method also includes training machine learning models of a generative relational network (GRN) based on the visualization, where the GRN includes sets of nodes having respective machine learning models among the machine learning models of the GRN and the sets of nodes include a set of dominance factor nodes and a set of evolution of internal component nodes. The set of dominance factor nodes defines a dominance factor based on change intensity and change frequency, and the set of evolution of internal component nodes defines evolution with respect to changes determined based on values of the dominance factor over time.
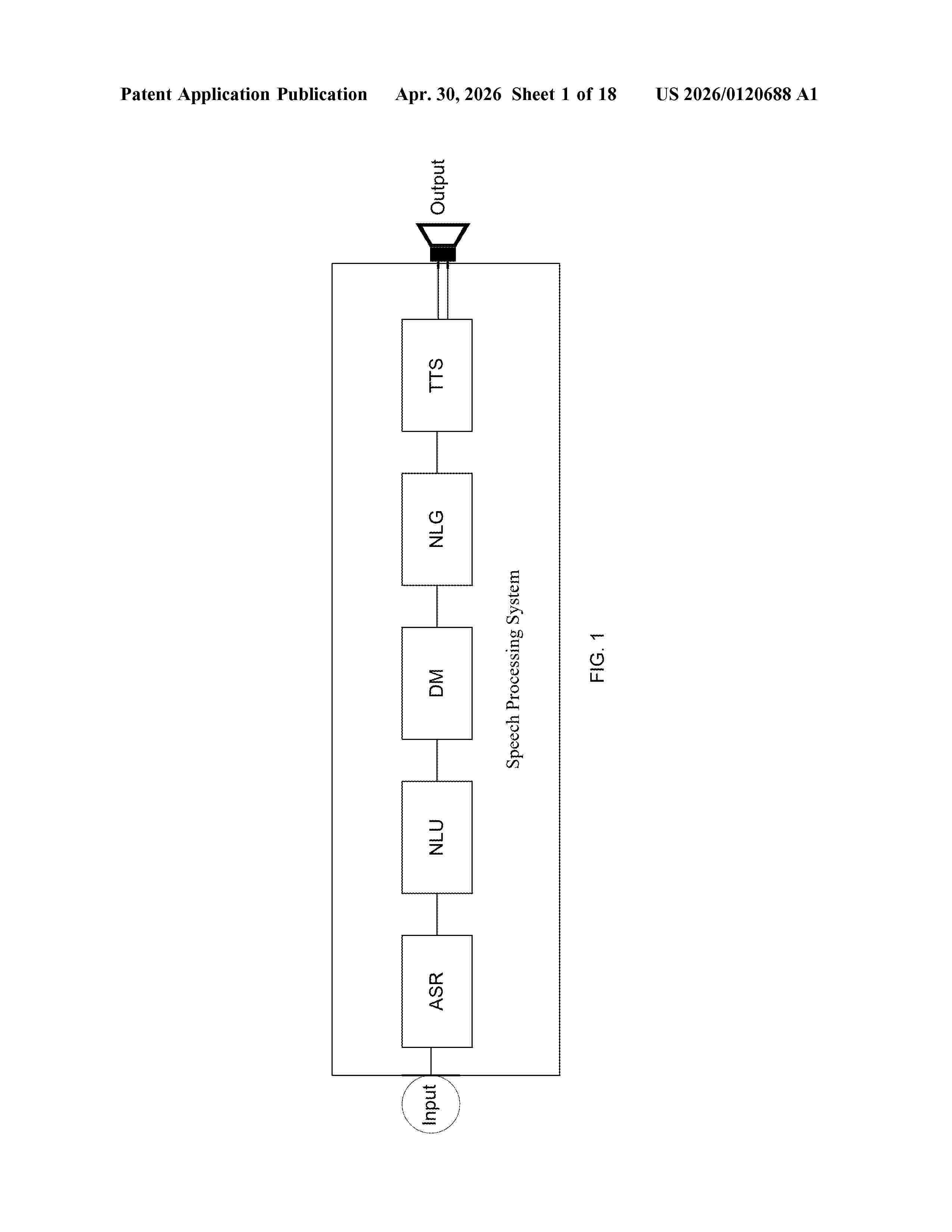
Resumen de: US20260120688A1
A method and speech processing system for communicating with a user is provided. A speech signal may be received. The received speech signal may be processed by a first unified neural network to extract one or more of intents and entities. The one or more of intents and entities may be analyzed to generate a dialogue response. A second unified neural network may generate a speech output corresponding to the dialogue response for the user. In another example, a single unified neural network may process the received speech signal to extract one or more of intents and entities. The one or more of intents and entities may be analyzed, by the single unified neural network, to generate a dialogue response. The single unified neural network may generate a speech output corresponding to the dialogue response for the user.
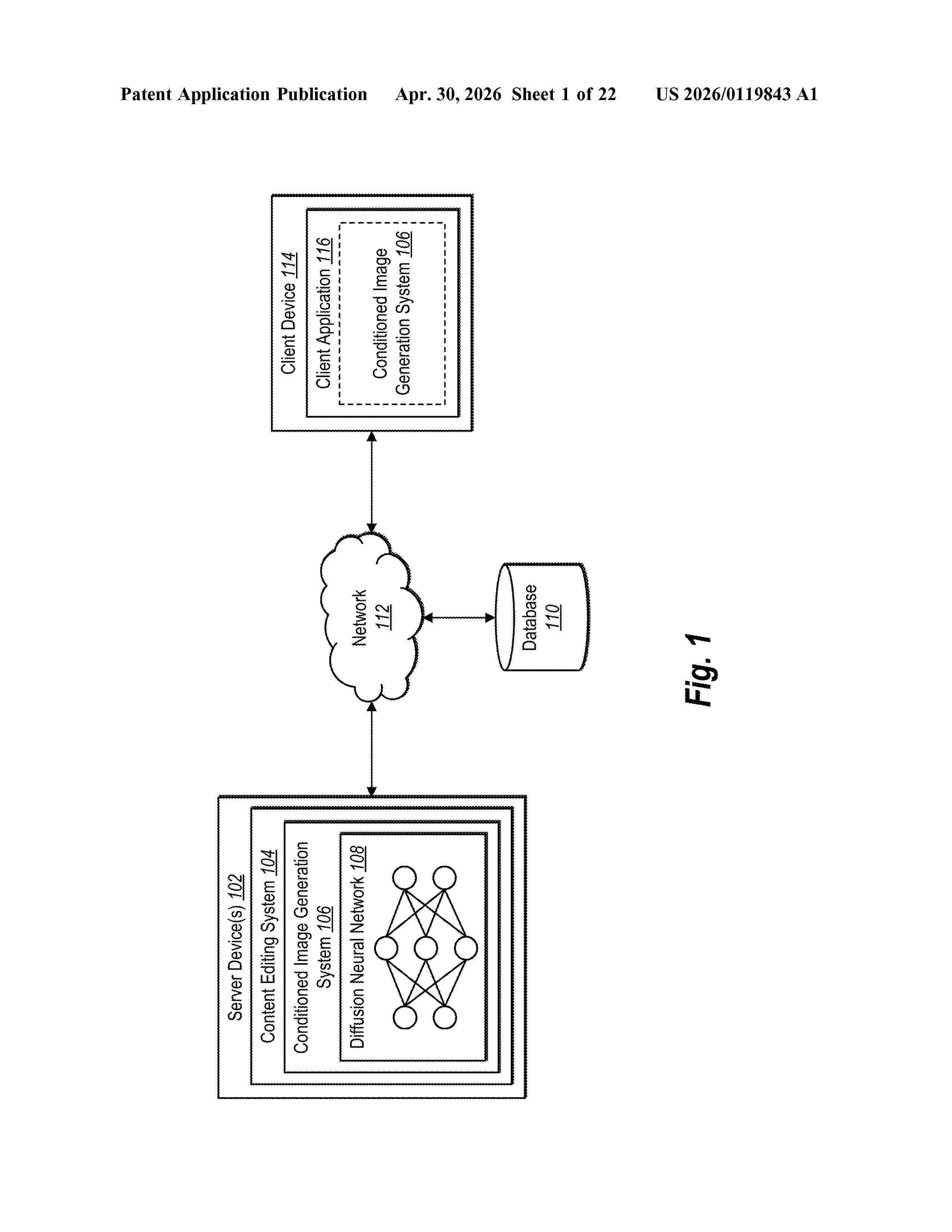
Resumen de: US20260119843A1
0000 The present disclosure relates to systems, non-transitory computer-readable media, and methods for generating synthesized digital images through a conditioned diffusion neural network utilizing an image prompt and a color conditioning input. In some embodiments, the disclosed systems receive an image prompt containing a text description of a digital image and a color conditioning input defining the position of a certain color value from a client device. In some embodiments, the disclosed systems condition a diffusion neural network using the color conditioning input and use the conditioned diffusion neural network to process the image prompt to generate a synthesized digital image correlating with the image prompt and the color conditioning input. In some embodiments, the disclosed systems provide the synthesized digital image for display on a client device.
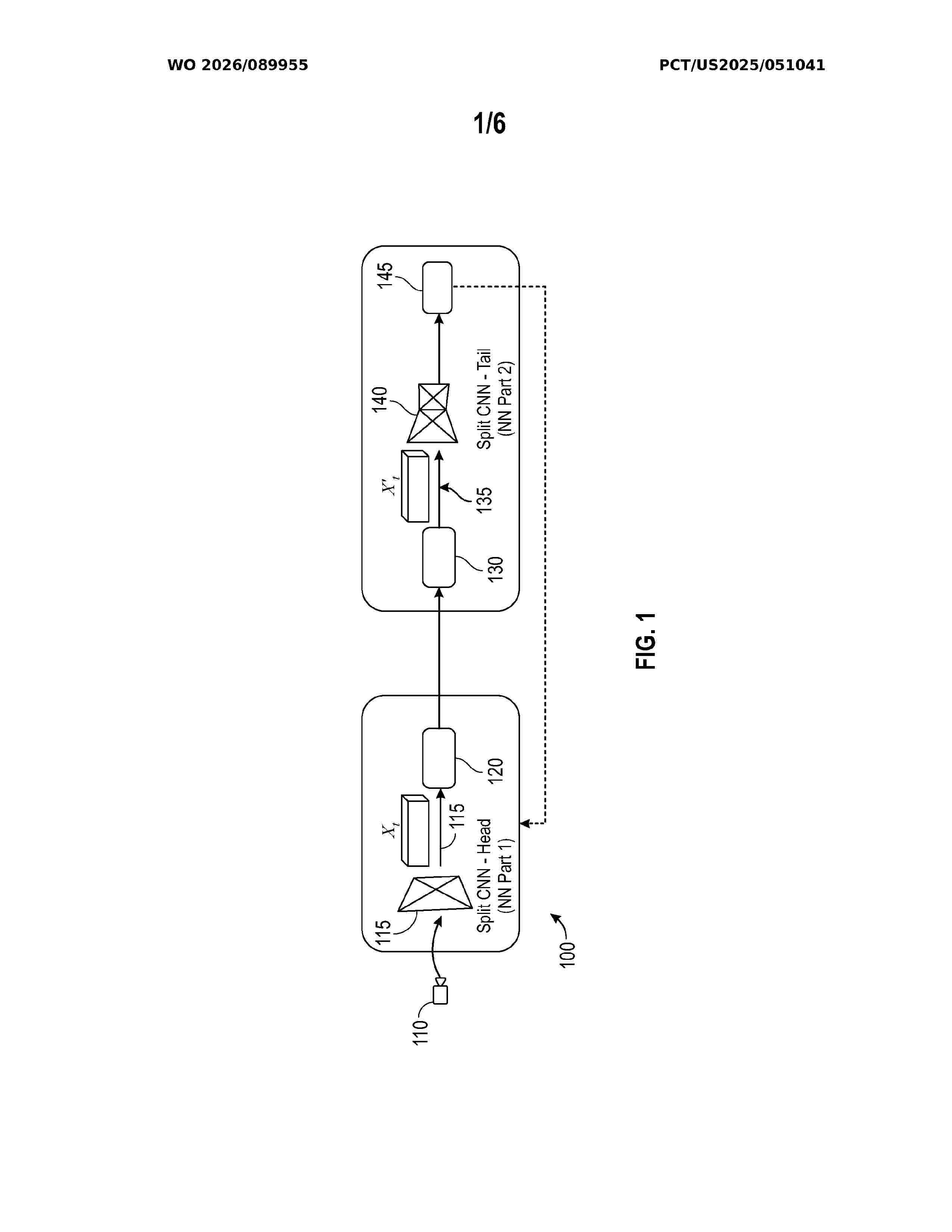
Resumen de: WO2026089955A1
A video encoder for machine-based video applications is provided which includes a split neural network front end receiving an input image signal and generating a plurality of feature maps comprising a plurality of feature tensors representing the input image signal. A feature reduction module receives the feature maps and generates at least one reduced feature map representing the original plurality of feature maps. A feature conversion module converts the reduced feature maps to a video format. A block segmentation and truncation module performs a block truncation method on blocks identified with low variability, an indication of lower importance of the information in the block, to further reduce feature map complexity. An inner encoder follows block segmentation and truncation and generates an encoded bitstream representing the plurality of feature maps.
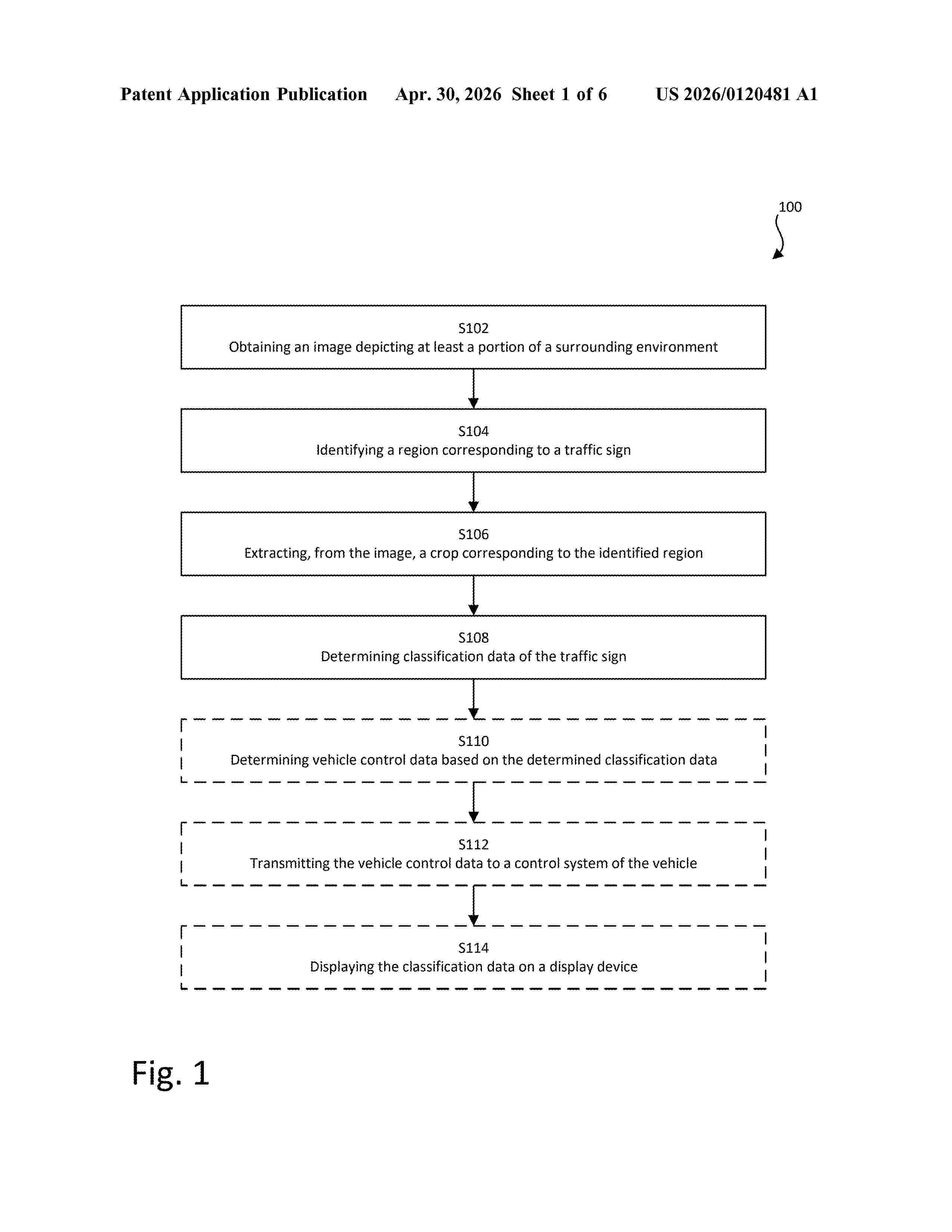
Resumen de: US20260120481A1
A computer-implemented method for classifying a traffic sign in an image, a computing device and vehicle thereof is disclosed. The method includes obtaining the image depicting at least a portion of a surrounding environment of the vehicle; identifying a region in the image corresponding to a traffic sign, by processing the image through a first machine learning model configured to output detections of traffic signs in input images; extracting a crop corresponding to the identified region, wherein the crop has a native resolution based on a size of the identified region in relation to the obtained image; and determining classification data of the traffic sign by processing the crop, at the native resolution, through a second machine learning model, wherein the second machine learning model is an attention-based neural network, trained to process input images of traffic signs of varying resolution and to generate corresponding classification data.
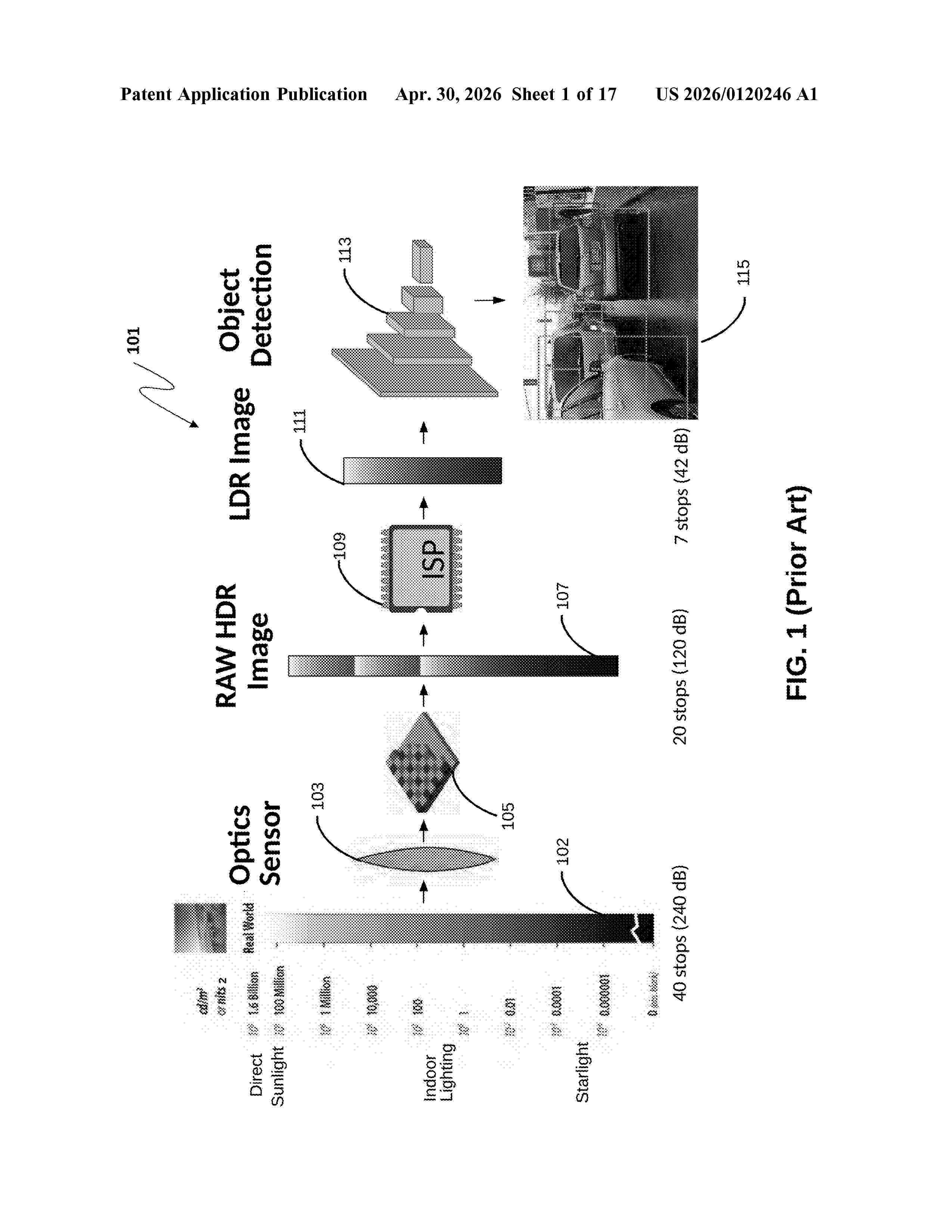
Resumen de: US20260120246A1
0000 An auto-exposure control is proposed for high dynamic range images, along with a neural network for exposure selection that is trained jointly, end-to-end with an object detector and an image signal processing (ISP) pipeline. Corresponding method and system for high dynamic range object detection are also provided.
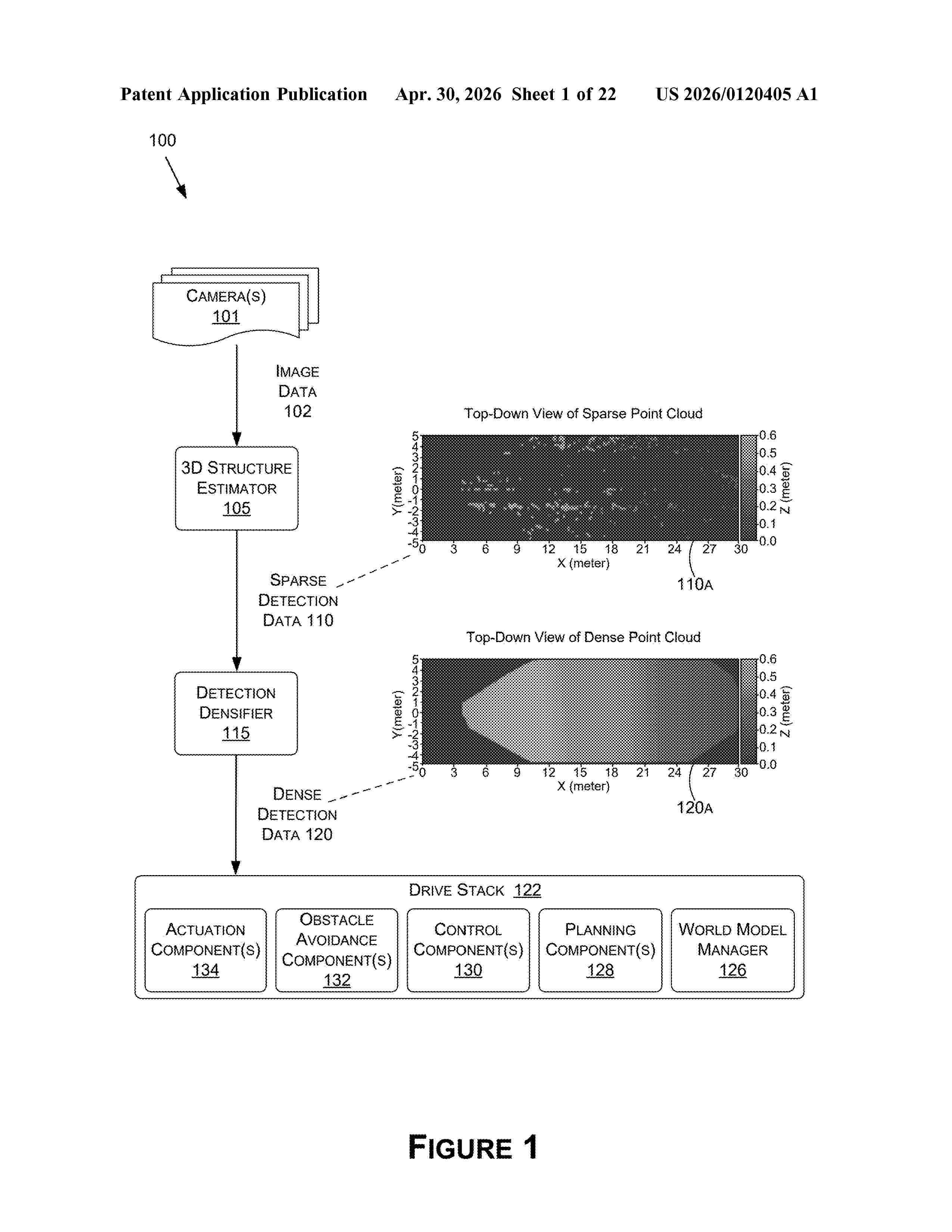
Resumen de: US20260120405A1
In various examples, to support training a deep neural network (DNN) to predict a dense representation of a 3D surface structure of interest, a training dataset is generated using a simulated environment. For example, a simulation may be run to simulate a virtual world or environment, render frames of virtual sensor data (e.g., images), and generate corresponding depth maps and segmentation masks (identifying a component of the simulated environment such as a road). To generate input training data, 3D structure estimation may be performed on a rendered frame to generate a representation of a 3D surface structure of the road. To generate corresponding ground truth training data, a corresponding depth map and segmentation mask may be used to generate a dense representation of the 3D surface structure.
Resumen de: US20260120256A1
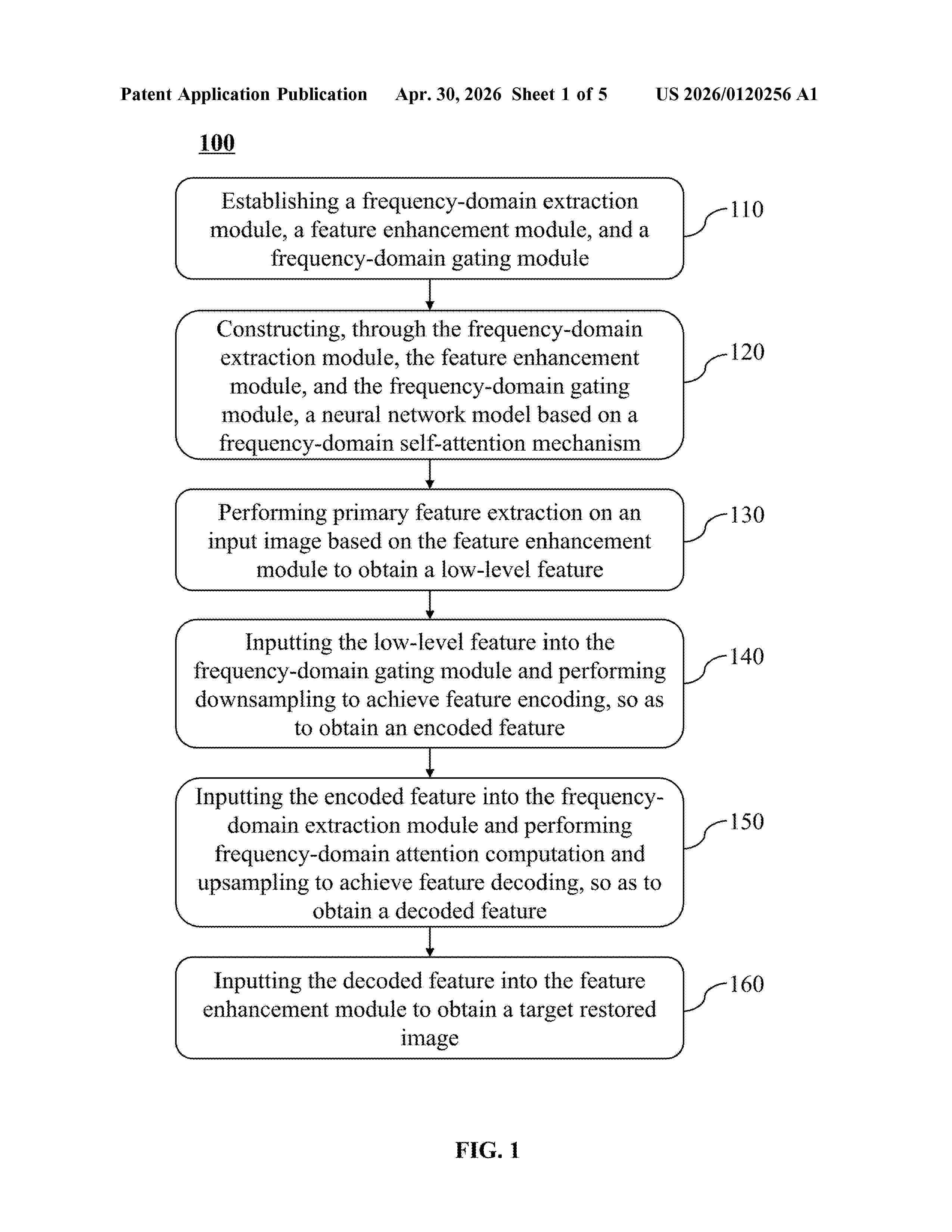
A deep-learning-based method for eliminating a broadband effect and a synthesized-beam effect in low-frequency Square Kilometre Array (SKA) is provided. The method includes: establishing a frequency-domain extraction module, a feature enhancement module, and a frequency-domain gating module; constructing, based on the frequency-domain extraction module, the feature enhancement module, and the frequency-domain gating module, a neural network model based on a frequency-domain self-attention mechanism; performing primary feature extraction on an input image based on the feature enhancement module to obtain a low-level feature; inputting the low-level feature into the frequency-domain gating module and performing downsampling to achieve feature encoding, so as to obtain an encoded feature; inputting the encoded feature into the frequency-domain extraction module and performing frequency-domain attention computation and upsampling to achieve feature decoding, so as to obtain a decoded feature; and inputting the decoded feature into the feature enhancement module to obtain a target restored image.
Resumen de: WO2026086051A1
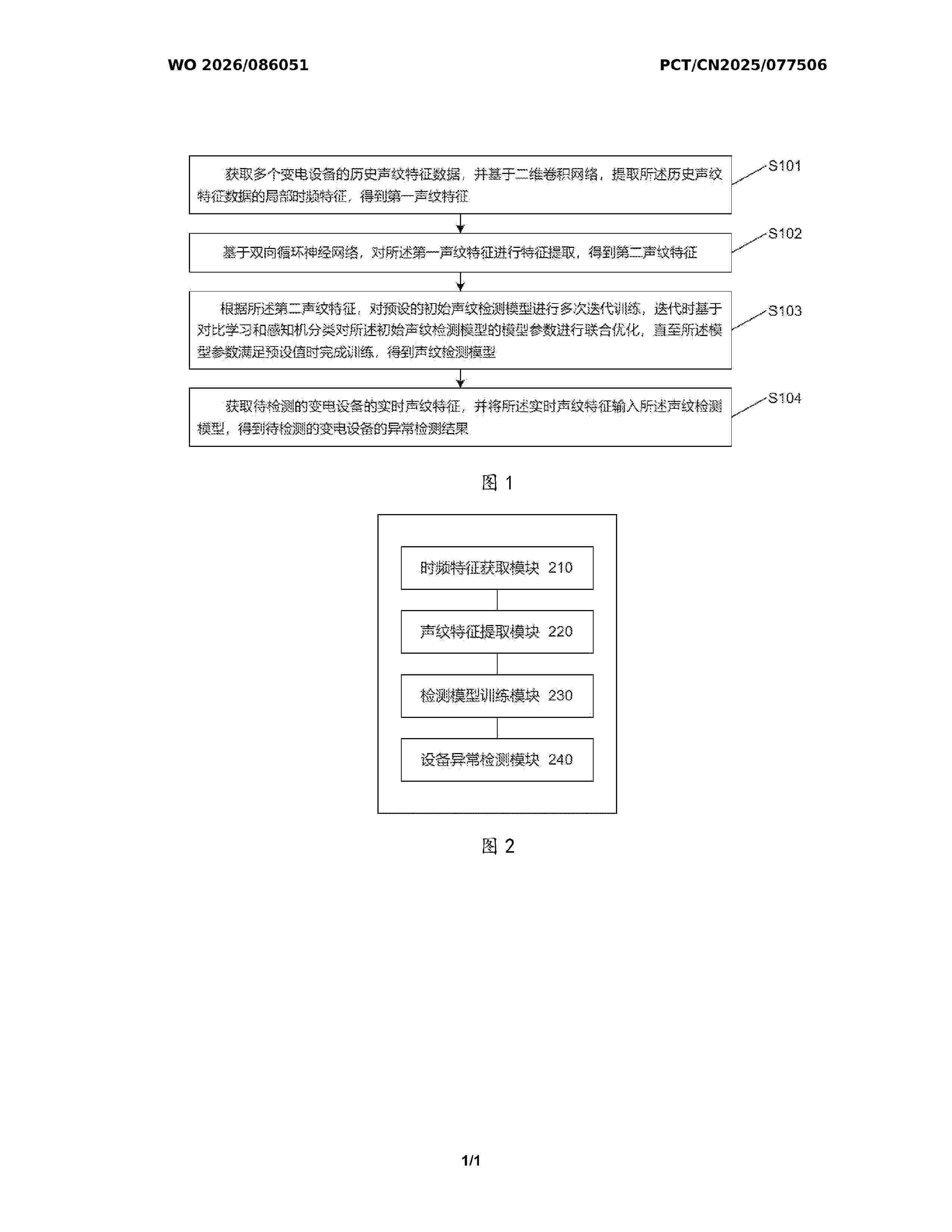
A power transformation device anomaly detection method and apparatus based on a voiceprint, which method and apparatus relate to the field of power transformation device monitoring, and can solve the technical problem of the accuracy of existing power transformation device anomaly detection based on a voiceprint being low. The method comprises: acquiring historical voiceprint feature data of a plurality of power transformation devices, and on the basis of a two-dimensional convolutional network, extracting local time-frequency features of the historical voiceprint feature data, so as to obtain first voiceprint features (S101); on the basis of a bidirectional recurrent neural network, performing feature extraction on the first voiceprint features, so as to obtain second voiceprint features (S102); on the basis of the second voiceprint features, performing iterative training on a preset initial voiceprint detection model multiple times, and during iteration, performing joint optimization on model parameters of the initial voiceprint detection model on the basis of contrastive learning and perceptron classification, and completing the training when the model parameters meet preset values, so as to obtain a voiceprint detection model (S103); and acquiring a real-time voiceprint feature of a power transformation device to be subjected to detection, and inputting the real-time voiceprint feature into the voiceprint detection model, so as to obtain an anomaly detection result of the
Resumen de: WO2026086052A1
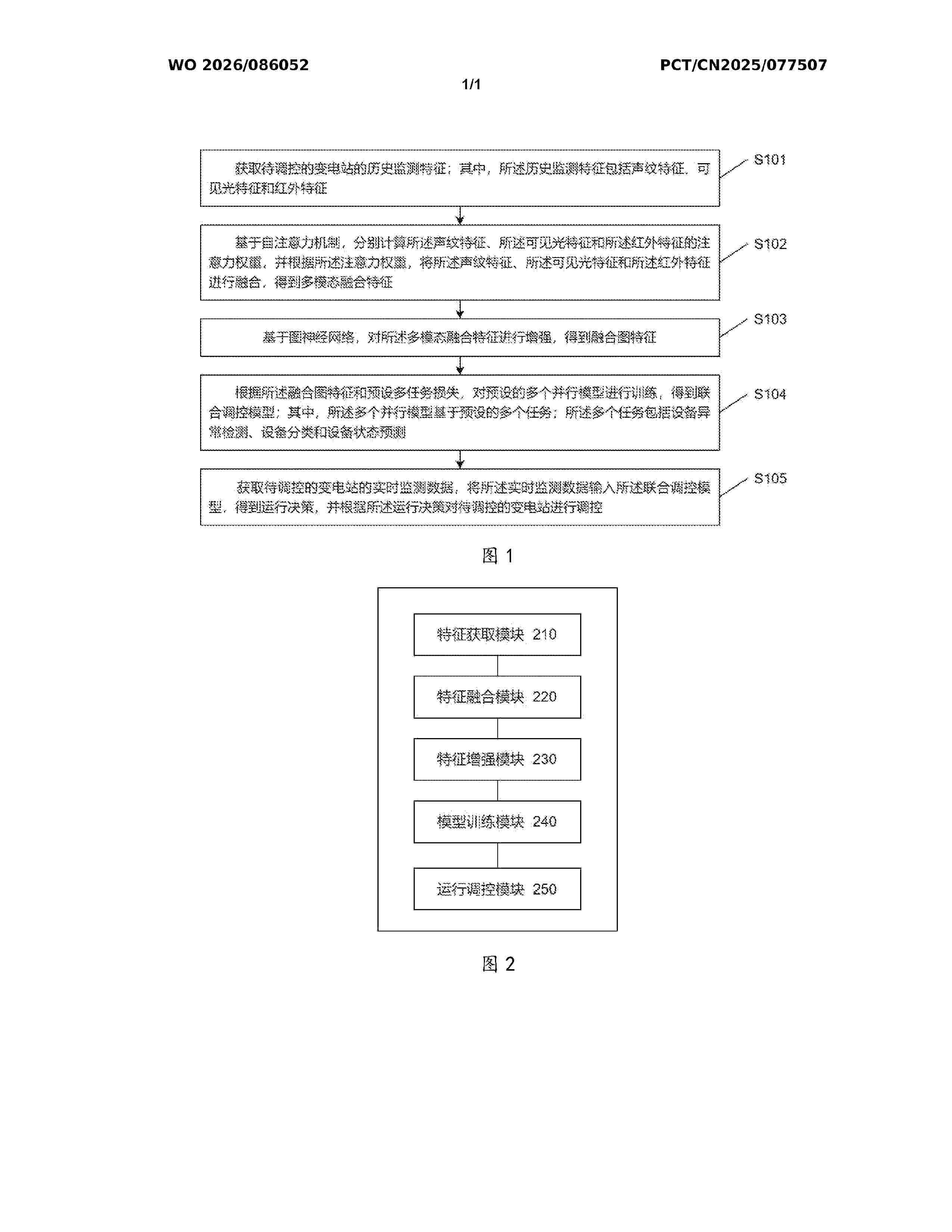
The present application relates to the field of substation operation regulation and control. Disclosed are a multimodal-based substation operation regulation and control method and apparatus. The method comprises: acquiring historical monitoring features of a substation to be regulated and controlled; on the basis of a self-attention mechanism, respectively calculating attention weights of a voiceprint feature, a visible light feature and an infrared feature, and, on the basis of the attention weights, fusing the voiceprint feature, the visible light feature and the infrared feature to obtain a multi-modal fused feature; on the basis of a graph neural network, enhancing the multi-modal fused feature to obtain a fused graph feature; on the basis of the fused graph feature and a preset multi-task loss, training a plurality of preset parallel models to obtain a joint regulation and control model; and acquiring real-time monitoring data of said substation, inputting the real-time monitoring data into the joint regulation and control model to obtain an operation decision, and, on the basis of the operation decision, regulating and controlling said substation.
Resumen de: US20260116431A1
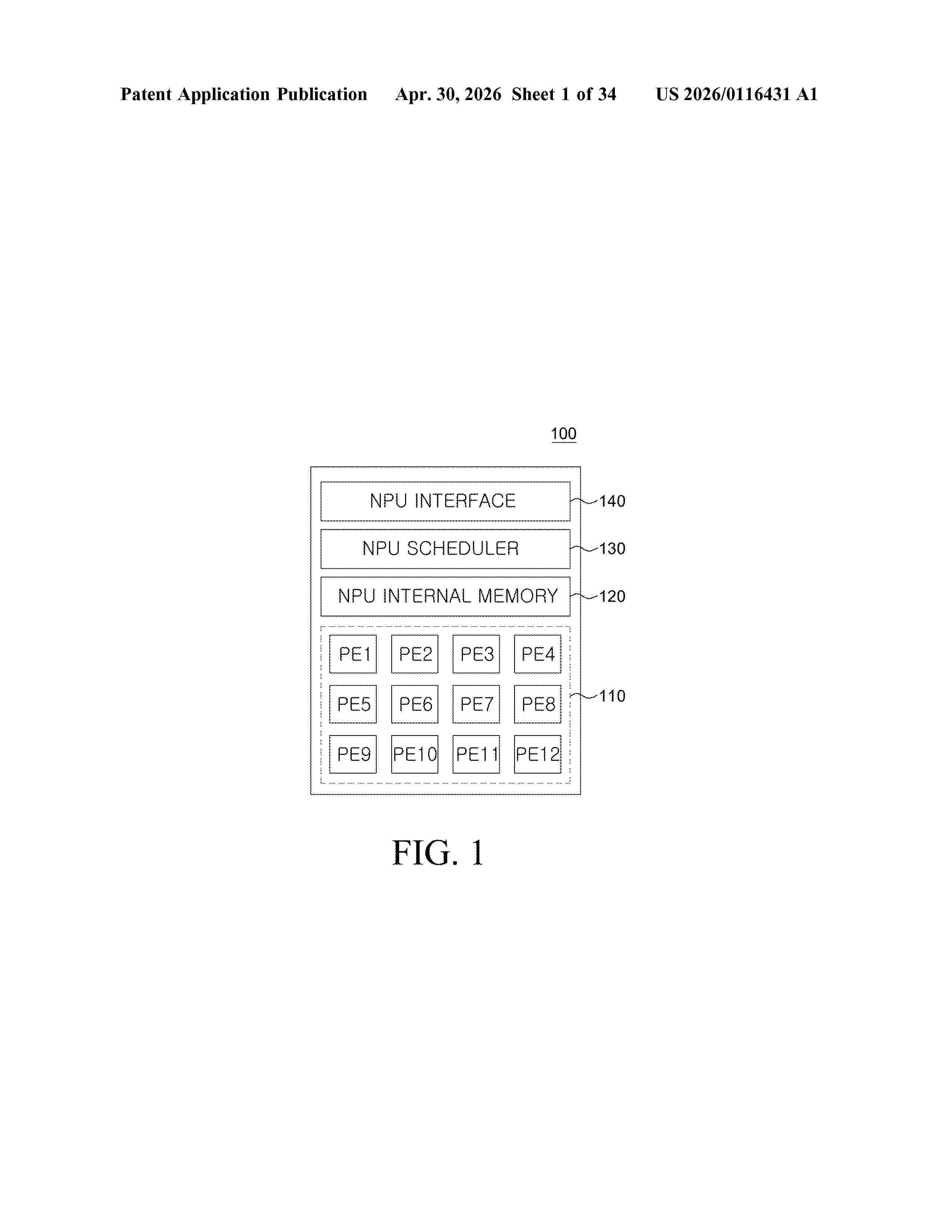
A neural processing unit (NPU) includes a controller including a scheduler, the controller configured to receive from a compiler a machine code of an artificial neural network (ANN) including a fusion ANN, the machine code including data locality information of the fusion ANN, and receive heterogeneous sensor data from a plurality of sensors corresponding to the fusion ANN; at least one processing element configured to perform fusion operations of the fusion ANN including a convolution operation and at least one special function operation; a special function unit (SFU) configured to perform a special function operation of the fusion ANN; and an on-chip memory configured to store operation data of the fusion ANN, wherein the schedular is configured to control the at least one processing element and the on-chip memory such that all operations of the fusion ANN are processed in a predetermined sequence according to the data locality information.
Resumen de: US20260119836A1
A method and device for interpreting a graph neural network based on FPGA acceleration propose to use FPGA hardware to accelerate interpretation process of the graph neural network oriented to node classification in parallel, and improve node traversal and shortest path search of BFS, thereby optimizing requirements of algorithm calculation and storage, and accelerating generation of interpretation results. During calculating HN values, the present disclosure optimizes multiplication operation using the matrix characteristics, transforms the dense matrix multiplication into sparse-dense matrix multiplication, and optimizes the resource occupation using multi-PE parallel processing, greatly improving performance of graph neural network interpretation acceleration. Moreover, an overall architecture based on FIFO storage calculation task distribution is designed to reduce calculation difference between nodes, solving the difficulty of high time complexity of the graph neural network interpretation method based on node classification in actual data applications and improving the time efficiency of interpretation.
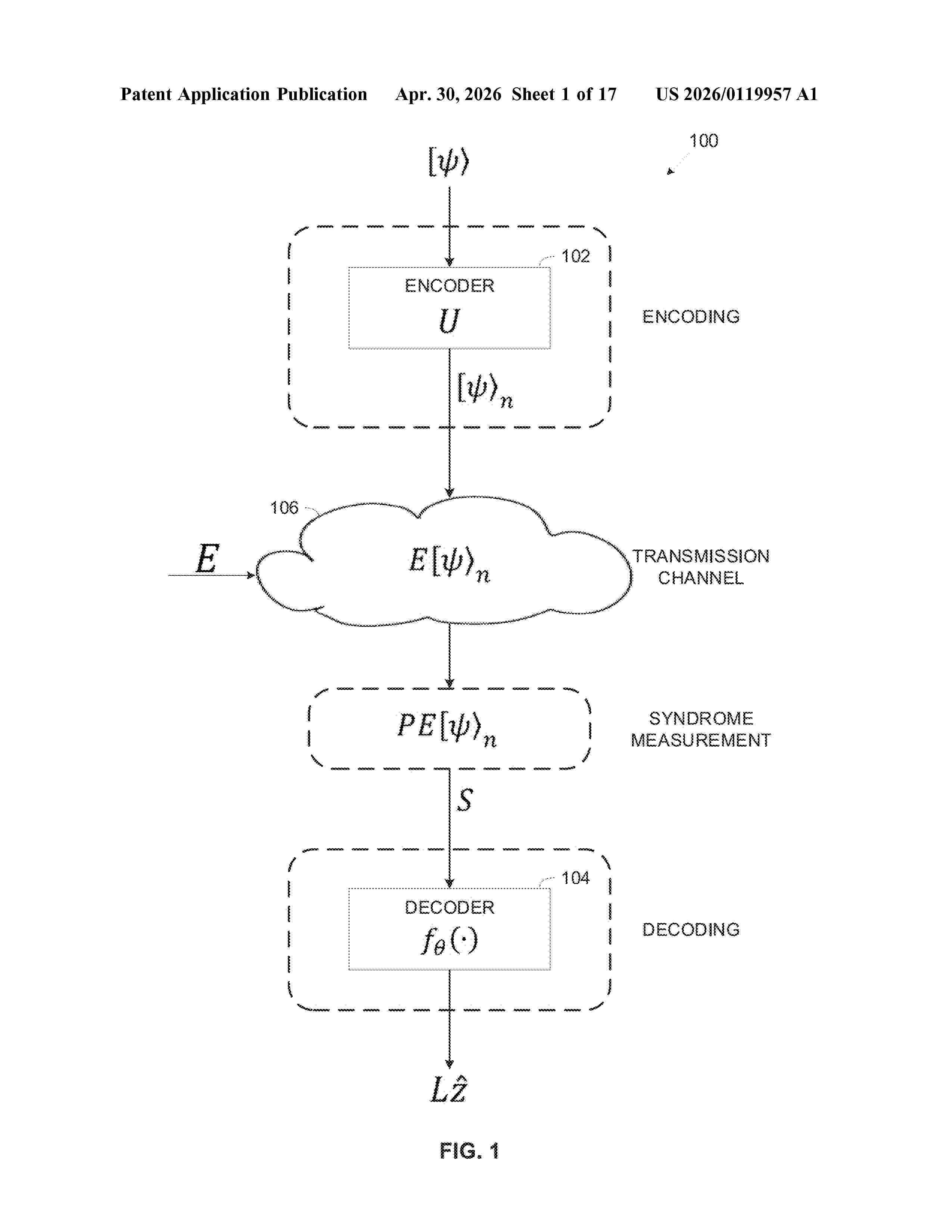
Resumen de: US20260119957A1
0000 Transformer neural network based decoder for decoding Quantum Error Correction Codes (QECC), comprising, an input layer, a plurality of decoding layers, and an output layer. The input layer is adapted to receive initial noise estimation computed by a noise estimator for noise injected to syndrome bits of codewords encoded using QECC and transmitted over transmission channel(s) subject to interference, and create embeddings for the syndrome bits. The decoding layers adapted to compute an estimated logical operator matrix of each codeword, each comprises a self-attention layer constructed according to a mask indicative of a relation between the embeddings derived from a parity-check matrix of the error correction code. The plurality of decoding layers are trained using a combined loss function directed to minimize LER, BER, and error rate of the noise estimator. The output layer is adapted to produce a vector representing predicted soft error of the codeword's logical operator matrix.
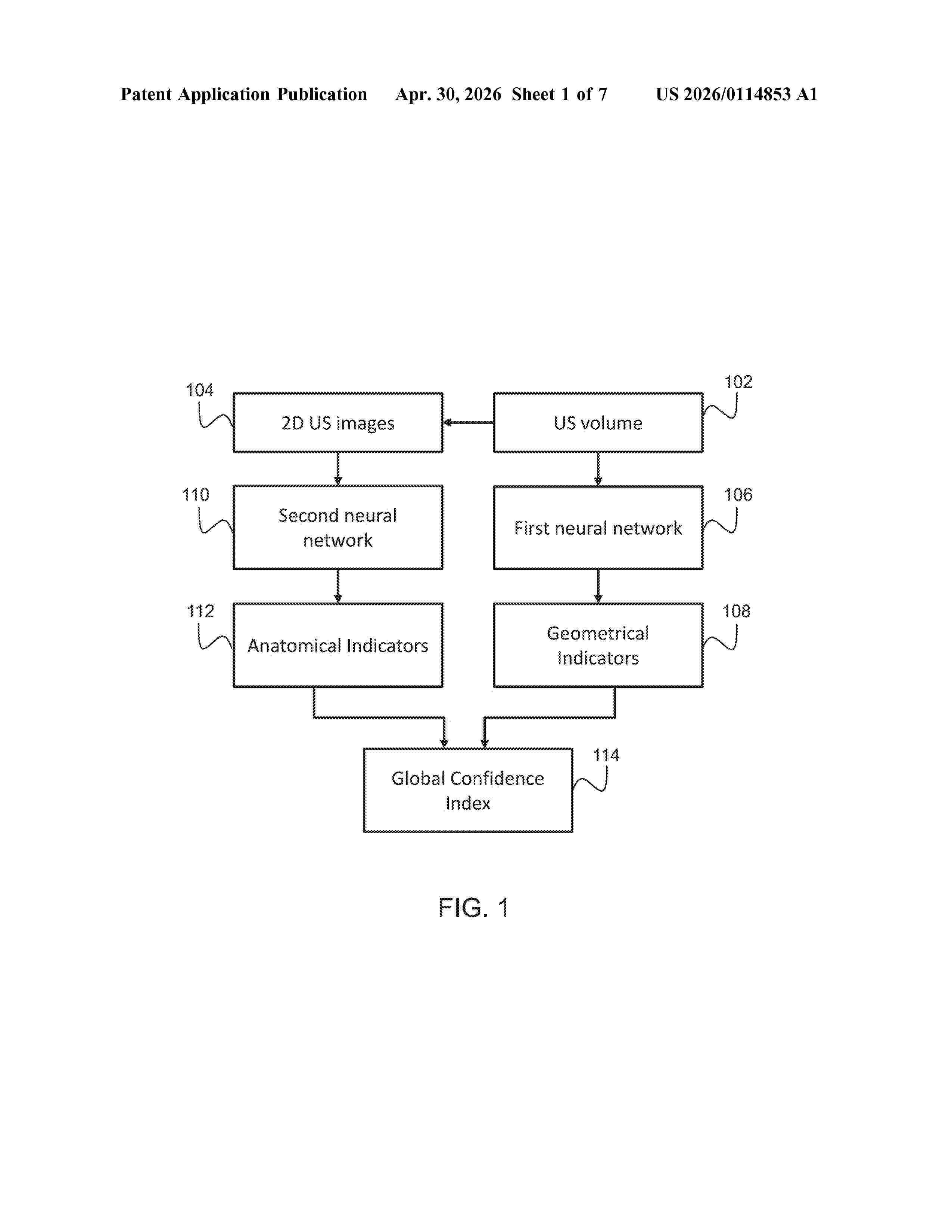
Resumen de: US20260114853A1
The invention provides a method for determining a global confidence index for a 2D ultrasound image extracted from a 3D ultrasound volume, wherein the global confidence index indicates the suitability of the 2D ultrasound image for medical measurements. The method comprises obtaining a 3D ultrasound volume of a subject and extracting a set of at least one 2D ultrasound image from the 3D ultrasound volume. A set of geometrical indicators is obtained with a previously trained first neural network, and a set of 2D ultrasound images is processed with a second neural network, wherein the output of the second neural network is a set of anatomical indicators and wherein the anatomical indicators indicate at least the presence of anatomical landmarks. A global confidence index is then determined for each one of the set of 2D ultrasound images based on the geometrical indicators and the anatomical indicators.
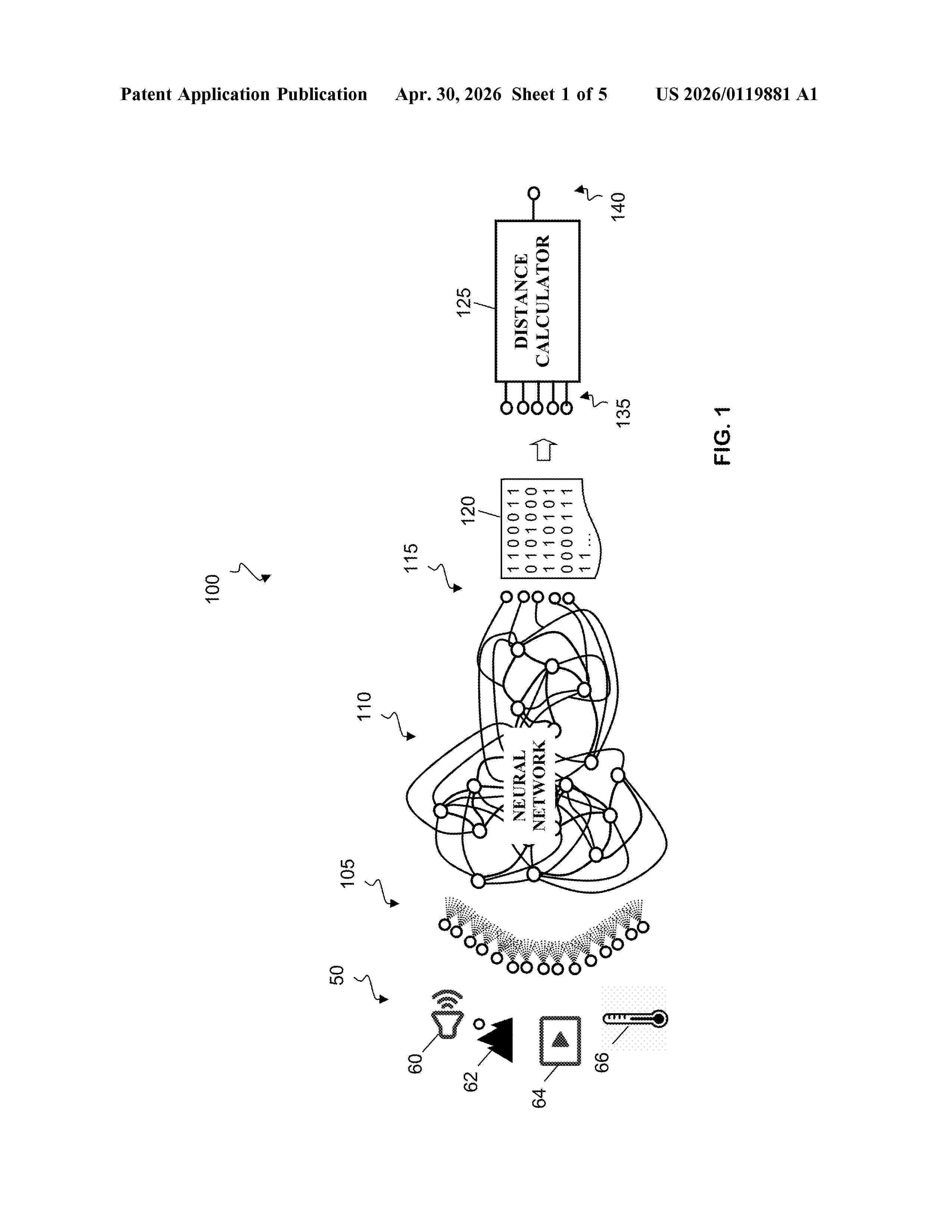
Resumen de: US20260119881A1
0000 Distance metrics and clustering in recurrent neural networks. For example, a method includes determining whether topological patterns of activity in a collection of topological patterns occur in a recurrent artificial neural network in response to input of first data into the recurrent artificial neural network, and determining a distance between the first data and either second data or a reference based on the topological patterns of activity that are determined to occur in response to the input of the first data.
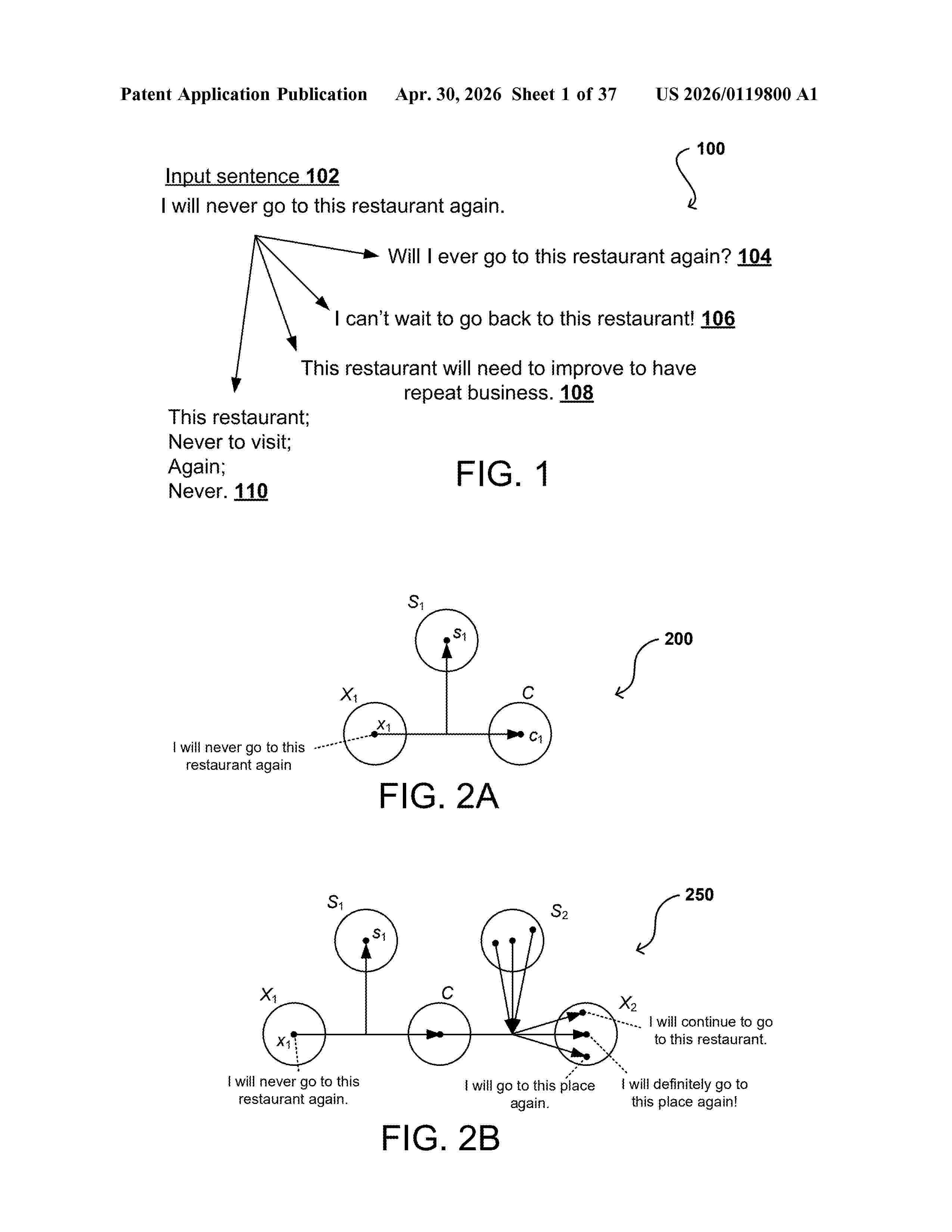
Resumen de: US20260119800A1
Apparatuses, systems, and techniques to transfer grammar between sentences. In at least one embodiment, one or more first sentences are translated into one or more second sentences having different grammar using one or more neural networks.
Resumen de: EP4733990A1
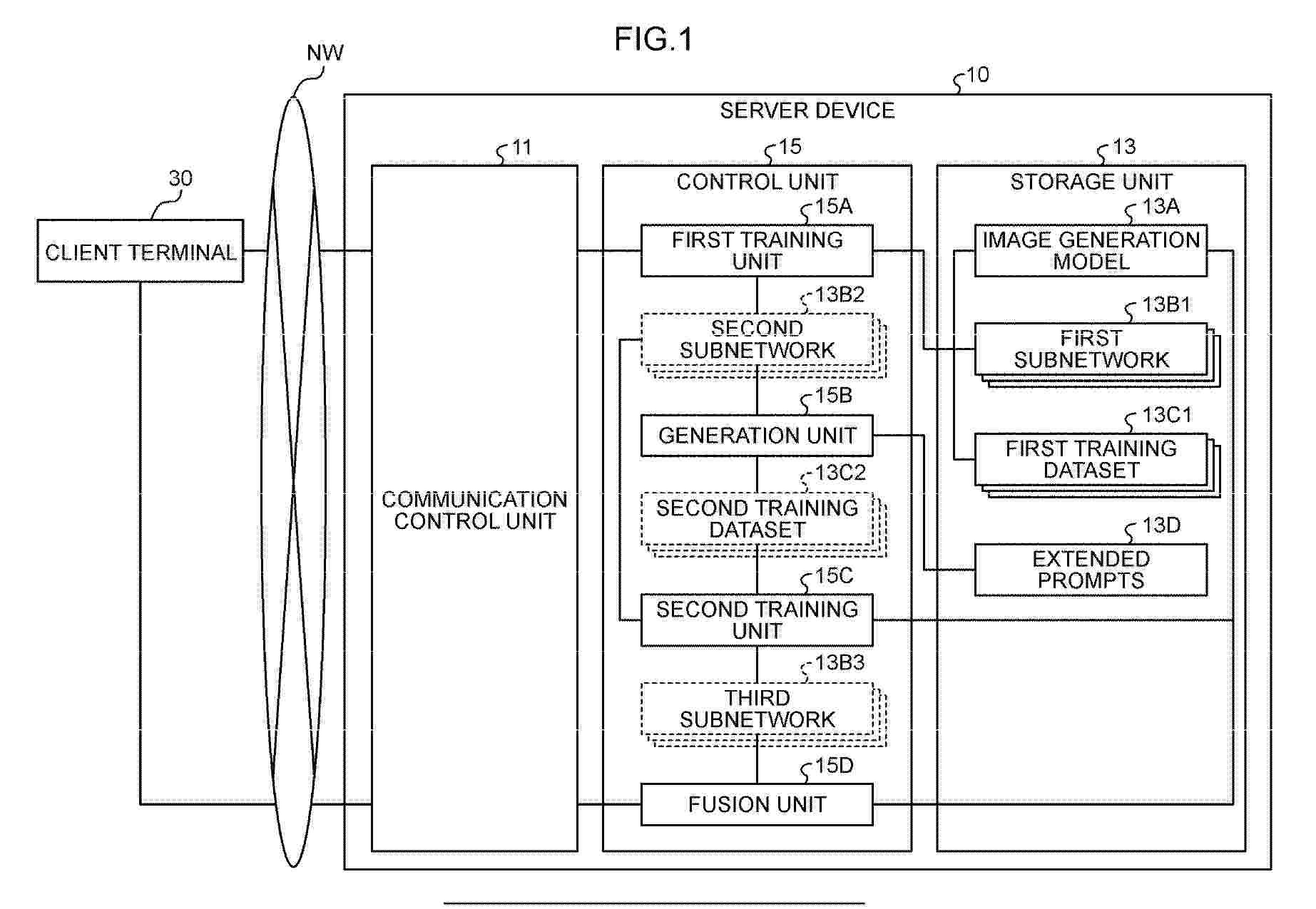
A generation program of a neural network is used as a subnetwork to be added to an image generation AI, the generation program causes a computer to execute a process including: training each of a plurality of neural networks using a training dataset that includes a plurality of pieces of training data where image data corresponding to specific concepts different for each of the neural networks is associated with a specific token and part of a plurality of tokens different from the specific token; and fusing the neural networks after the training to generate a subnetwork that corresponds to a plurality of concepts.
Resumen de: WO2025240481A1
Methods, systems, and apparatus, including computer programs encoded on computer storage media, for generating an audio signal. One of the methods includes receiving an input image; processing, using one or more generative neural networks, the input image to generate a music caption describing one or more audio features corresponding to the input image; and processing, using an audio generative neural network, the music caption to generate an audio signal described by the music caption.
Resumen de: US20260111744A1
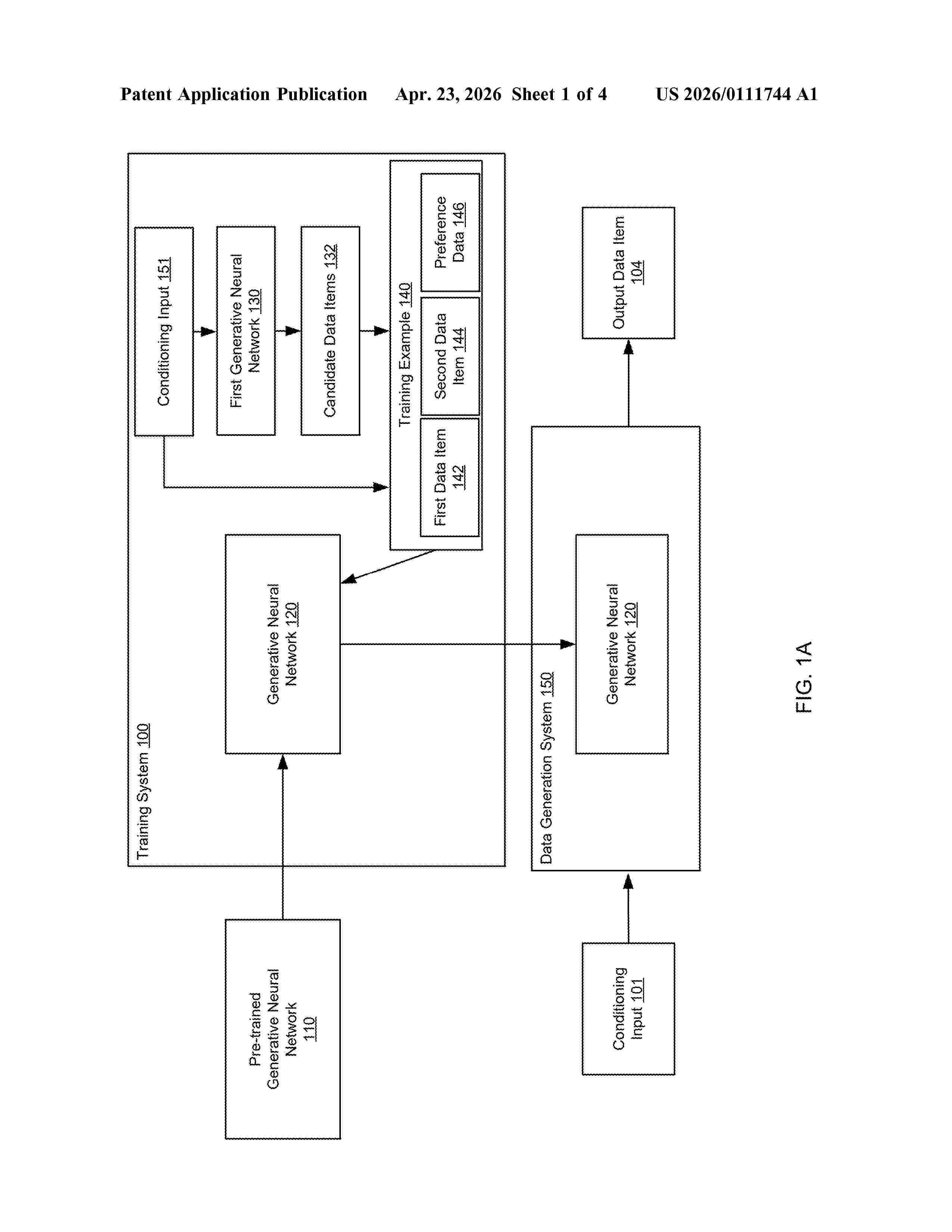
0000 Methods, systems, and apparatus, including computer programs encoded on computer storage media, for fine-tuning a generative neural network. For example, the system can fine-tune the generative neural network to more effectively generate data items that have a target property.
Nº publicación: US20260111703A1 23/04/2026
Solicitante:
CCTEG CHONGQING RES INSTITUTE [CN]
Resumen de: US20260111703A1
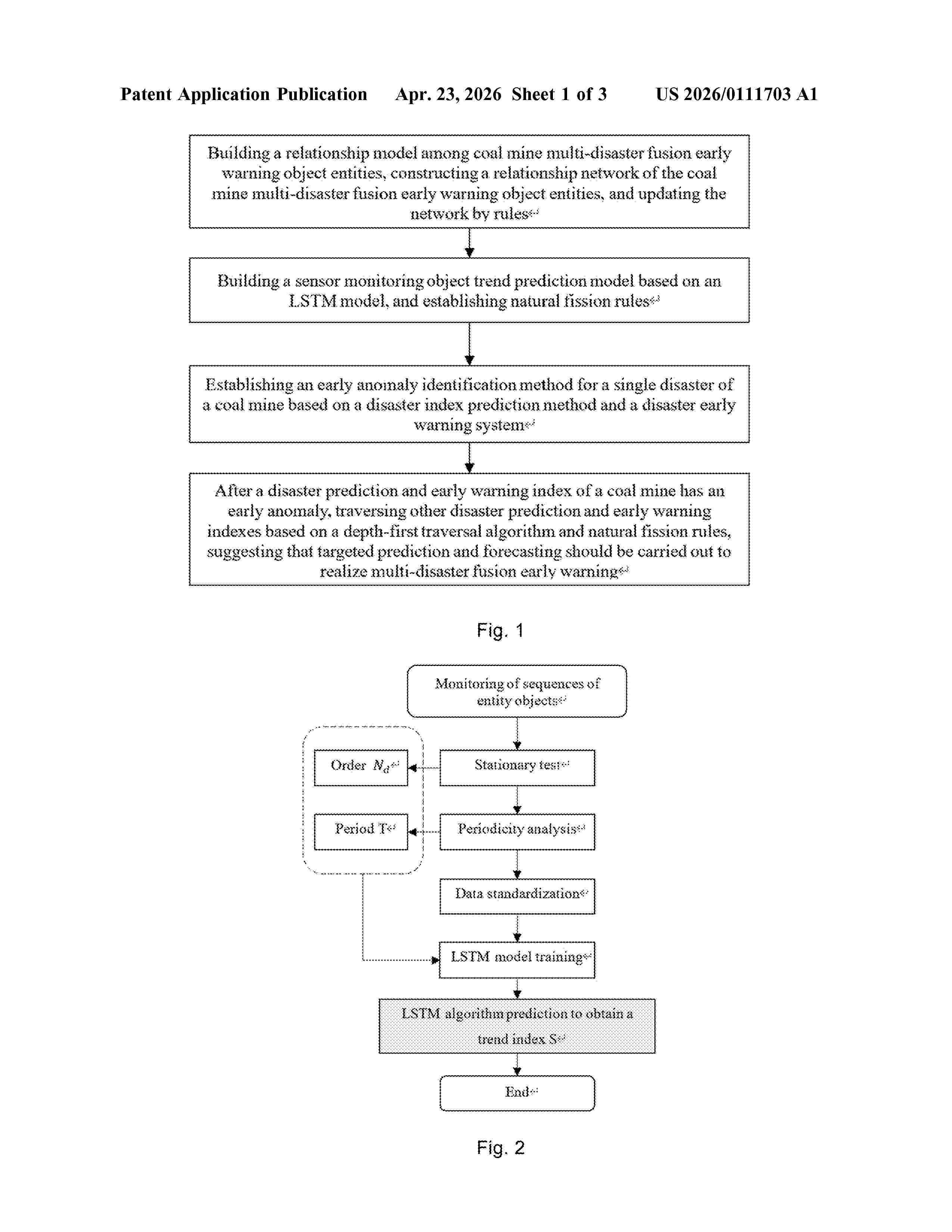
The present invention discloses a coal mine multi-disaster fusion early warning method and system, applicable in coal mine safety disaster analysis. First, it builds a model and relationship network among multi-disaster early warning entities, updating the network by specific rules. A trend prediction model using an LSTM artificial neural network is then developed for monitoring object trends, along with natural fission analysis rules. Next, a method for identifying anomalies in single disaster events is established through a disaster index prediction and early warning system. Upon detecting an anomaly in an early warning index, other disaster indexes are assessed using a depth-first traversal algorithm and natural fission rules, facilitating targeted forecasting. This invention builds a predictive relationship chain among early warning indexes through correlation analysis, providing advantages in multi-dimensional analysis and advanced trend prediction.
 BOPI
BOPI
 Sede Electrónica
Sede Electrónica