Si deseas distinguir tus productos, servicios o ambos de los de otra empresa, es posible que necesites una marca o nombre comercial. Descubre qué son, en qué consiste su procedimiento de registro y qué implica.

Información sobre los plazos de presentación de solicitudes de transformación de marcas de la Unión Europea en marca nacional española. Más información


Si tienes un nuevo dispositivo, producto o procedimiento que resuelva un problema técnico o tenga una ventaja práctica, existen distintas formas de protegerlo en España y en otros países. Descubre cómo hacerlo.

¿Tu innovación reside en la estética, la ornamentación o la apariencia de tu producto? Protégela mediante un diseño industrial. Descubre qué derechos confiere el registro y cómo realizar la tramitación.

Las patentes publicadas en todo el mundo son una valiosa fuente de información científica, técnica y comercial.
El Bono 3 (patentes nacionales, patentes europeas, informes tecnológicos de patentes y búsquedas retrospectivas) se encuentra cerrado desde el 19 de junio. La solicitud de ayudas para los Bonos 1, 2 y 4 permanecen abiertos.

Si eres emprendedor/a o una empresa y quieres potenciar y mejorar la rentabilidad de tu negocio protegiendo de forma adecuada los activos intangibles de tu organización, en este espacio encontrarás lo necesario.



 55
resultados
55
resultados
 Última actualización
06/08/2025 [07:07:00]
Última actualización
06/08/2025 [07:07:00]


Resumen de: US2025245050A1
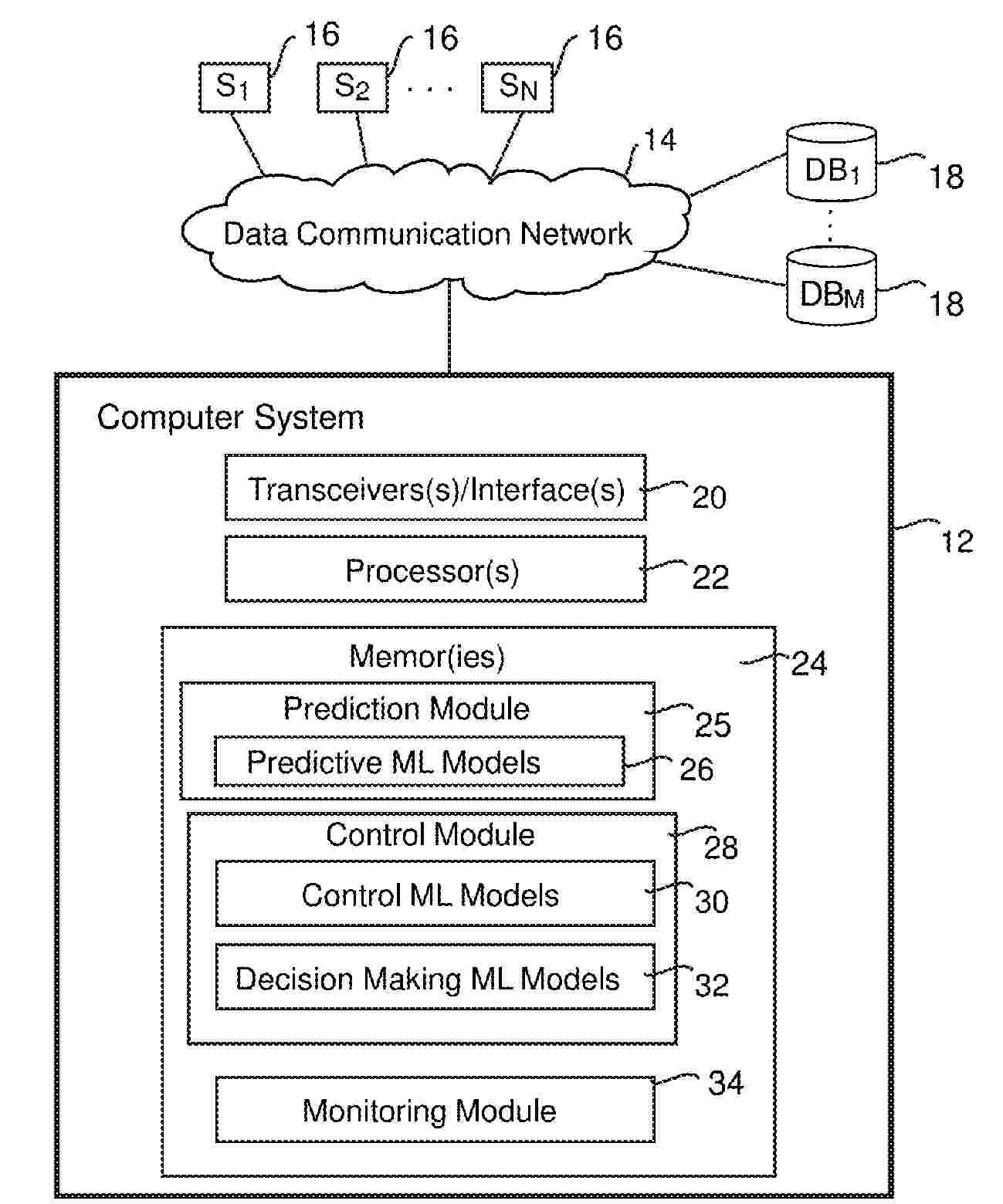
A computer system includes a transceiver that receives over a data communications network different types of input data from multiple source nodes and a processing system that defines for each of multiple data categories, a set of groups of data objects for the data category based on the different types of input data. Predictive machine learning model(s) predict a selection score for each group of data objects in the set of groups of data objects for the data category for a predetermined time period. Control machine learning model(s) determine how many data objects are permitted for each group of data objects based on the selection score. Decision-making machine learning model(s) prioritize the permitted data objects based on one or more predetermined priority criteria. Subsequent activities of the computer system are monitored to calculate performance metrics for each group of data objects and for data objects actually selected during the predetermined time period. Predictive machine learning model(s) and decision-making machine learning model(s) are adjusted based on the performance metrics to improve respective performance(s).

Resumen de: US2025245533A1
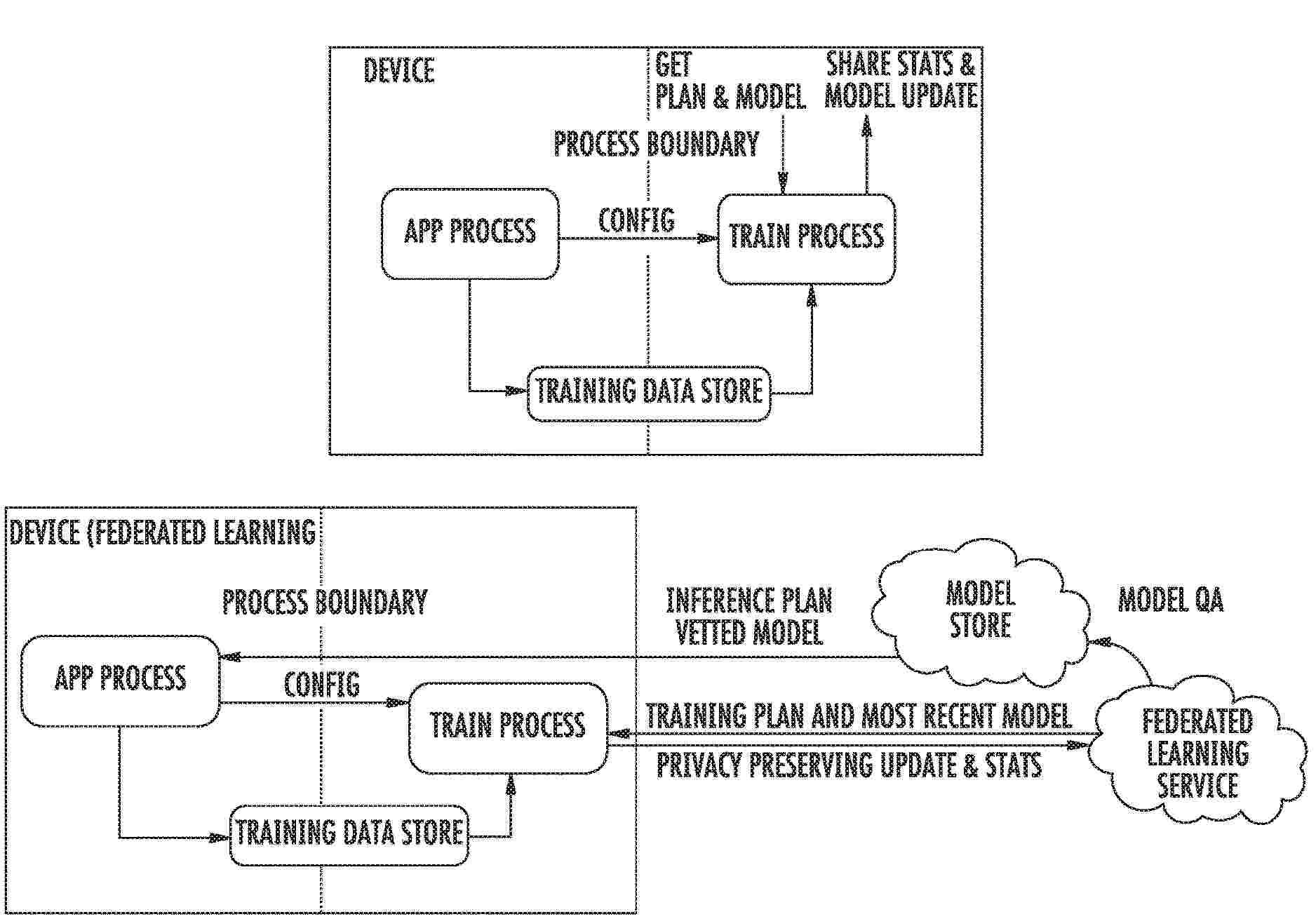
The present disclosure provides systems and methods for on-device machine learning. In particular, the present disclosure is directed to an on-device machine learning platform and associated techniques that enable on-device prediction, training, example collection, and/or other machine learning tasks or functionality. The on-device machine learning platform can include a context provider that securely injects context features into collected training examples and/or client-provided input data used to generate predictions/inferences. Thus, the on-device machine learning platform can enable centralized training example collection, model training, and usage of machine-learned models as a service to applications or other clients.
Resumen de: US2025245532A1
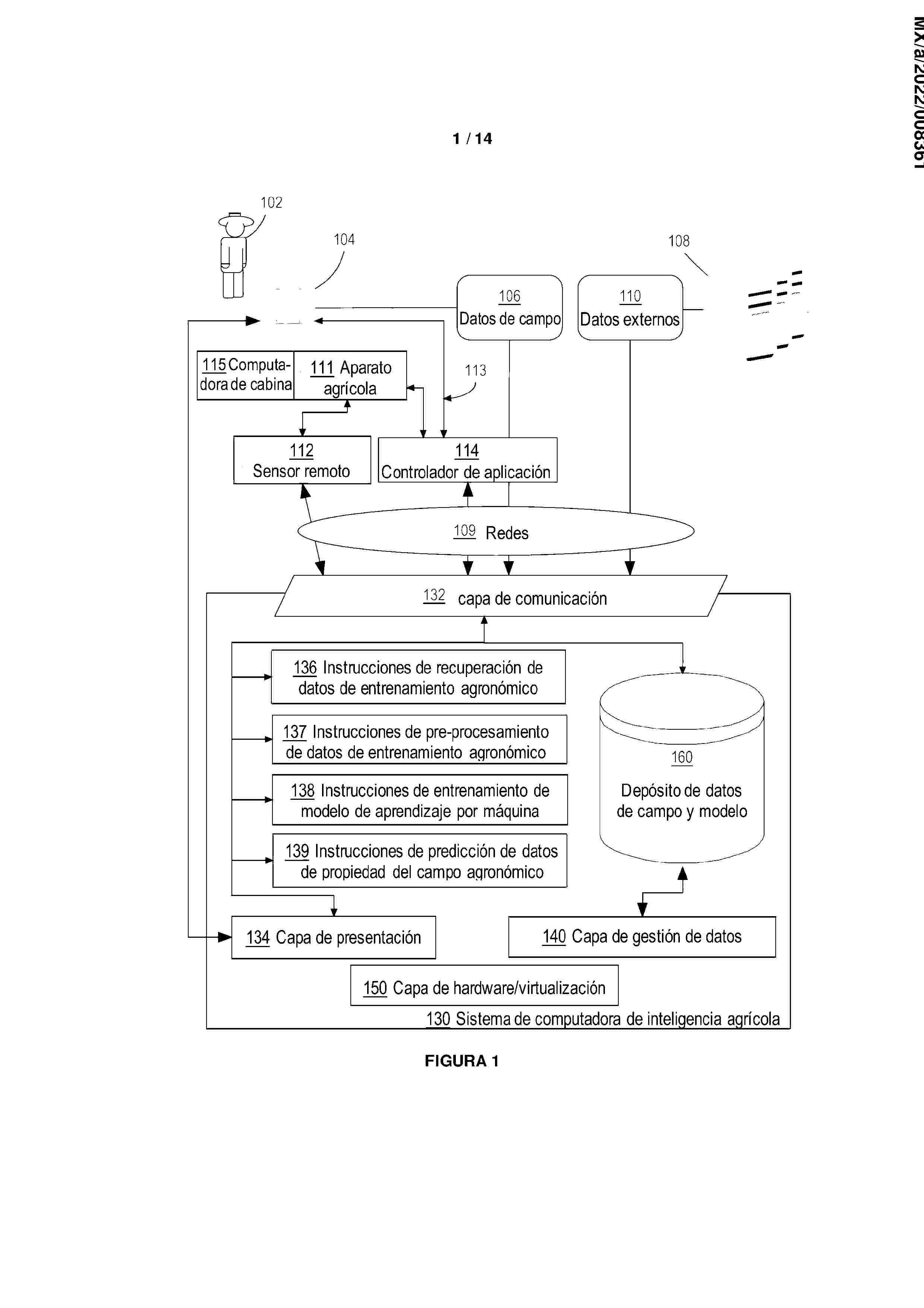
In some embodiments, a computer-implemented method for predicting agronomic field property data for one or more agronomic fields using a trained machine learning model is disclosed. The method comprises receiving, at an agricultural intelligence computer system, agronomic training data; training a machine learning model, at the agricultural intelligence computer system, using the agronomic training data; in response to receiving a request from a client computing device for agronomic field property data for one or more agronomic fields, automatically predicting the agronomic field property data for the one or more agronomic fields using the machine learning model configured to predict agronomic field property data; based on the agronomic field property data, automatically generating a first graphical representation; and causing to display the first graphical representation on the client computing device.
Resumen de: US2025245530A1
Certain aspects of the present disclosure provide techniques and apparatus for generating a response to a query input in a generative artificial intelligence model using variable draft length. An example method generally includes determining (e.g., measuring or accessing) one or more operational properties of a device on which inferencing operations using a machine learning model are performed. A first draft set of tokens is generated using the machine learning model. A number of tokens included in the first draft set of tokens is based on the one or more operational properties of the device and a defined scheduling function for the machine learning model. The first draft set of tokens are output for verification.
Resumen de: US2025245553A1
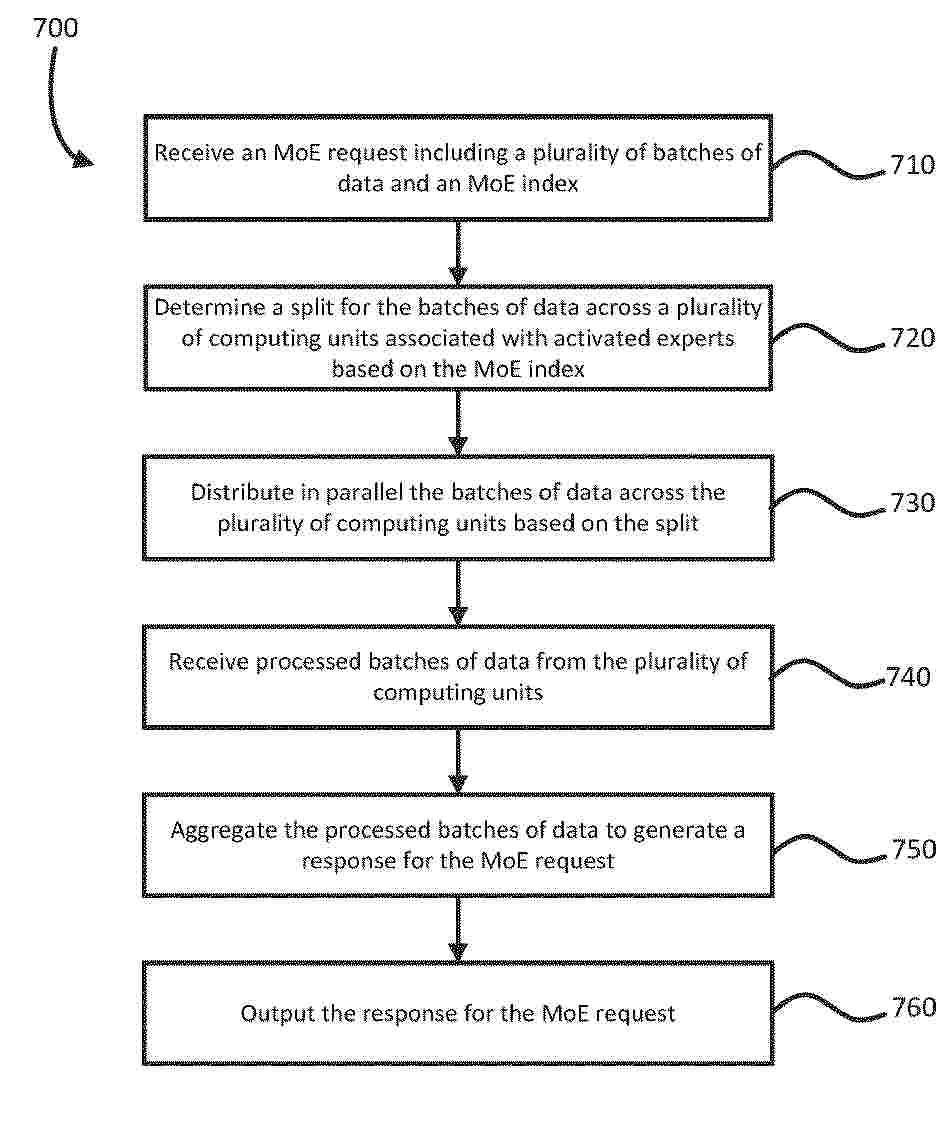
Aspects of the disclosure are directed to improving load balancing for serving mixture of experts (MoE) machine learning models. Load balancing is improved by providing memory dies increased access to computing dies through a 2.5D configuration and/or an optical configuration. Load balancing is further improved through a synchronization mechanism that determines an optical split of batches of data across the computing die based on a received MoE request to process the batches of data. The 2.5D configuration and/or optical configuration as well as the synchronization mechanism can improve usage of the computing die and reduce the amount of memory dies required to serve the MoE models, resulting in less consumption of power and lower latencies and complexity in alignment associated with remotely accessing memory.
Resumen de: WO2025159880A1
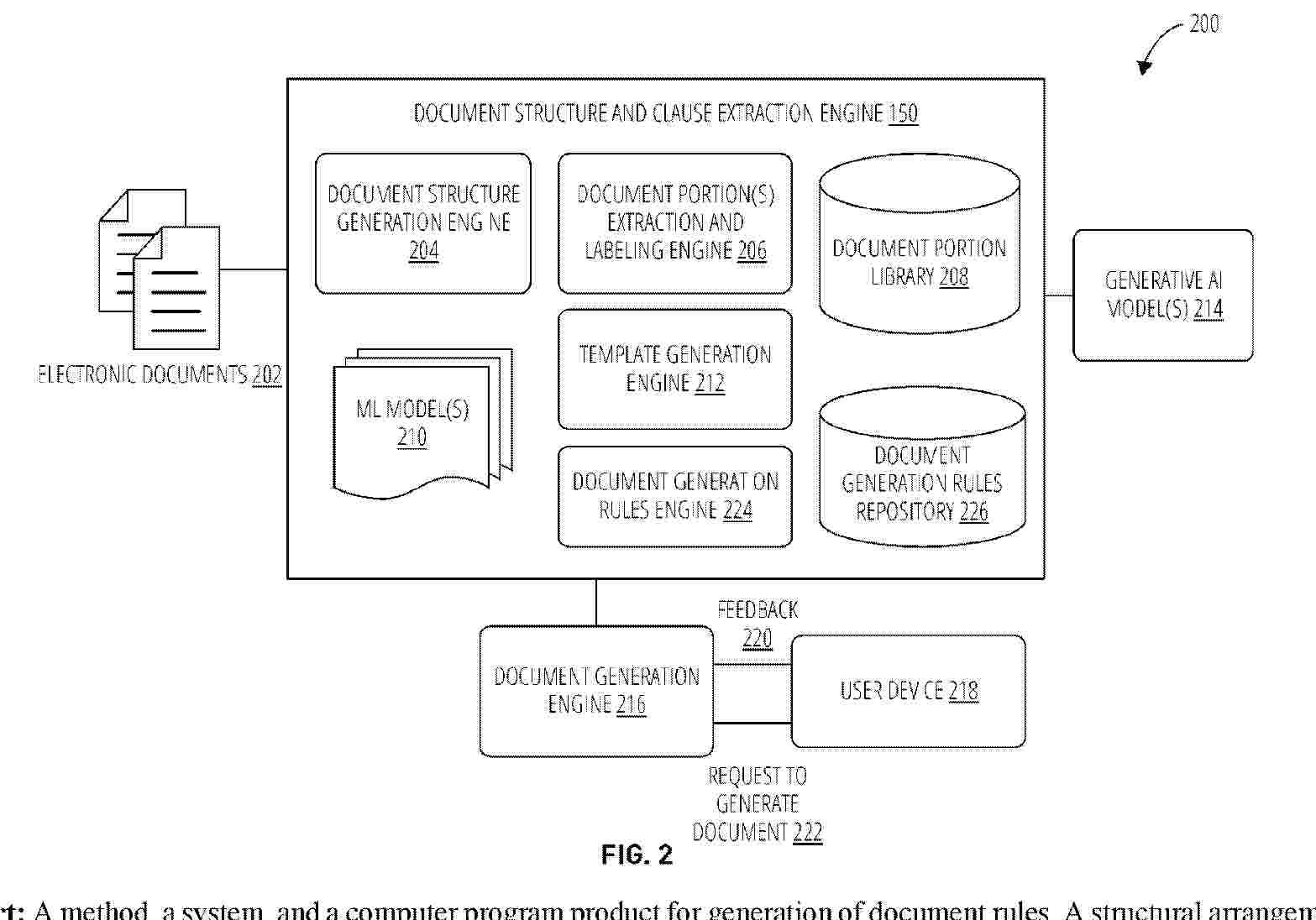
A method, a system, and a computer program product for generation of document rules. A structural arrangement of one or more portions of each electronic document in a plurality of electronic documents is determined using one or more machine learning models. One or more parameters associated with each electronic document in the plurality of electronic documents are identified. One or more document generation rules are generated based on one or more parameters and the structural arrangement of one or more portions. One or more document generation rules are generated for each type of electronic document in the plurality of electronic documents. One or more document generation rules are stored in a storage location.
Resumen de: WO2025159758A1
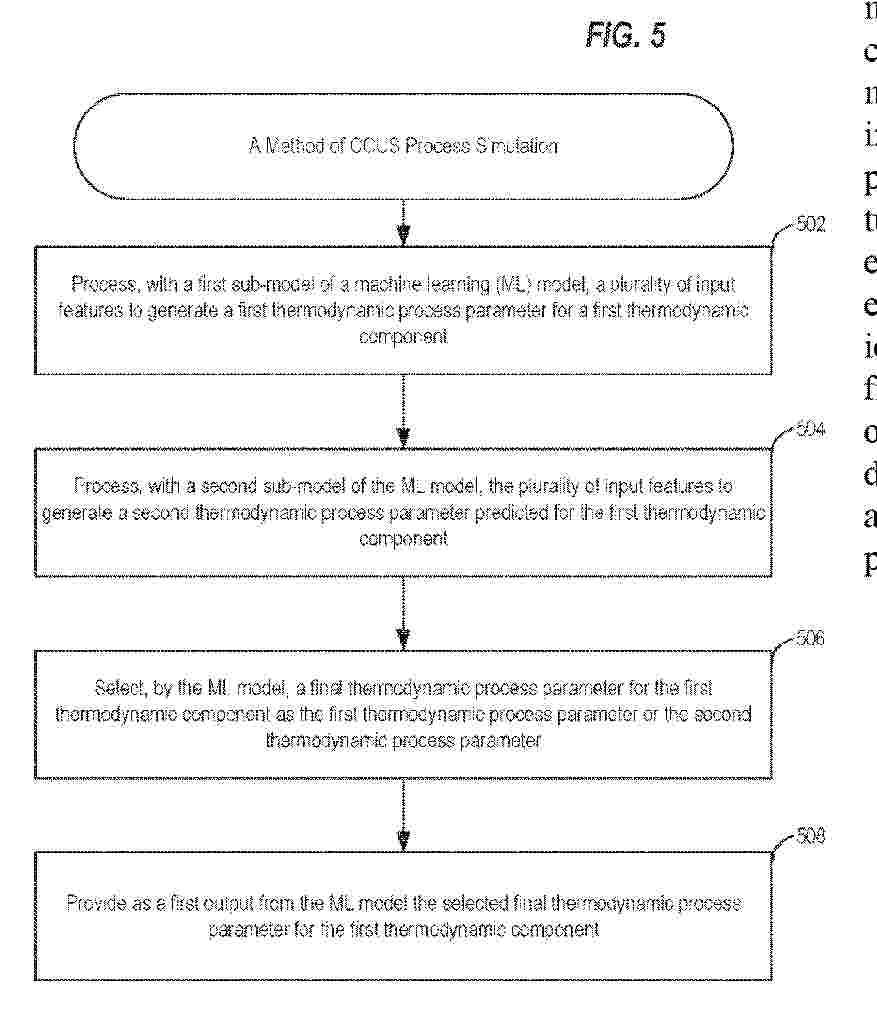
Certain aspects of the disclosure provide a method for carbon capture, utilization, and storage (CCUS) process simulation. The method generally includes processing, with a first sub-model of a machine learning (ML) model, input features to generate a first thermodynamic process parameter for a first thermodynamic component, wherein the input features comprise one or more thermodynamic properties; processing, with a second sub-model of the ML model, the input features to generate a second thermodynamic process parameter predicted for the first thermodynamic component; selecting, by the ML model, a final thermodynamic process parameter for the first thermodynamic component as: the first thermodynamic process parameter when the first thermodynamic process parameter is greater than a first threshold; or the second thermodynamic process parameter when the first thermodynamic process parameter is less than the first threshold; and providing as a first output from the ML model the selected final thermodynamic process parameter.
Resumen de: WO2025159979A1
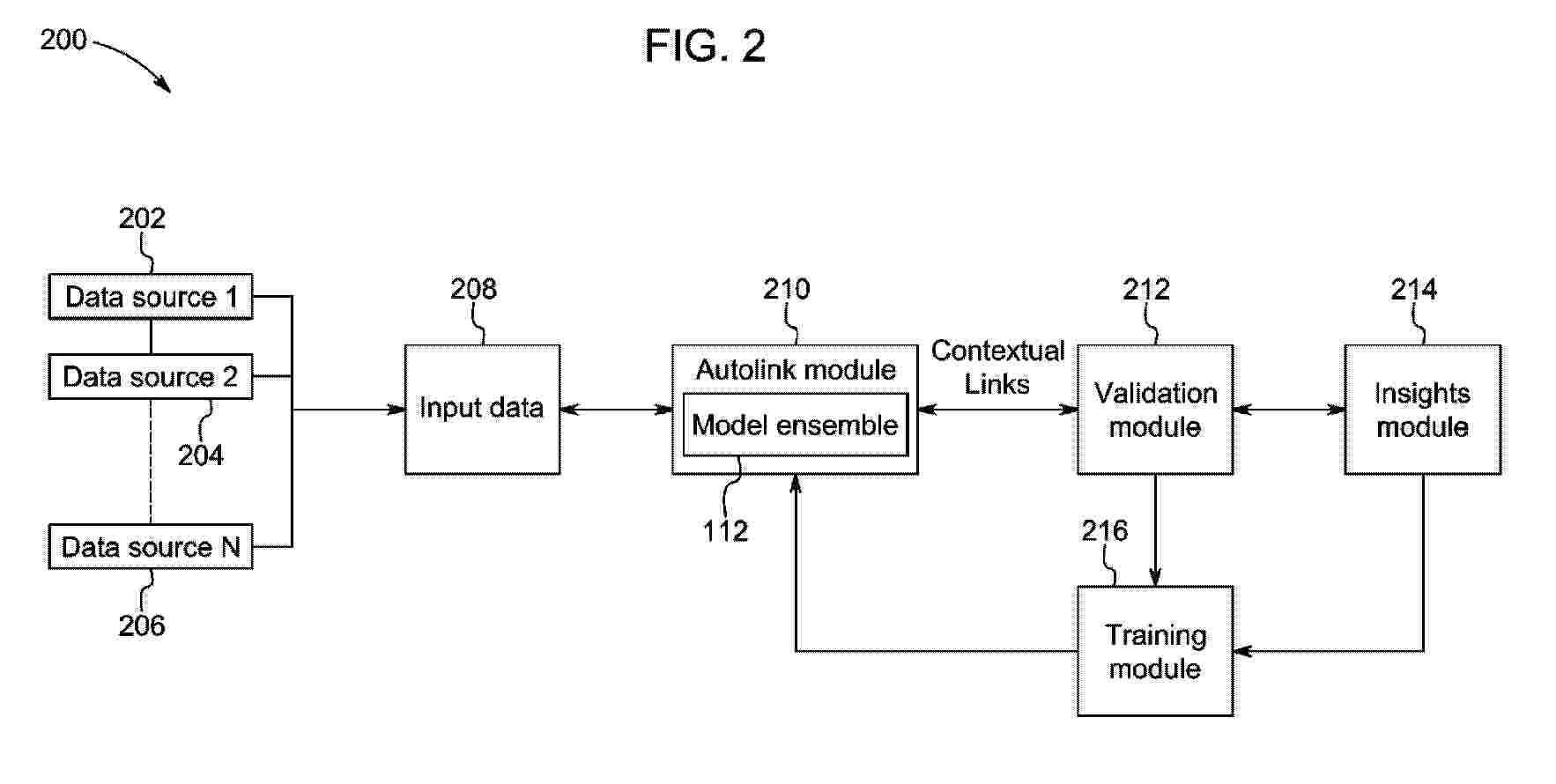
A method for establishing and generating contextual links between data from a plurality of data sources is described. The method includes receiving data and decomposing the received data into a decomposed data set; parsing and analyzing the decomposed data set based on a set of attribute analyzers to associate one or more attributes to the decomposed data set; determining an intent of data from the decomposed data set; generating a semantic graph of the decomposed data set based on the intent of data to evaluate data relatability between the decomposed data set; generating atomic knowledge units (AMUs) based on the parsed decomposed data set and the semantic graph; analyzing the AMUs corresponding to the received data by applying trained machine learning models to generate links between the AMUs and processing the generated links by a model ensemble to establish contextual links between data.
Resumen de: WO2025159851A1
A method for rules-based modeling may include capturing a plurality of historical transaction data of a client account. The method may further include extracting a plurality of item level features from the plurality of historical transaction data. The method may further include providing the plurality of item level features to a predictive machine-learning model. The predictive machine-learning model may be trained to identify patterns within the plurality of item level features and generate a projected balance for the client account based on the identified patterns. The method may further include transmitting the projected balance to a user interface.
Resumen de: WO2025157774A1
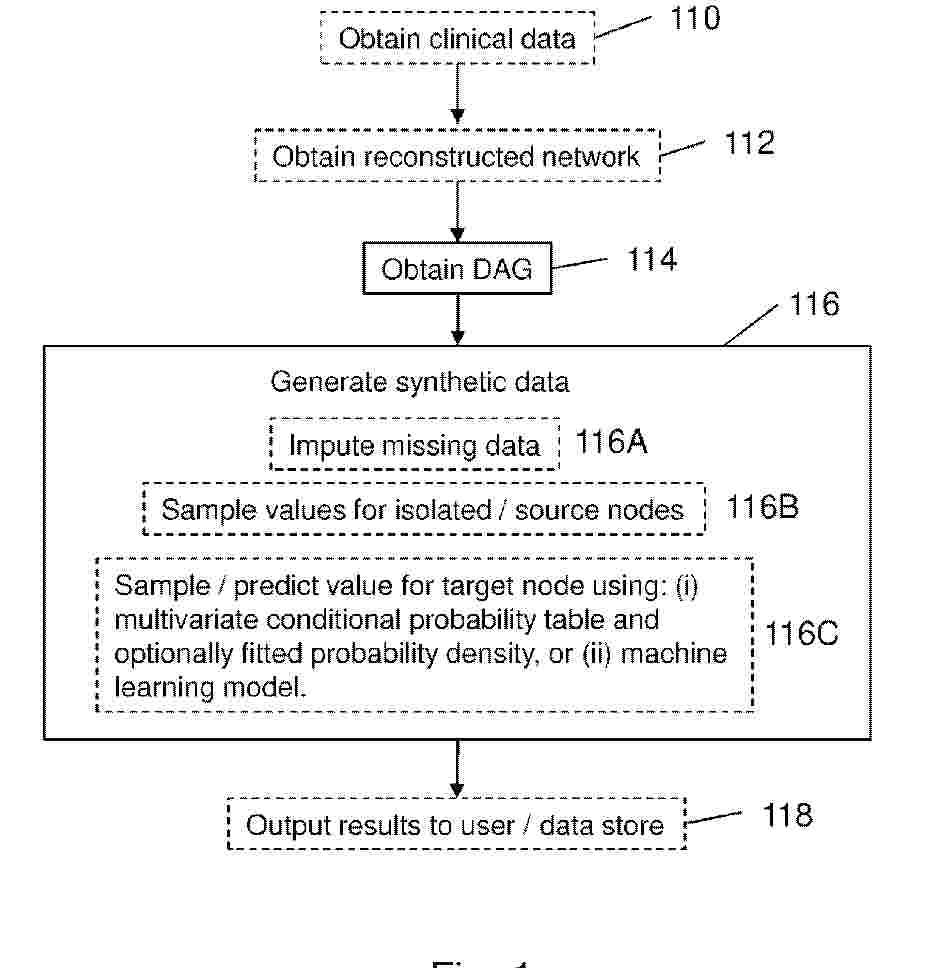
Computer-implemented methods of providing a clinical predictor tool are described, comprising: obtaining training data comprising, for each of a plurality of patients, values for a plurality of clinical variables comprising a variable indicative of a diagnosis or prognosis and one or more further clinical variables; and training a clinical predictor model to predict the variable indicative of a diagnosis or prognosis using said training data, wherein obtaining the training data comprises obtaining synthetic clinical data comprising values for a plurality of clinical variables for one or more patients by obtaining a directed acyclic graph (DAG) edges corresponding to conditional dependence relationships inferred from real clinical data comprising values for the plurality of clinical variables for a plurality of patients, and obtaining values for each node of the DAG using a machine learning model and multivariate conditional probability table. Computer-implemented methods of obtaining synthetic clinical data are also described.
Resumen de: WO2025156057A1
Systems and methods for fine-tuning a machine learning model for use in patent analytics and infringement system are disclosed herein. The method involves providing, in a memory, a litigation dataset comprising a plurality of historical patent litigation records, each patent litigation record comprising at least one patent claim, and a litigation outcome corresponding to each of the at least one patent claim; receiving, at a processor in communication with the memory, a product/service content item associated with a candidate patent litigation record in the plurality of historical patent litigation records; updating, at the processor, the candidate patent litigation record based on the product/service content item; and generating, at the processor, a vector database based on the litigation dataset, the vector database used to fine-tune a machine learning model. Systems and methods for identifying products and services relevant to a patent claim and for ranking results are also described.
Resumen de: WO2024081965A1
An online system trains a constraint prediction machine-learning model using an action-based loss function. The action-based loss function computes a weighted sum of (1) an accuracy of the constraint prediction model in predicting whether a user's interaction complies with a set of constraints and (2) an action score representing a number of actions taken by users to determine whether the user's action complies with the set of constraints. The online system may apply this trained constraint prediction model to future interaction data received from third-party systems to predict whether user interactions with those third-party systems comply with the set of constraints.
Resumen de: US2024104370A1
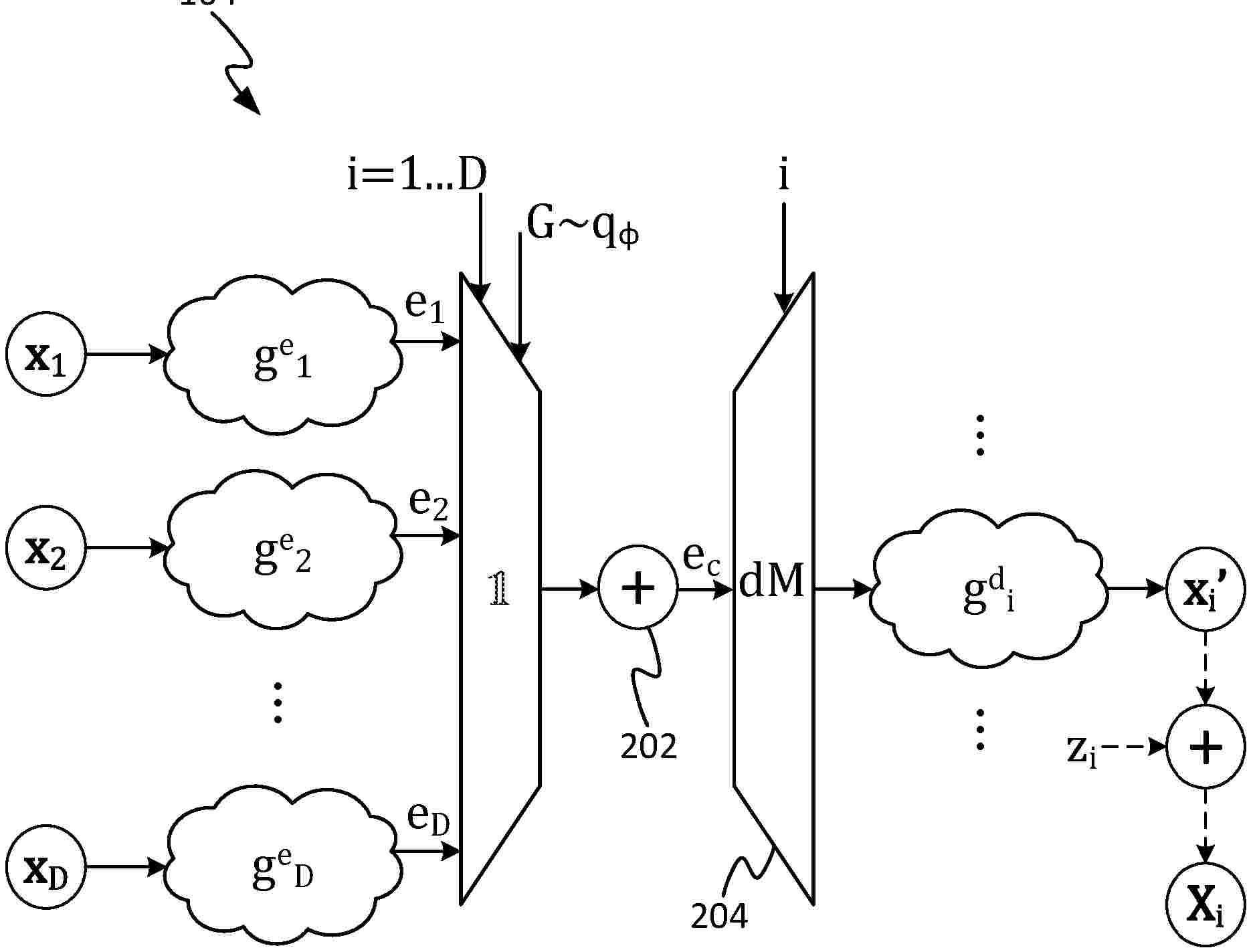
A method comprising: sampling a first causal graph from a first graph distribution modelling causation between variables in a feature vector, and sampling a second causal graph from a second graph distribution modelling presence of possible confounders, a confounder being an unobserved cause of both of two variables. The method further comprises: identifying a parent variable which is a cause of a selected variable according to the first causal graph, and which together with the selected variable forms a confounded pair having a respective confounder being a cause of both according to the second causal graph. A machine learning model encodes the parent to give a first embedding, and encodes information on the confounded pair give a second embedding. The embeddings are combined and then decoded to give a reconstructed value. This mechanism may be used in training the model or in treatment effect estimation.
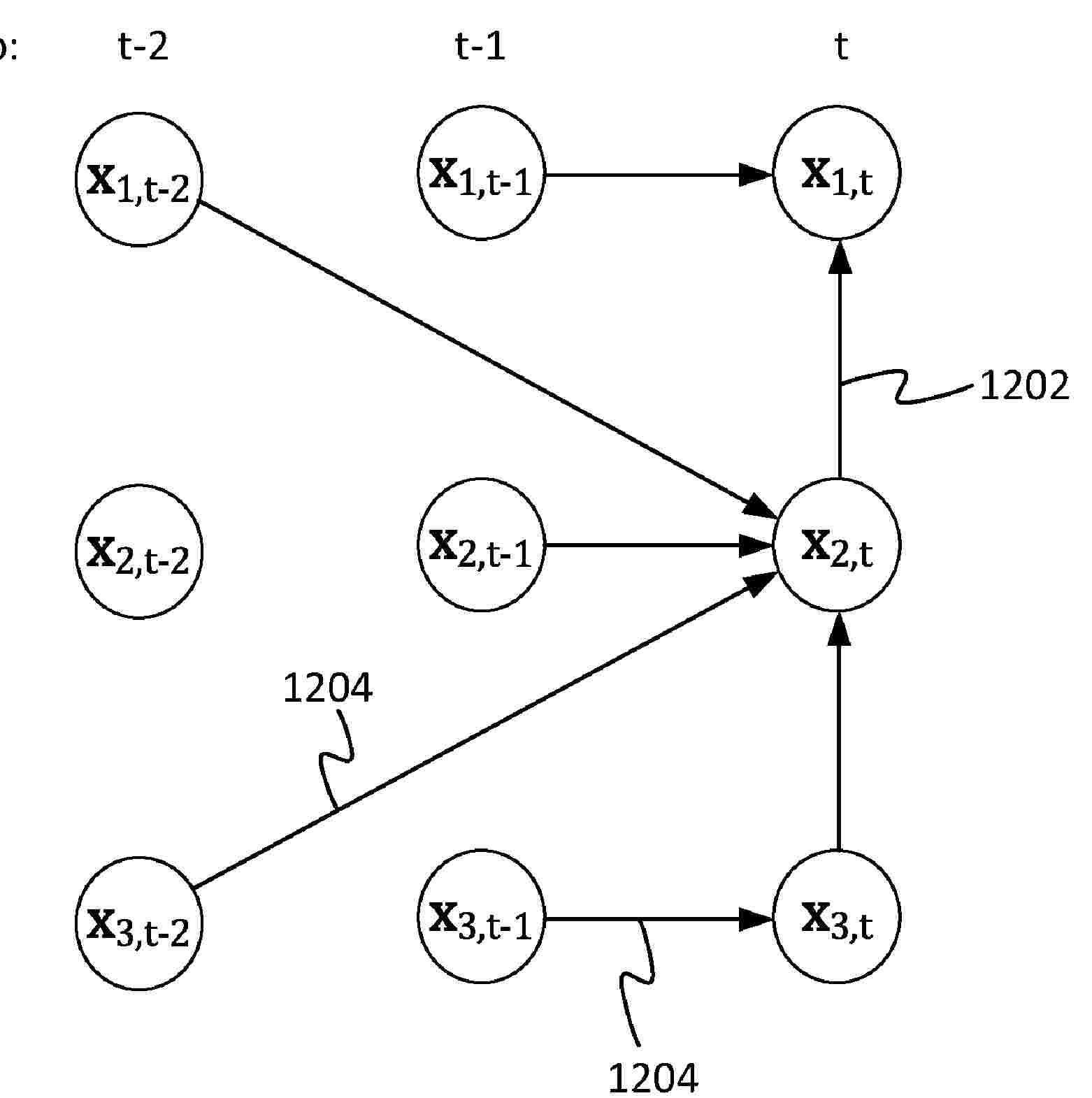
Resumen de: US2024104338A1
A method comprising: sampling a temporal causal graph from a temporal graph distribution specifying probabilities of directed causal edges between different variables of a feature vector at a present time step, and from one variable at a preceding time step to another variables at the present time step. Based on this there are identified: a present parent which is a cause of the selected variable in the present time step, and a preceding parent which is a cause of the selected variable from the preceding time step. The method then comprises: inputting a value of each identified present and preceding parent into a respective encoder, resulting in a respective embedding of each of the present and preceding parents; combining the embeddings of the present and preceding parents, resulting in a combined embedding; inputting the combined embedding into a decoder, resulting in a reconstructed value of the selected variable.
Resumen de: WO2024112887A1
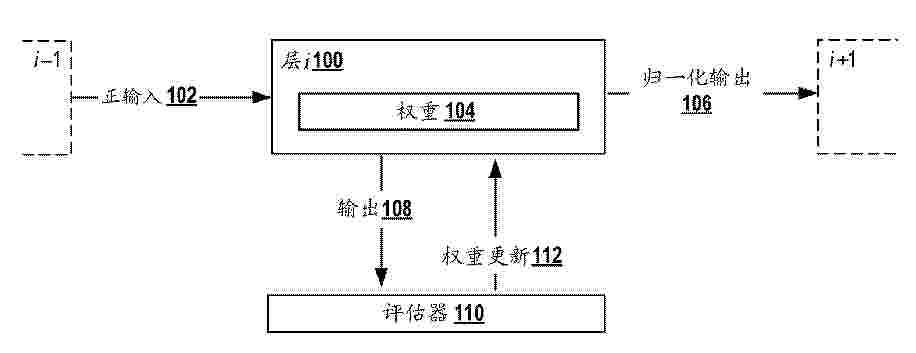
Example implementations provide a computer-implemented method for training a machine-learned model, the method comprising: processing, using a layer of the machine-learned model, positive input data in a first forward pass; updating one or more weights of the layer to adjust, in a first direction, a goodness metric of the layer for the first forward pass; processing, using the layer, negative input data in a second forward pass; and updating the one or more weights to adjust, in a second direction, the goodness metric of the layer for the second forward pass.
Resumen de: EP4592895A1
Aspects of the disclosure are directed to improving load balancing for serving mixture of experts (MoE) machine learning models. Load balancing is improved by providing memory dies increased access to computing dies through a 2.5D configuration and/or an optical configuration. Load balancing is further improved through a synchronization mechanism that determines an optical split of batches of data across the computing die based on a received MoE request to process the batches of data. The 2.5D configuration and/or optical configuration as well as the synchronization mechanism can improve usage of the computing die and reduce the amount of memory dies required to serve the MoE models, resulting in less consumption of power and lower latencies and complexity in alignment associated with remotely accessing memory.
Resumen de: US2025239253A1
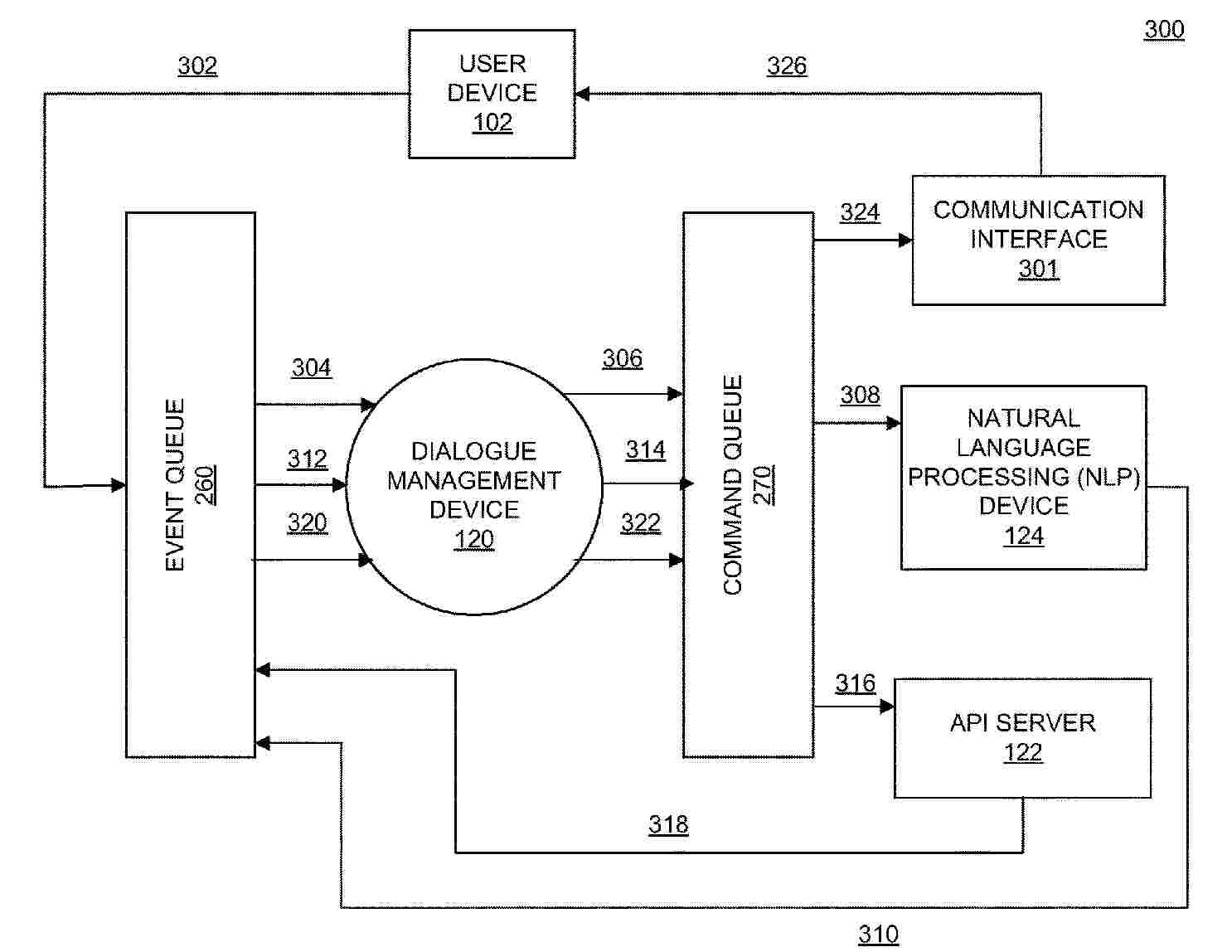
A system includes one or more memory devices storing instructions, and one or more processors configured to execute the instructions to perform steps of providing automated natural dialogue with a customer. The system may generate one or more events and commands temporarily stored in queues to be processed by one or more of a dialogue management device, an API server, and an NLP device. The dialogue management device may create adaptive responses to customer communications using a customer context, a rules-based platform, and a trained machine learning model.
Resumen de: US2025238596A1
Systems and methods are disclosed for manually and programmatically remediating websites to thereby facilitate website navigation by people with diverse abilities. For example, an administrator portal is provided for simplified, form-based creation and deployment of remediation code, and a machine learning system is utilized to create and suggest remediations based on past remediation history. Voice command systems and portable document format (PDF) remediation techniques are also provided for improving the accessibility of such websites.
Resumen de: US2025238280A1
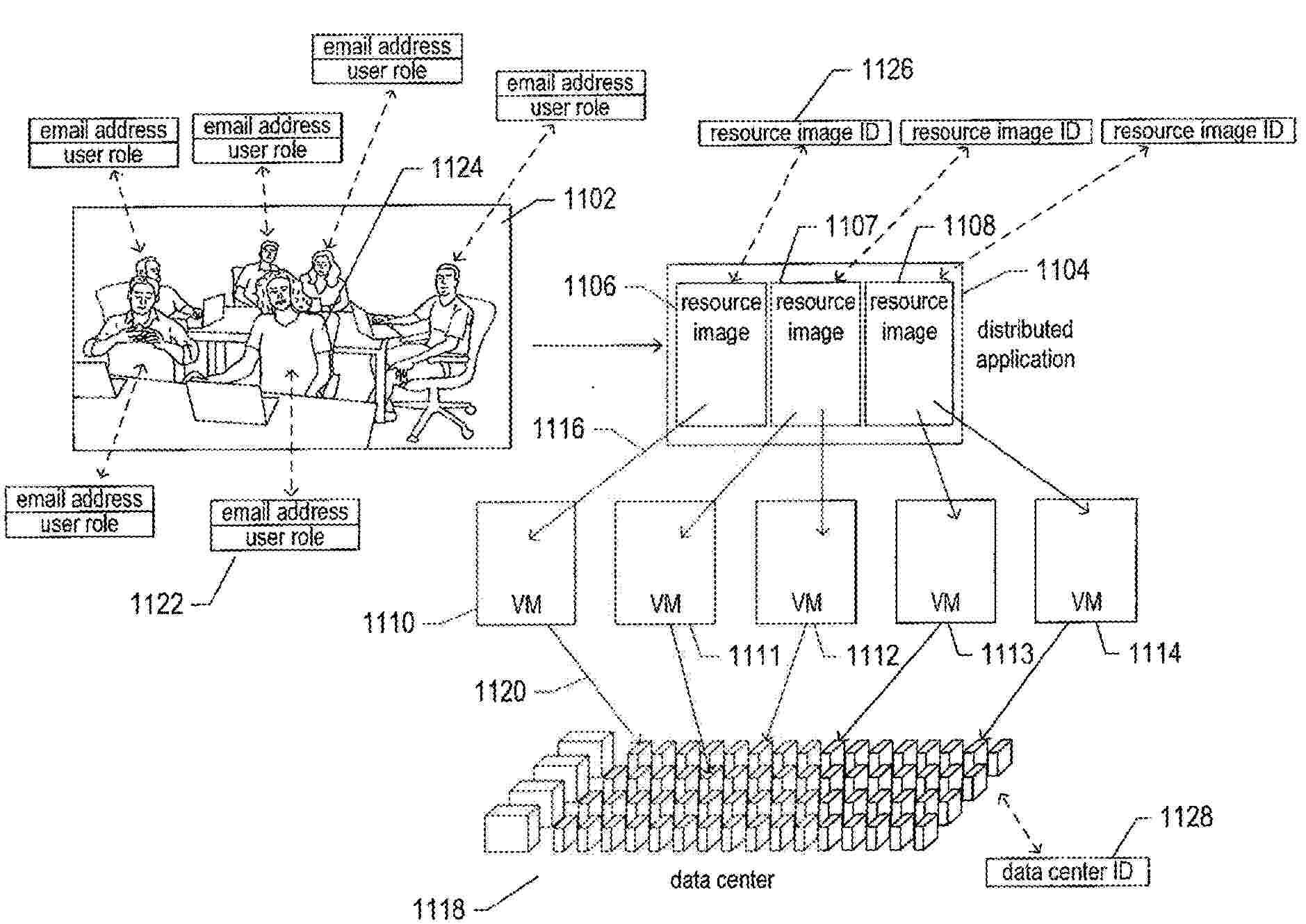
The current document is directed to methods and systems that generate recommendations for resource specifications used in virtual-machine-hosting requests. When distributed applications are submitted to distributed-computer-system-based hosting platforms for hosting, the hosting requestor generally specifies the computational resources that will need to be provisioned for each virtual machine included in a set of virtual machines that correspond to the distributed application, such as the processor bandwidth, memory size, local and remote networking bandwidths, and data-storage capacity needed for supporting execution of each virtual machine. In many cases, the hosting platform reserves the specified computational resources and accordingly charges for them. However, in many cases, the specified computational resources significantly exceed the computational resources actually needed for hosting the distributed application. The currently disclosed methods and systems employ machine learning to provide accurate estimates of the computational resources for the VMs of a distributed application.
Resumen de: US2025239366A1
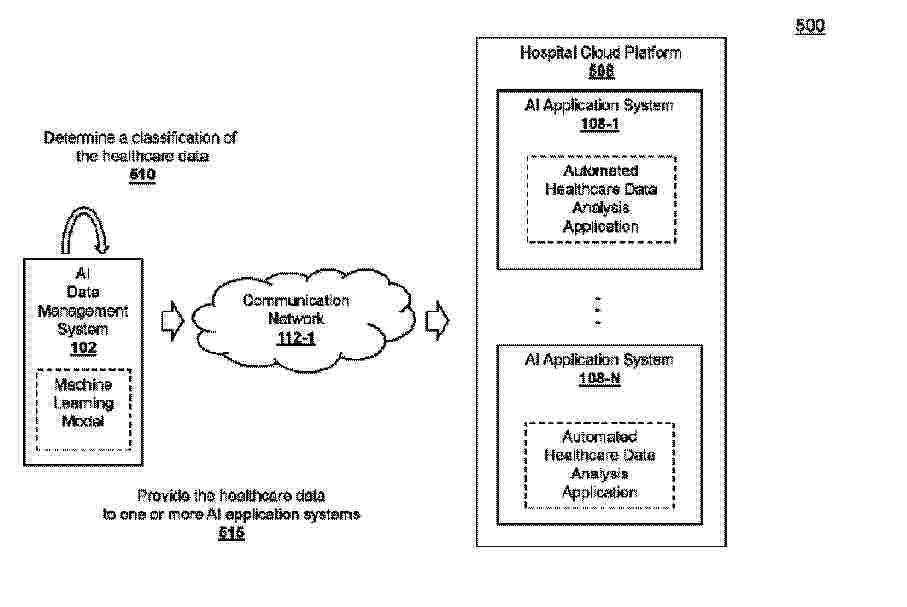
Provided is a system for managing automated healthcare data applications using artificial intelligence (AI) that includes at least one processor programmed or configured to receive healthcare data from a data source, determine a classification of the healthcare data using a machine learning model, wherein the machine learning model is configured to provide a predicted classification of an automated healthcare data analysis application of a plurality of automated healthcare data analysis applications based on an input, and provide the healthcare data to an automated healthcare data analysis application based on the classification of the healthcare data. Methods and computer program products are also disclosed.
Resumen de: US2025240329A1
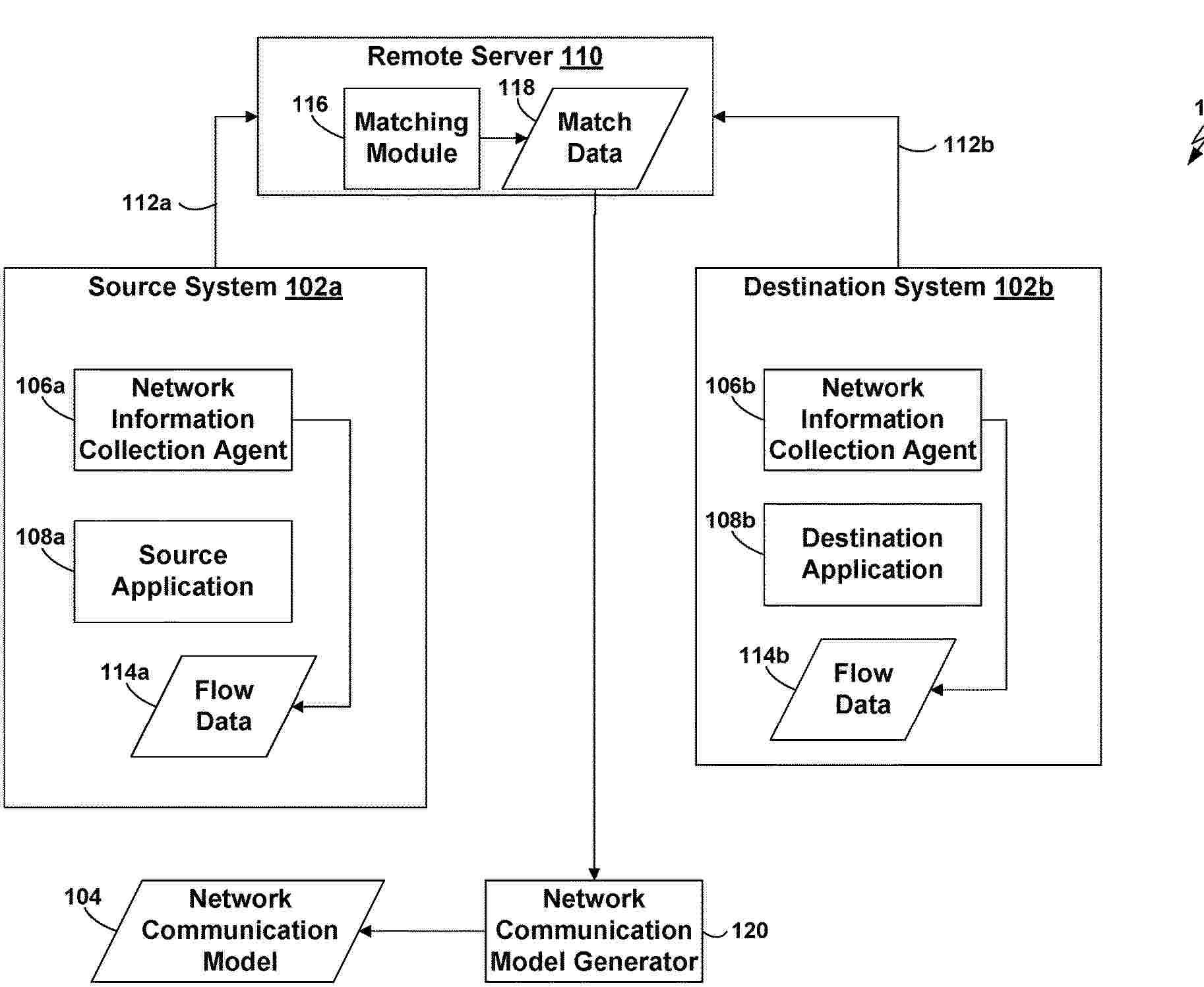
A method for automatically generating network communication policies employs unsupervised machine learning on unlabeled network data representing communications between applications on multiple computer systems. This approach uniquely derives policy rules without predefined labels or user-defined communication categories, ensuring automated rules complement existing user-generated policies by excluding them during training. The method validates network interactions by enforcing rules that leverage application fingerprints and identified feature clusters to distinguish permitted from prohibited communications. Additional techniques include dynamically adapting policies, utilizing decision trees, frequent itemset discovery, and evolutionary algorithms. Suspicious applications are flagged, and malicious data is excluded from training. The system uses aggregated flows, MapReduce processing, and simulated annealing optimization, providing human-readable, periodically retrained rules for balanced network security management.
Resumen de: US2025237131A1
Systems and methods presented herein include systems and methods for receiving data relating to an injection/falloff test performed in a well in fluid communication with a subterranean reservoir; determining operational parameters of a hydraulic fracturing operation using at least a portion of the data; applying the operational parameters to a pre-trained machine learning predictive model to determine an optimal set of control parameters; and issuing one or more commands relating to the control parameters to optimize the hydraulic fracturing operation on the subterranean reservoir.
Resumen de: US2025238720A1
A computer implemented method of managing a first model that was trained using a first machine learning process and is deployed and used to label medical data. The method comprises determining (202) a performance measure for the first model, and if the performance measure is below a threshold performance level, triggering (204) an upgrade process wherein the upgrade process comprises performing further training on the first model to produce an updated first model, wherein the further training is performed using an active learning process wherein training data for the further training is selected from a pool of unlabeled data samples, according to the active learning process, and sent to a labeler to obtain ground truth labels for use in the further training.
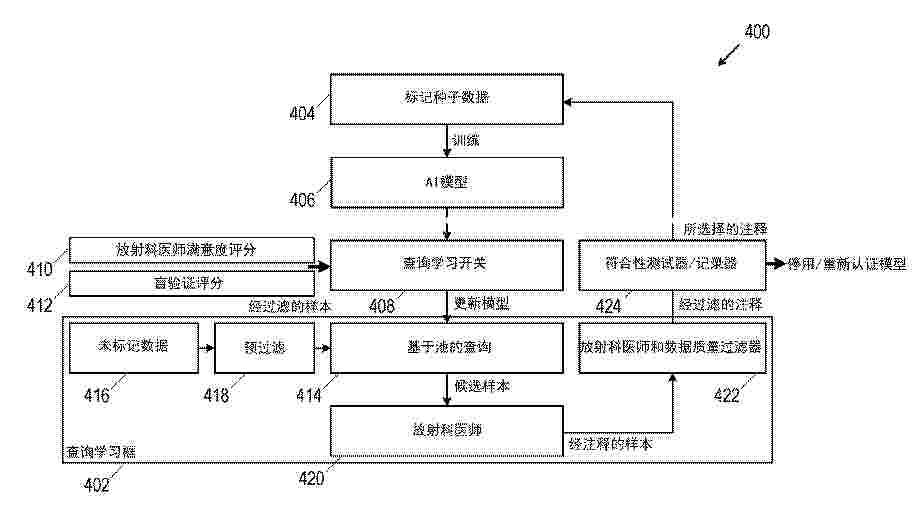
Resumen de: EP4589435A1
The present invention relates to a method, comprising: using an artificial intelligence/machine learning, AI/ML, model to map content between an interface of a first entity for interaction with other entities and an interface of a second entity for interaction with other entities, and/or classify content of the interface of the first entity and/or of the interface of the second entity; and obtaining, from the AI/ML model, a first output indicative of a result of the mapping of the content, and/or of a result of the classification of the content.
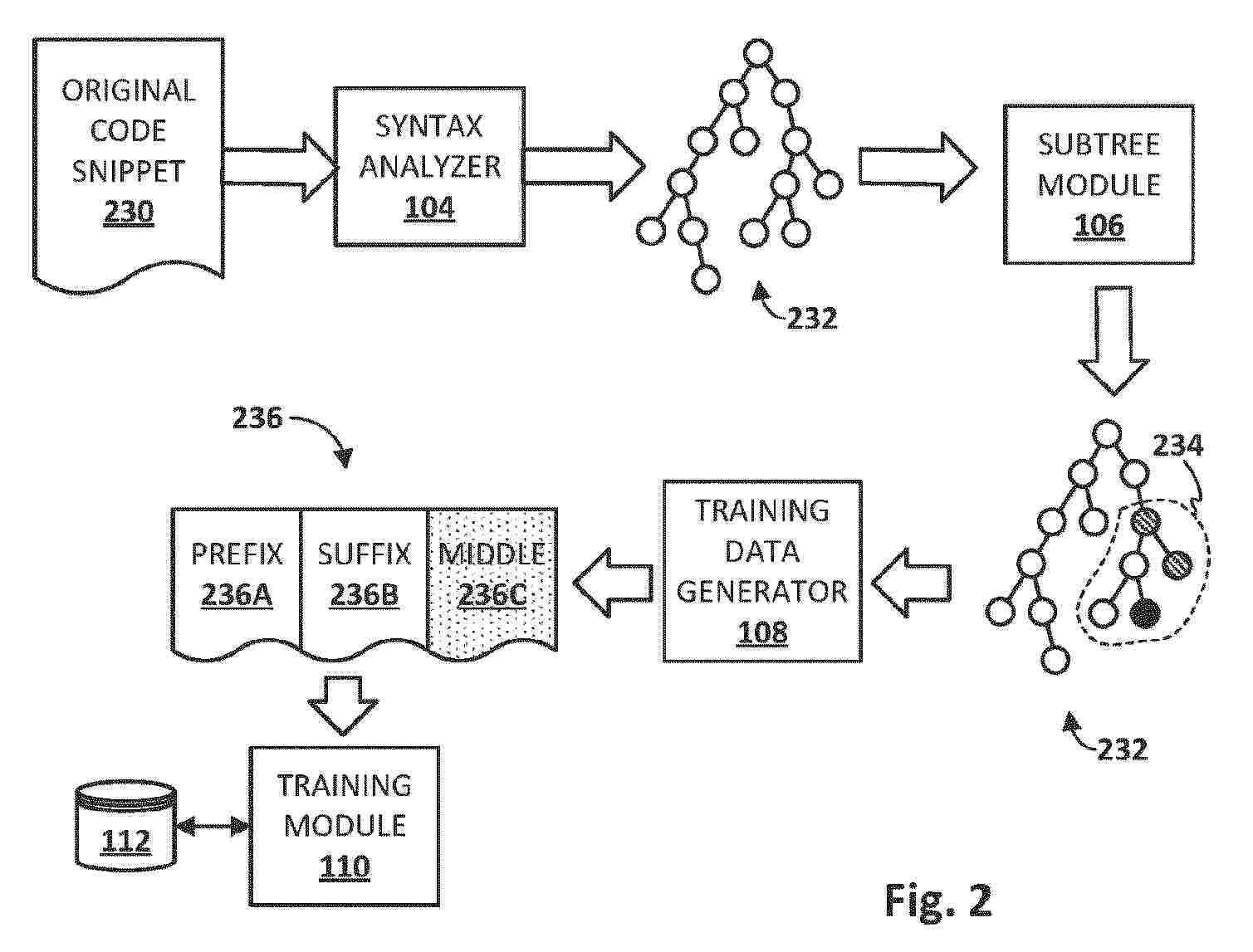
Resumen de: EP4589421A1
A method implemented using one or more processors comprises selecting a starting location in an original code snippet, processing the original code snippet to generate a tree representation of the original code snippet, identifying a subtree of the tree representation that contains the starting location in the original code snippet, identifying a ground truth portion of the original code snippet that corresponds to at least a portion of the subtree of the tree representation, and training a machine learning model to generate a predicted code snippet that corresponds to the portion of the subtree. The training includes processing a remainder of the original code snippet outside of the ground truth portion using the machine learning model.
Resumen de: US2025232323A1
A method, computer program product, and computer system for identifying, by a computing device, event specific data of a past media program. A size of delivery of a future media program may be predicted based upon, at least in part, the event specific data of the past media program. A financial media product may be generated based upon, at least in part, the predicted size of delivery of the future media program. An actual size of delivery may be identified. A first action may be executed if the actual size of delivery is greater than the predicted size of delivery based upon, at least in part, the financial media product. A second action may be executed if the actual size of delivery is less than the predicted size of delivery based upon, at least in part, the financial media product.
Resumen de: US2025232353A1
Systems and methods for generating synthetic data are disclosed. A system may include one or more memory devices storing instructions and one or more processors configured to execute the instructions. The instructions may instruct the system to categorize consumer data based on a set of characteristics. The instructions may also instruct the system to receive a first request to generate a first synthetic dataset. The first request may specify a first requirement for at least one of the characteristics. The instructions may further instruct the system to retrieve, from the consumer data, a first subset of the consumer data satisfying the first requirement. The instructions may also instruct the system to provide the first subset of consumer data as input to a data model to generate the first synthetic dataset, and to provide the first synthetic dataset as training data to a machine-learning system.
Resumen de: US2025232119A1
A method includes using an artificial intelligence/machine learning, AI/ML, model to map content between an interface of a first entity for interaction with other entities and an interface of a second entity for interaction with other entities, and/or classify content of the interface of the first entity and/or of the interface of the second entity; and obtaining, from the AI/ML model, a first output indicative of a result of the mapping of the content, and/or of a result of the classification of the content.
Resumen de: US2025232226A1
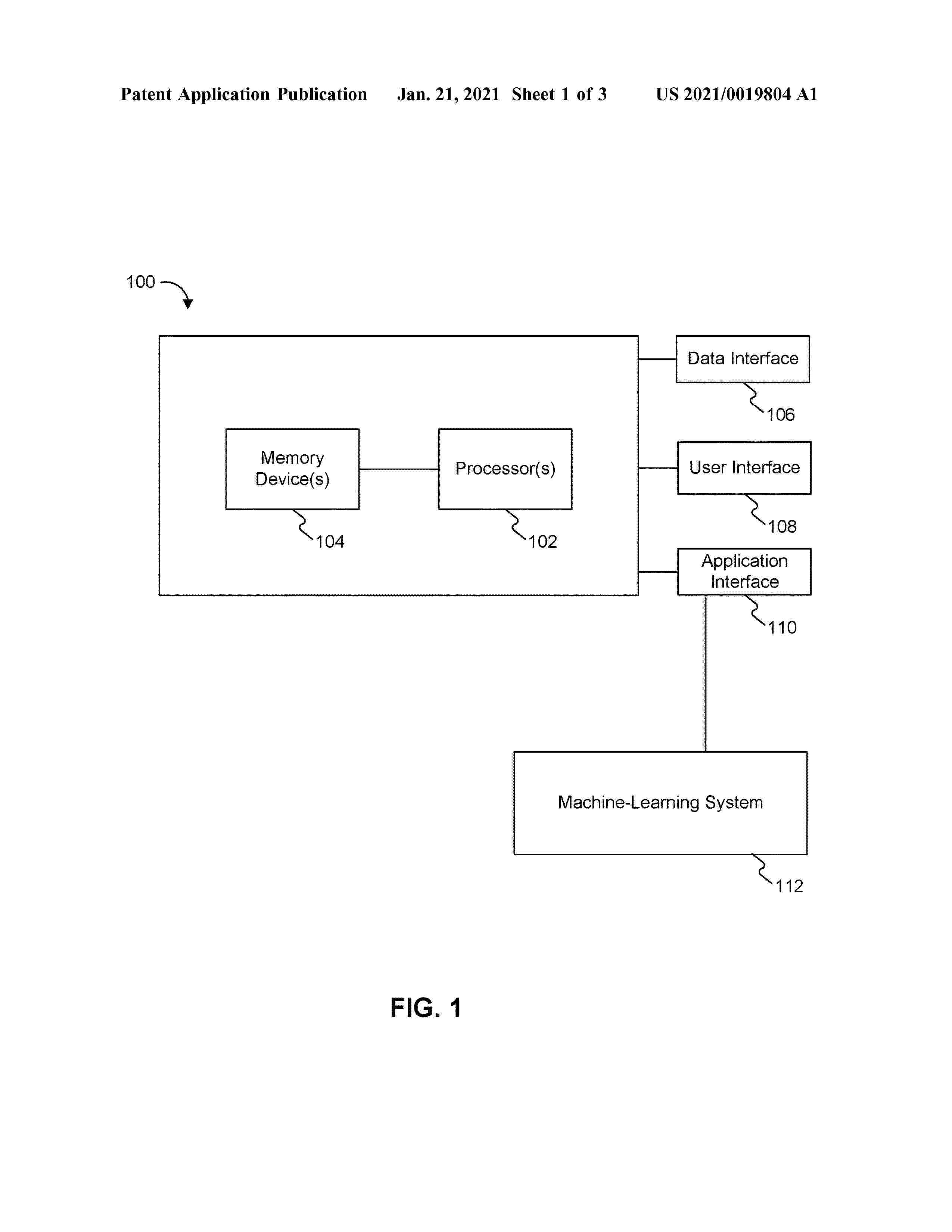
A provider network implements a machine learning deployment service for generating and deploying packages to implement machine learning at connected devices. The service may receive from a client an indication of an inference application, a machine learning framework to be used by the inference application, a machine learning model to be used by the inference application, and an edge device to run the inference application. The service may then generate a package based on the inference application, the machine learning framework, the machine learning model, and a hardware platform of the edge device. To generate the package, the service may optimize the model based on the hardware platform of the edge device and/or the machine learning framework. The service may then deploy the package to the edge device. The edge device then installs the inference application and performs actions based on inference data generated by the machine learning model.
Resumen de: US2025233925A1
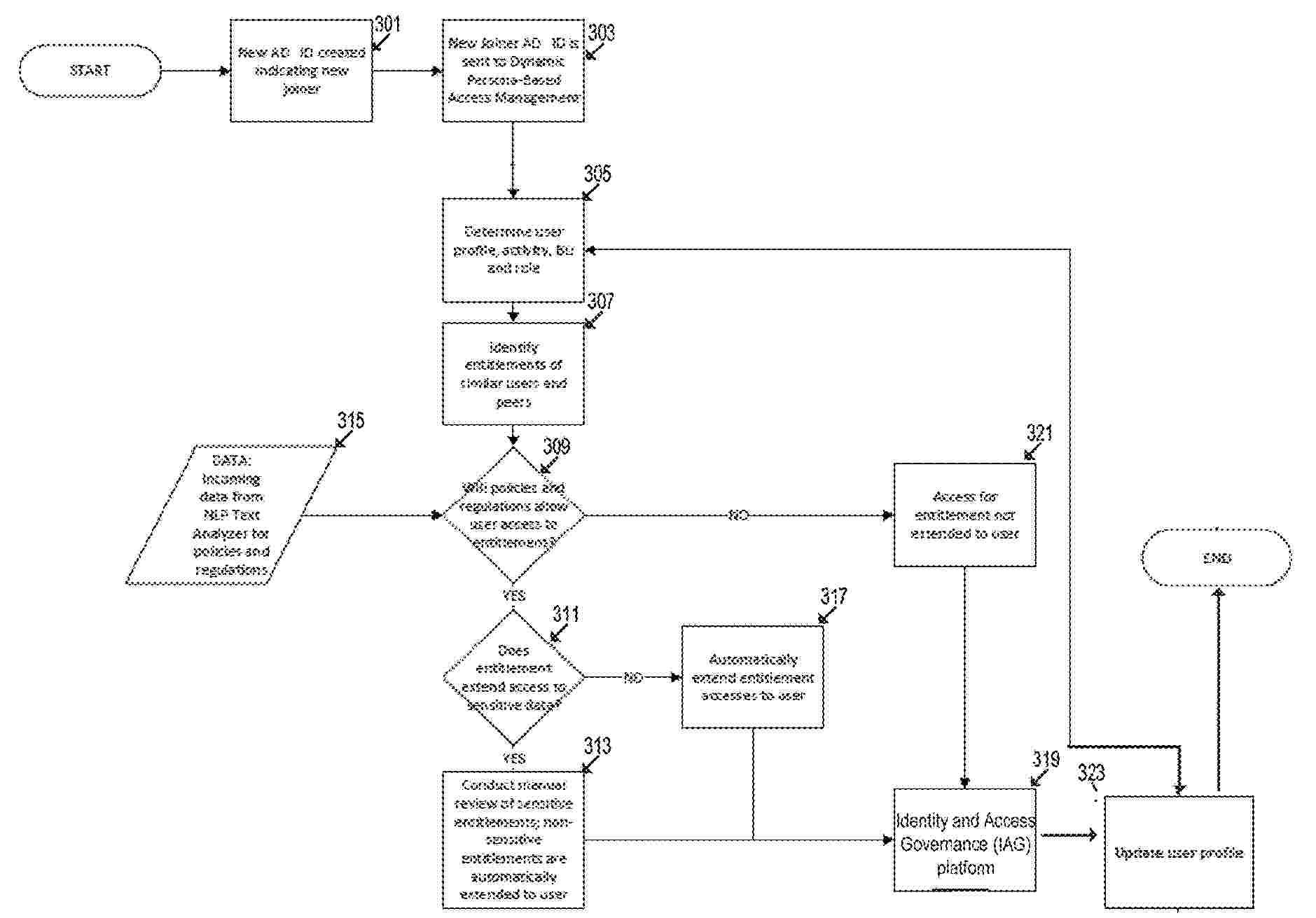
At least some embodiments are directed to a system that receives a profile values associated from new user profiles of a computer network or system. A machine learning system determines a set of existing profiles that share at least one common profile value with the new user profile. A second machine learning model determines a set of existing user entitlements associated with the set of existing profiles. The new user profile is processed by a natural language processing engine to determine a set of new user entitlements from the set of existing user entitlements. The system provides the new user with access to electronic resources of the computer network. The system tracks the new user computer network or system activities and updates the new user profile based on the set of new user entitlements and the new user activity on the computer network or system.
Resumen de: US2025232188A1
Traditional deep learning techniques are performed by high-performance system with direct access to the data to train large models. An approach of training the model from a collaboration of similar stakeholders where they pool together their data in a central server. However, data privacy is lost by exposing said models and data security while accessing heterogeneous data. Embodiments of the present disclosure provide a method and system for a cross-silo serverless collaborative learning among a plurality of clients in a malicious client threat-model based on a decentralized Epsilon cluster selection. Protocols are initialized and considered to iteratively train local models associated with each client and aggregate the local models as private input based on the multi-party computation to obtain global model. Non-linear transformation of a silhouette score to an Epsilon probability without implementing a server to select rth model from an active set to assign as the global model.
Resumen de: US2025231922A1
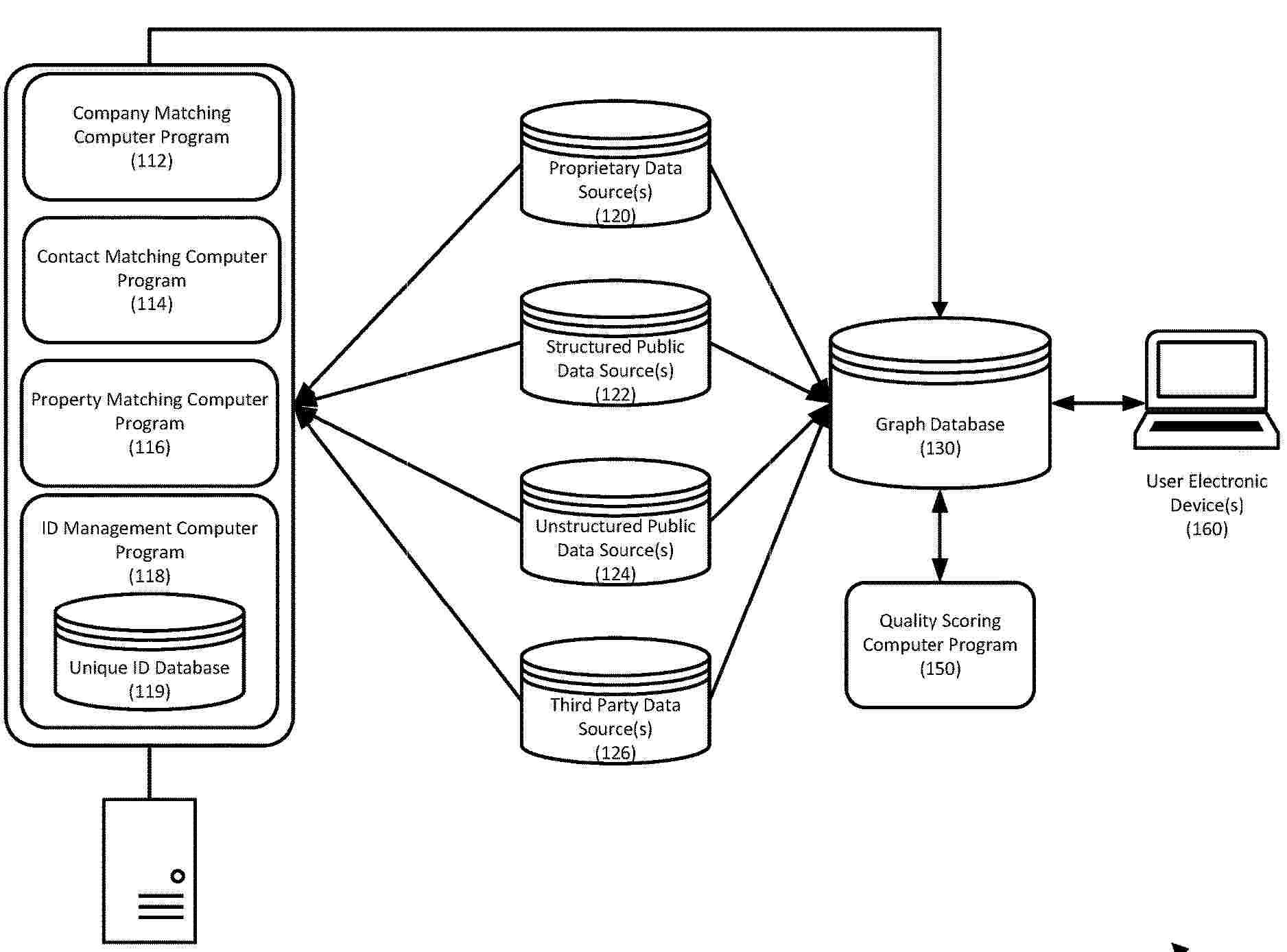
A method for machine learning-based data matching and reconciliation may include: ingesting a plurality of records from a plurality of data sources; identifying company associated with each of the plurality of records; assigning a unique identifier to each uniquely identified company; matching each of the records to one of the uniquely identified companies using a trained company matching machine learning engine; identifying a primary company record in the matching records and associating other matching records with the primary company record; matching each of the records to a contact using a trained contact matching machine learning engine; identifying a primary contact record in the matching records and associating other matching records with the primary contact record; synchronizing the plurality of records in a graph database using the unique identifier; receiving feedback on the matching companies and/or matching contacts; and updating the trained company matching machine learning engine.
Resumen de: EP4586142A1
Traditional deep learning techniques are performed by high-performance system with direct access to the data to train large models. An approach of training the model from a collaboration of similar stakeholders where they pool together their data in a central server. However, data privacy is lost by exposing said models and data security while accessing heterogeneous data. Embodiments of the present disclosure provide a method and system for a cross-silo serverless collaborative learning among a plurality of clients in a malicious client threat-model based on a decentralized Epsilon cluster selection. Protocols are initialized and considered to iteratively train local models associated with each client and aggregate the local models as private input based on the multi-party computation to obtain global model. Non-linear transformation of a silhouette score to an Epsilon probability without implementing a server to select r<sup>th</sup> model from an active set to assign as the global model.
Resumen de: EP4586260A1
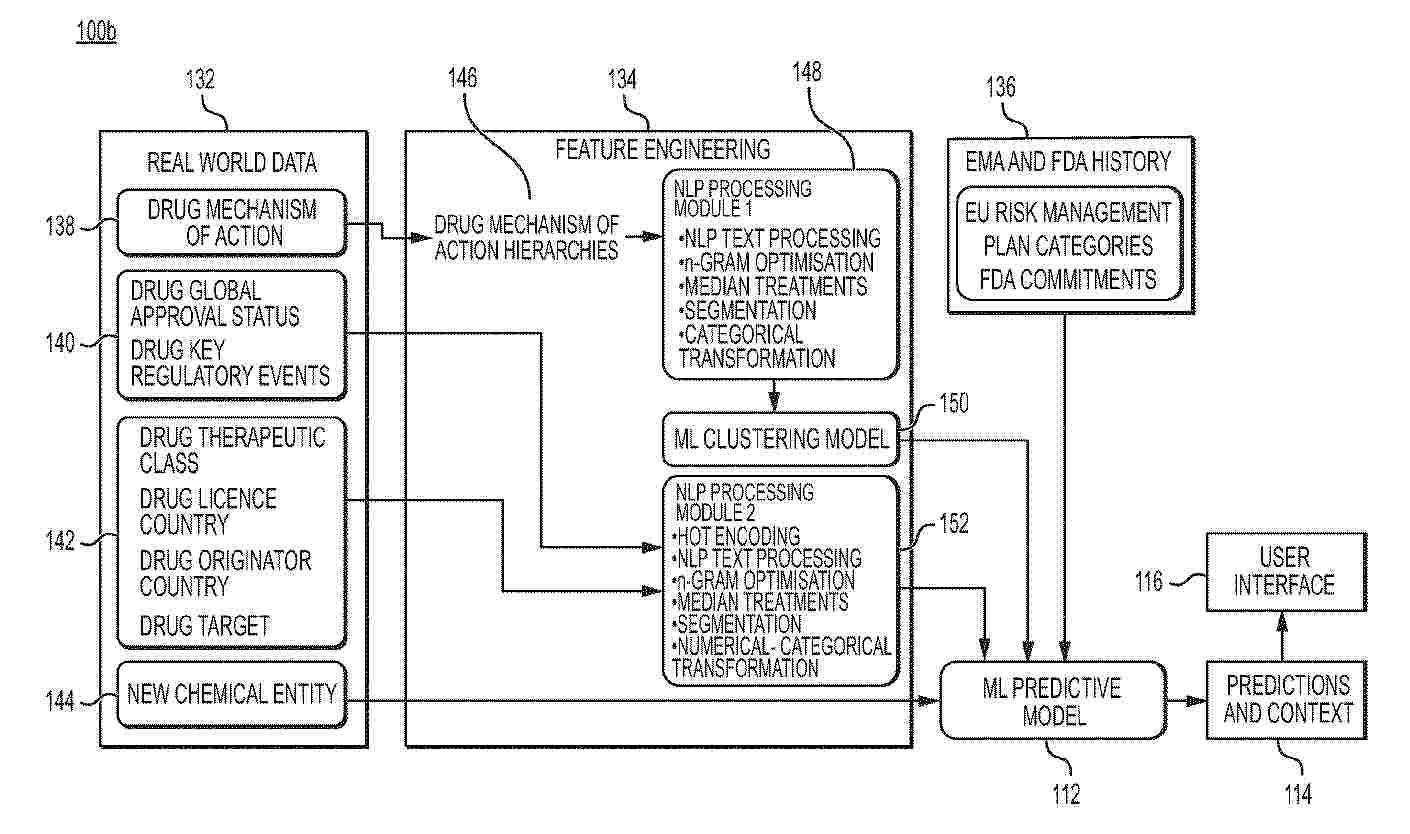
A computer-implemented method for generating machine-learning training data includes obtaining (654) mechanism of action (MOA) data that is indicative of a hierarchical tree structure of relationships between the MOA data (138); and generating (656) linear representations of branches of the hierarchical tree structure. It also includes determining (606) association rules for the MOA data by applying one or more frequent pattern-mining algorithm to the linear representations. It also includes determining (308, 608), as at least a portion of the generated machine learning training data, MOA clusters (400) by applying a clustering model (150) to the linear representations and the association rules. The method also includes determining the hierarchical tree structure by extracting (104) a plurality of nodes from the MOA data (138), and generating (602) the hierarchical tree structure based on the extracted nodes.
Resumen de: EP4586156A1
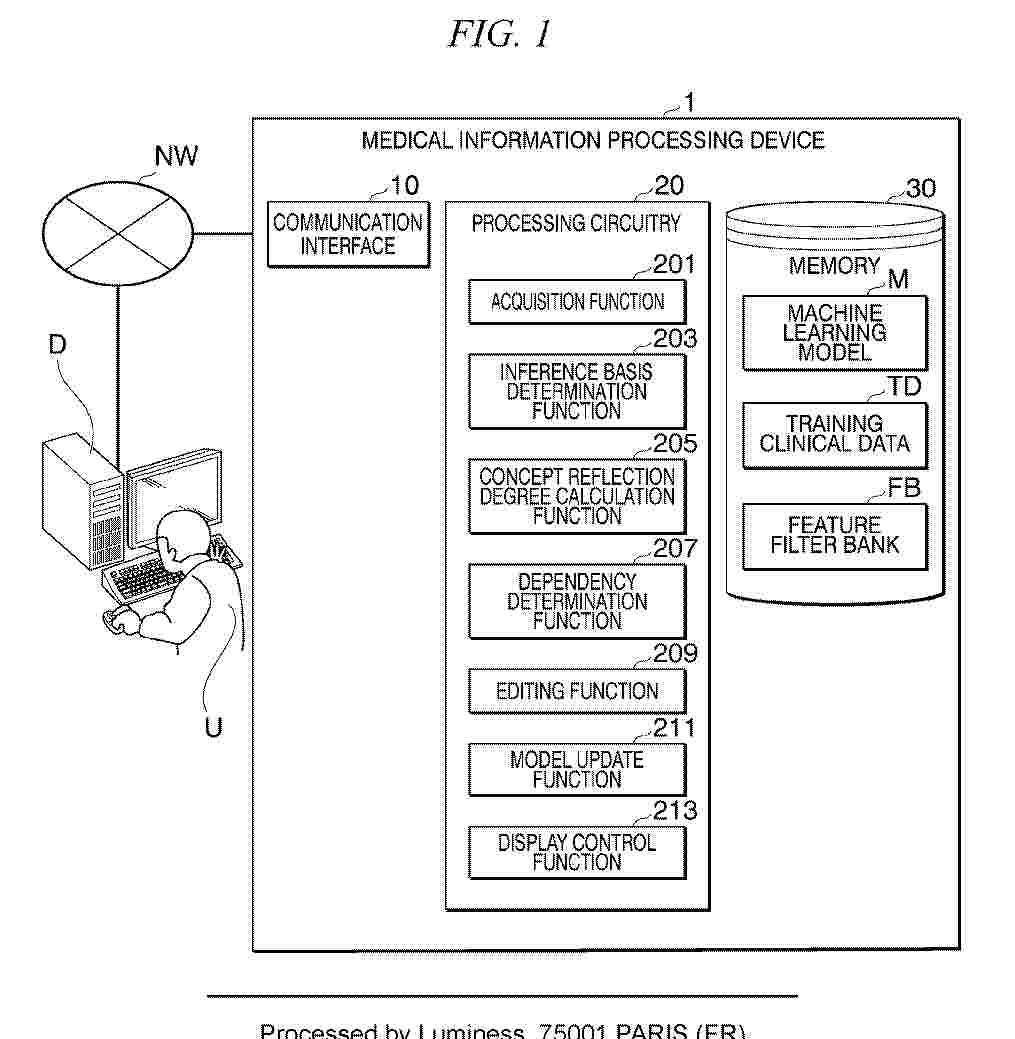
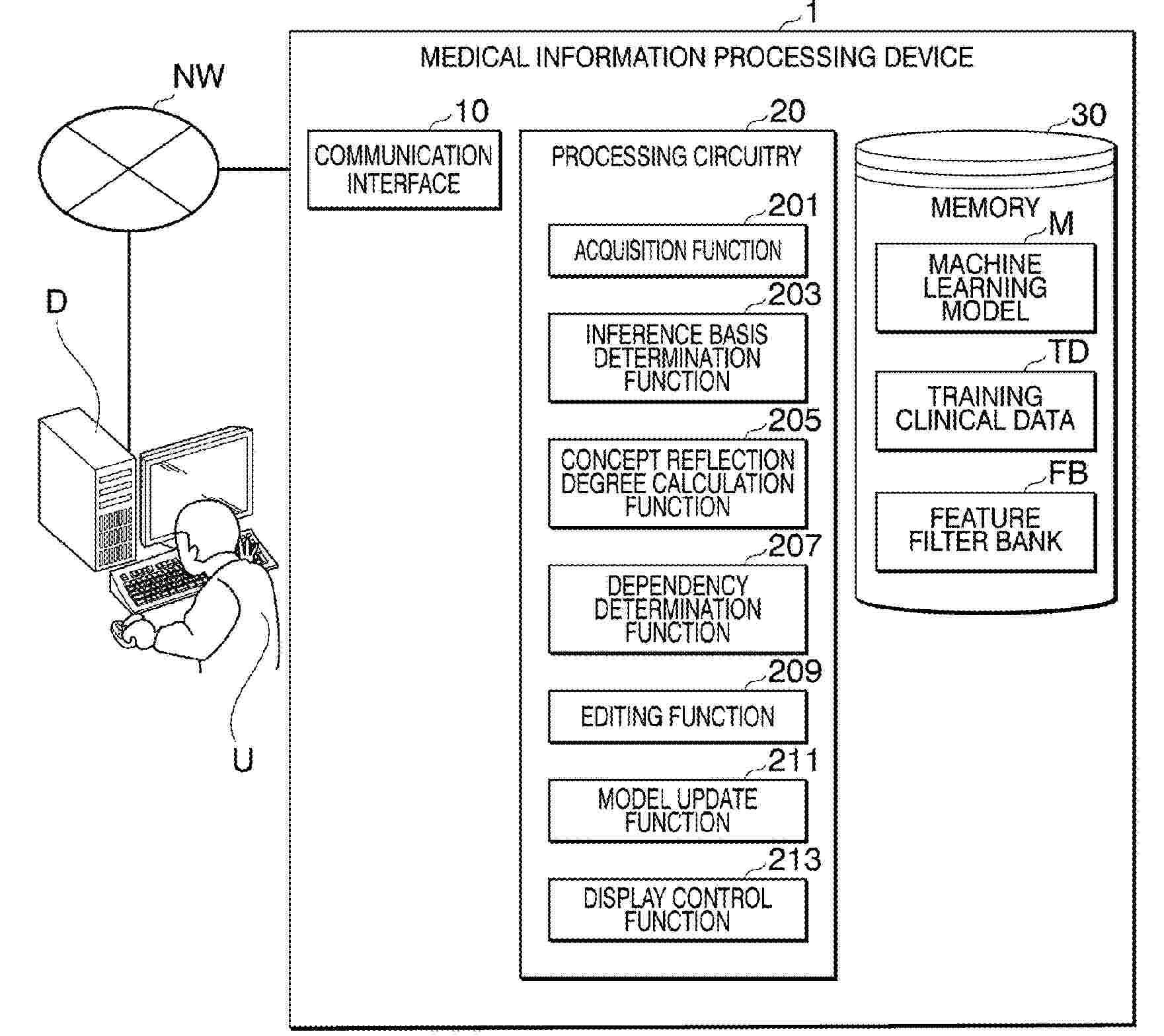
A medical information processing device of an embodiment includes an acquirer, an inference basis determiner, a concept reflection degree calculator, and a dependency determiner. The acquirer is configured to acquire a machine learning model and training data used to train the machine learning model. The inference basis determiner is configured to determine an inference basis for each piece of the training data using the machine learning model to generate inference basis visualization results. The concept reflection degree calculator is configured to determine a concept emphasized by the machine learning model during inference based on the inference basis visualization results and calculate a concept reflection degree of each piece of the training data related to the concept. The dependency determiner is configured to generate visualization information of a dependency between the concept and a feature interpretable by a user in the training data based on the concept reflection degree and the feature interpretable by the user.
Resumen de: US2025226094A1
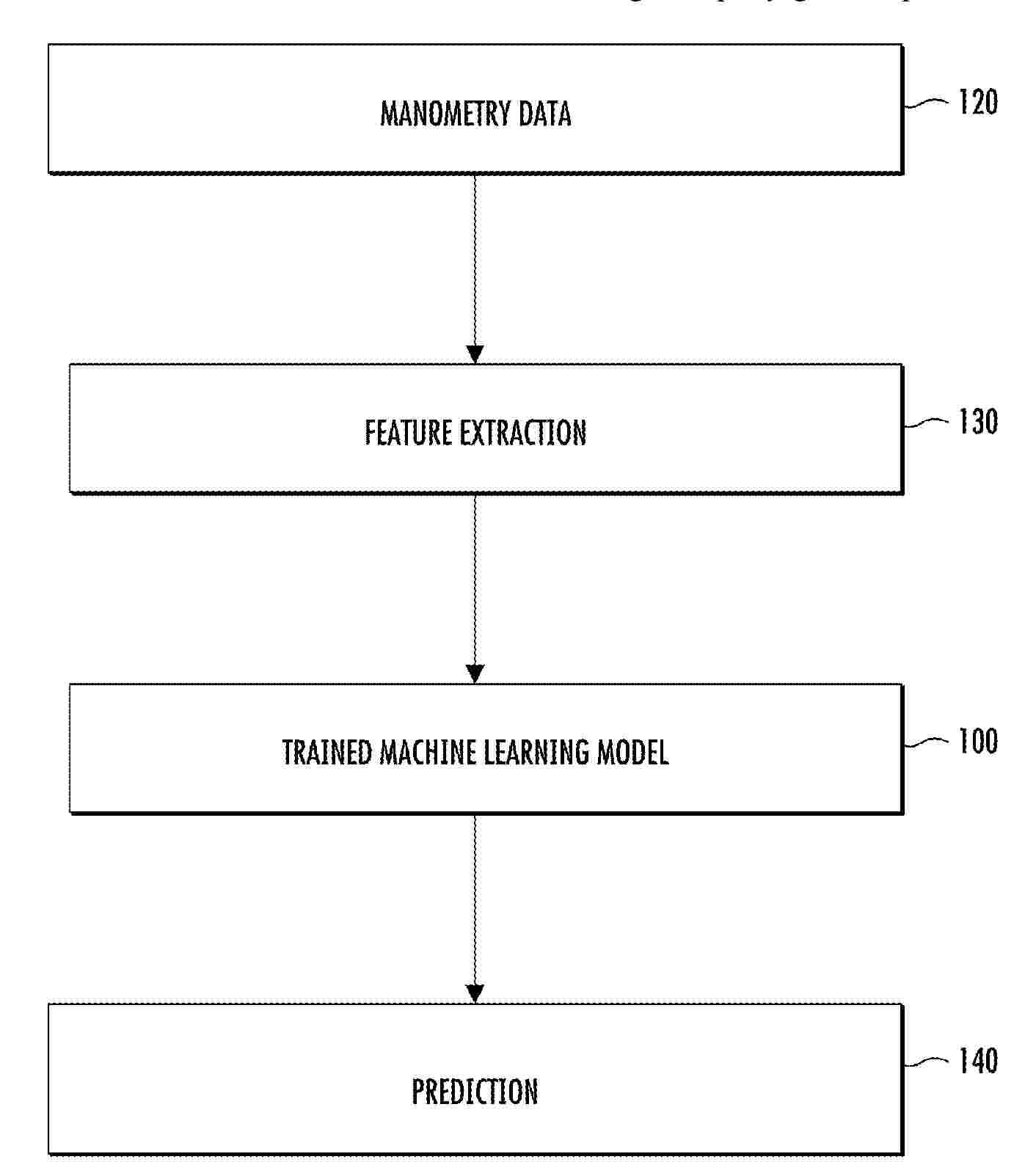
Systems and methods for pharyngeal phenotyping in obstructive sleep apnea are described herein. An example method includes receiving manometry data for a subject; extracting a plurality of features from the manometry data, where the extracted features include one or more of a high-level breath feature, a frequency feature, or a largest negative connected component (LNCC) feature; inputting the extracted features into a trained machine learning model; and predicting, using the trained machine learning model, at least one of a location of pharyngeal collapse for the subject or a degree of pharyngeal collapse for the subject.
Resumen de: US2025224993A1
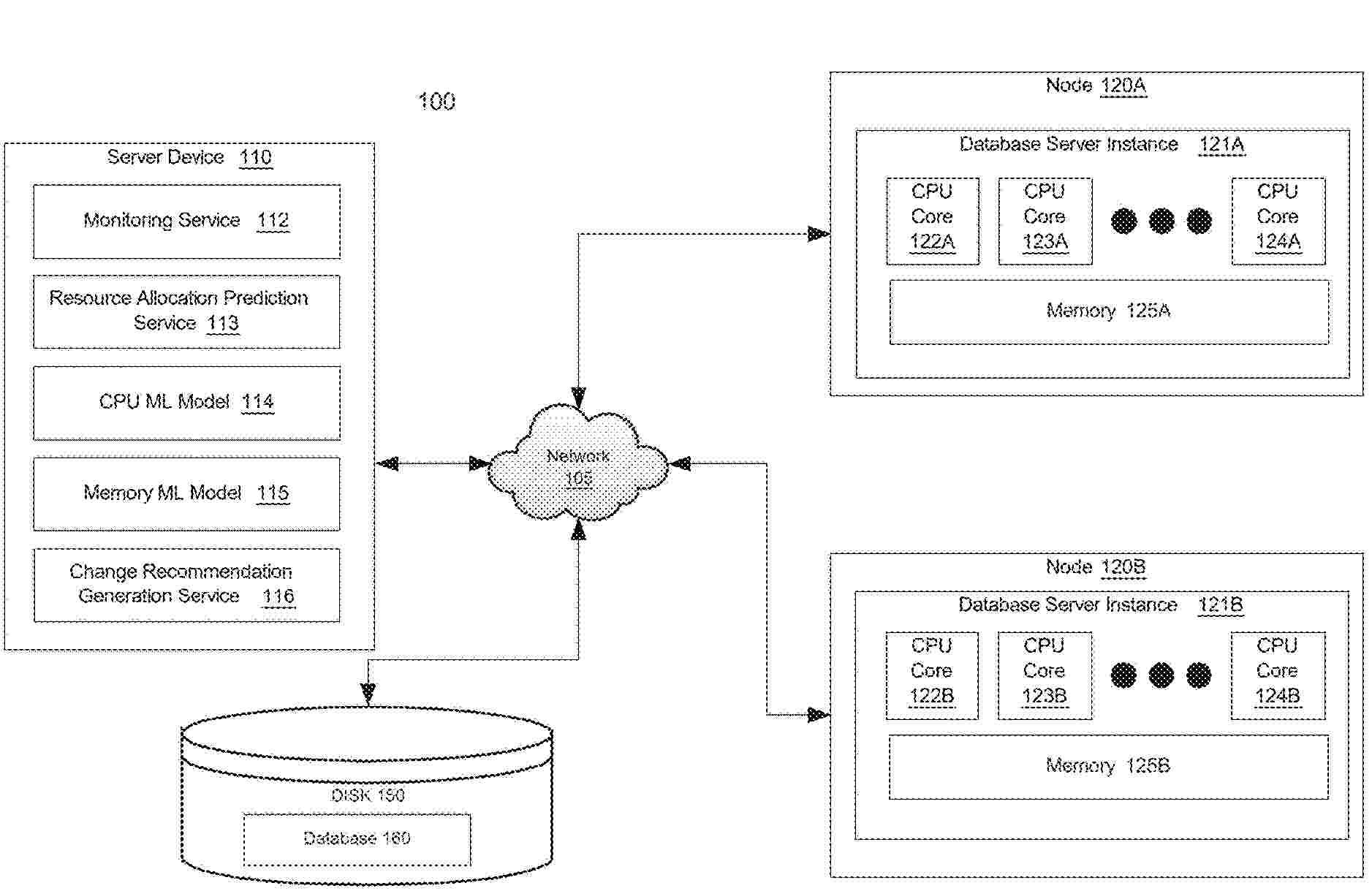
Techniques are provided for optimizing resources (e.g., CPU, memory, IO) allocated to a database server using one or more machine learning models. A database management system executes a database workload for the database server. During execution of the workload, a monitoring service collects metrics for the database workload and sends the metrics to a resource allocation prediction service. The resource allocation prediction service implements one or more machine learning models to generate optimized resource allocation predictions. A generated resource allocation prediction is sent to a change recommendation generation service that generates change instructions for updating the resources allocated to the database server in order to align the current resource allocation of the database server with the resource allocation prediction.
Resumen de: US2025225416A1
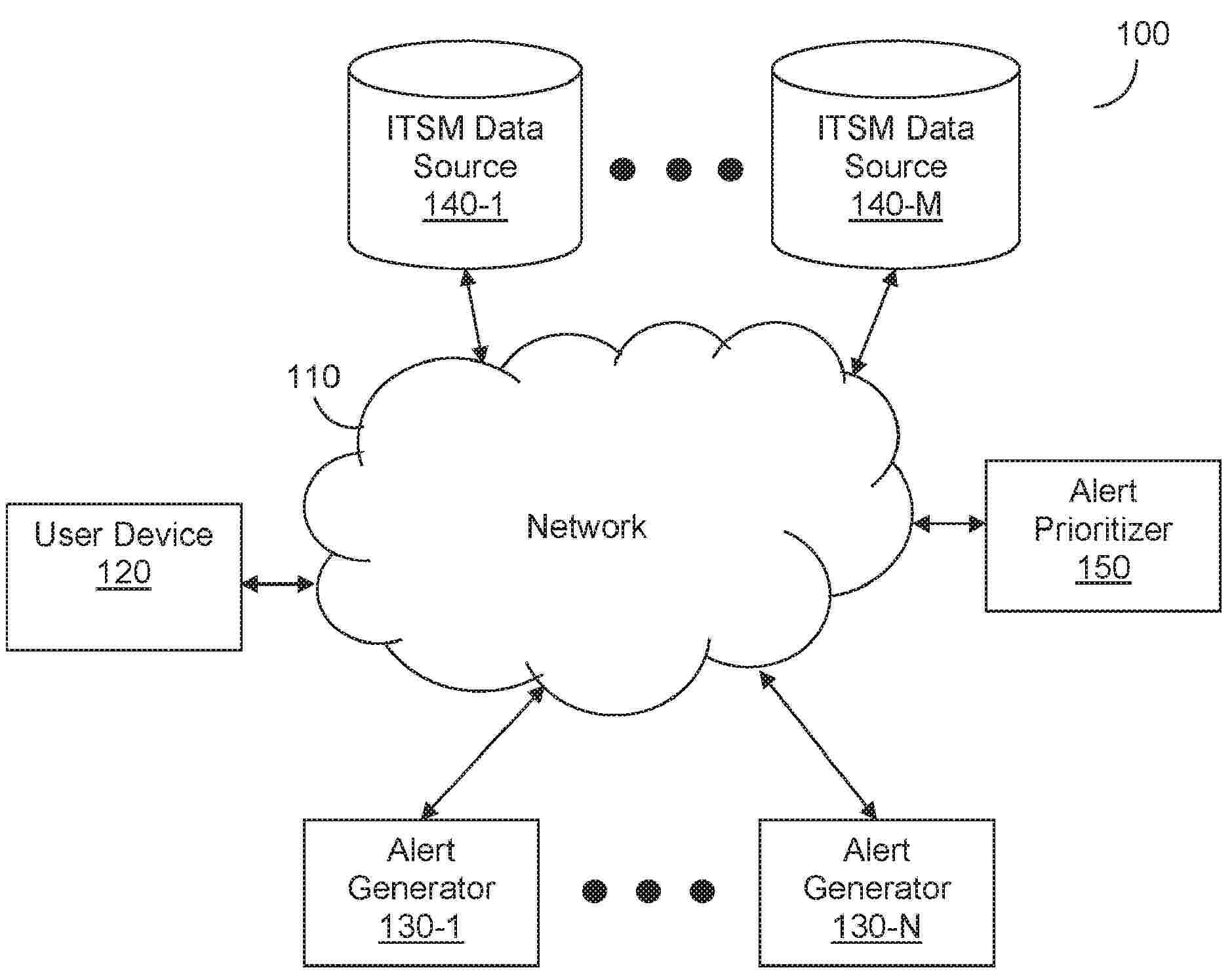
A plurality of correlations is determined including by applying a machine learning model to a first plurality of features extracted from a plurality of information technology and operations management alerts and information technology service management reporting data. Each correlation of the plurality of correlations is between a corresponding one of the plurality of information technology and operations management alerts and at least one corresponding portion of the information technology service management reporting data. The information technology service management reporting data includes at least one urgency indicator. A prioritized list of information technology and operations management alerts is generated based at least in part on the determined plurality of correlations and the at least one urgency indicator. The prioritized list of information technology and operations management alerts is organized based at least in part on relative priorities of the alerts.
Resumen de: US2025225474A1
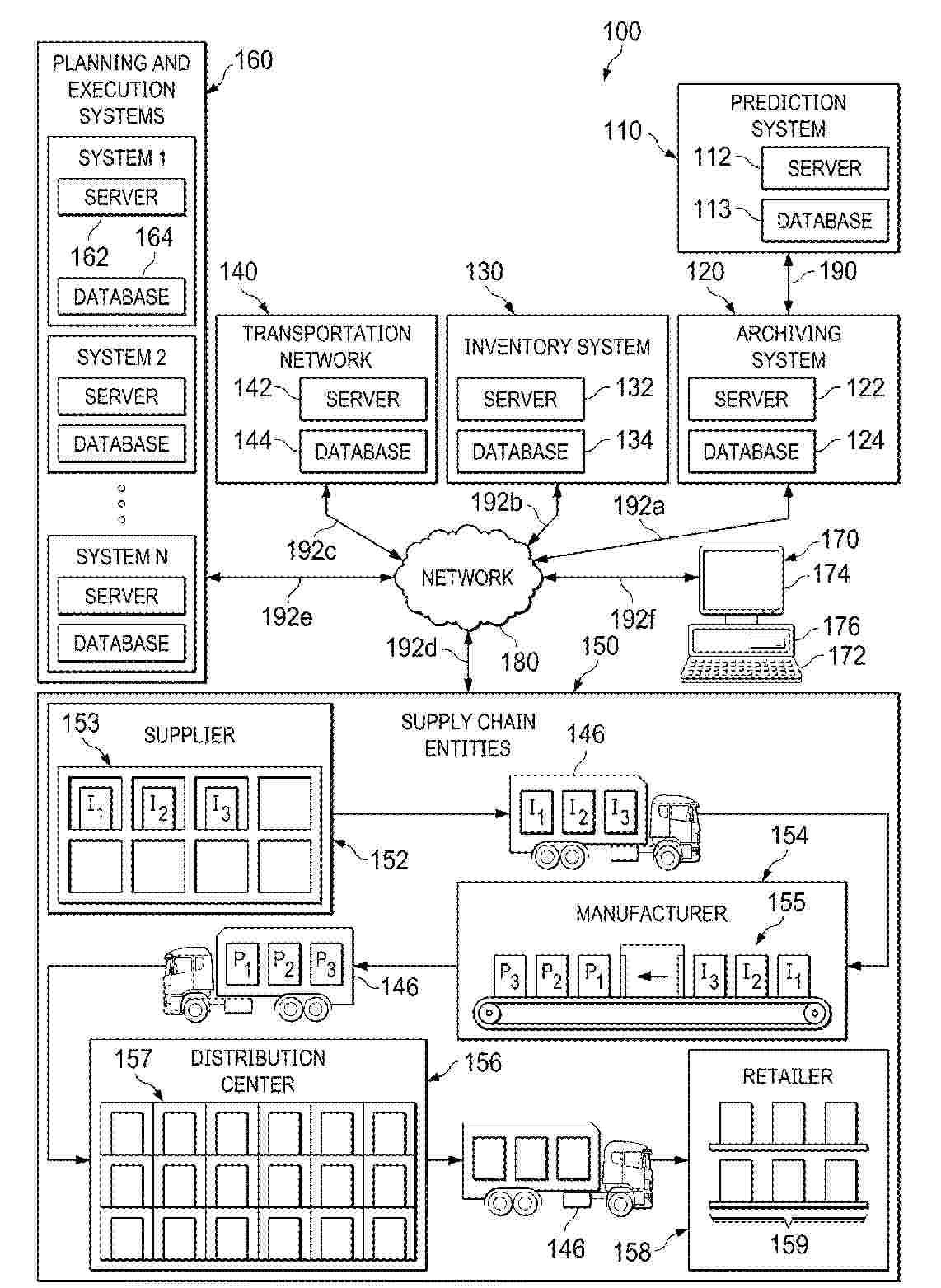
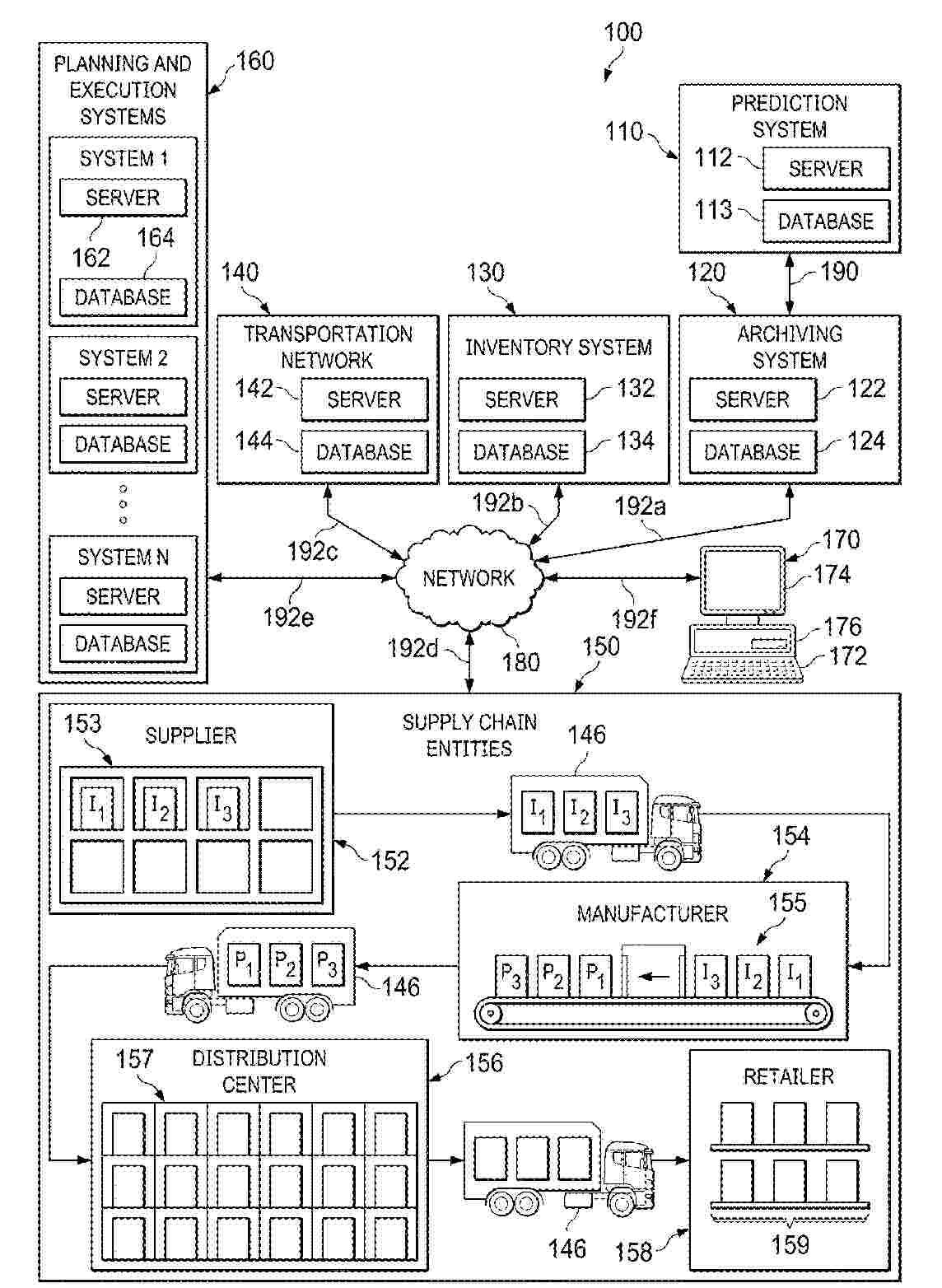
A system and method are disclosed for a low-touch centralized system to predict service level failure in a supply chain using machine learning. Embodiments include receiving only historical supply chain data from an archiving system for one or more supply chain entities storing items at stocking locations, predicting one or more supply chain events during a prediction period by applying a predictive model to a sample of historical supply chain data, calculating an occurrence risk score for at least one of the one or more supply chain events and indicating a possibility that the at least one of the one or more supply chain events will occur, generating one or more alerts identifying at least one item and at least one alert stocking location, rendering an alert heatmap visualization comprising one or more selectable user interface elements, and provide one or more tools for initiating corrective actions to be undertaken.
Resumen de: US2025225418A1
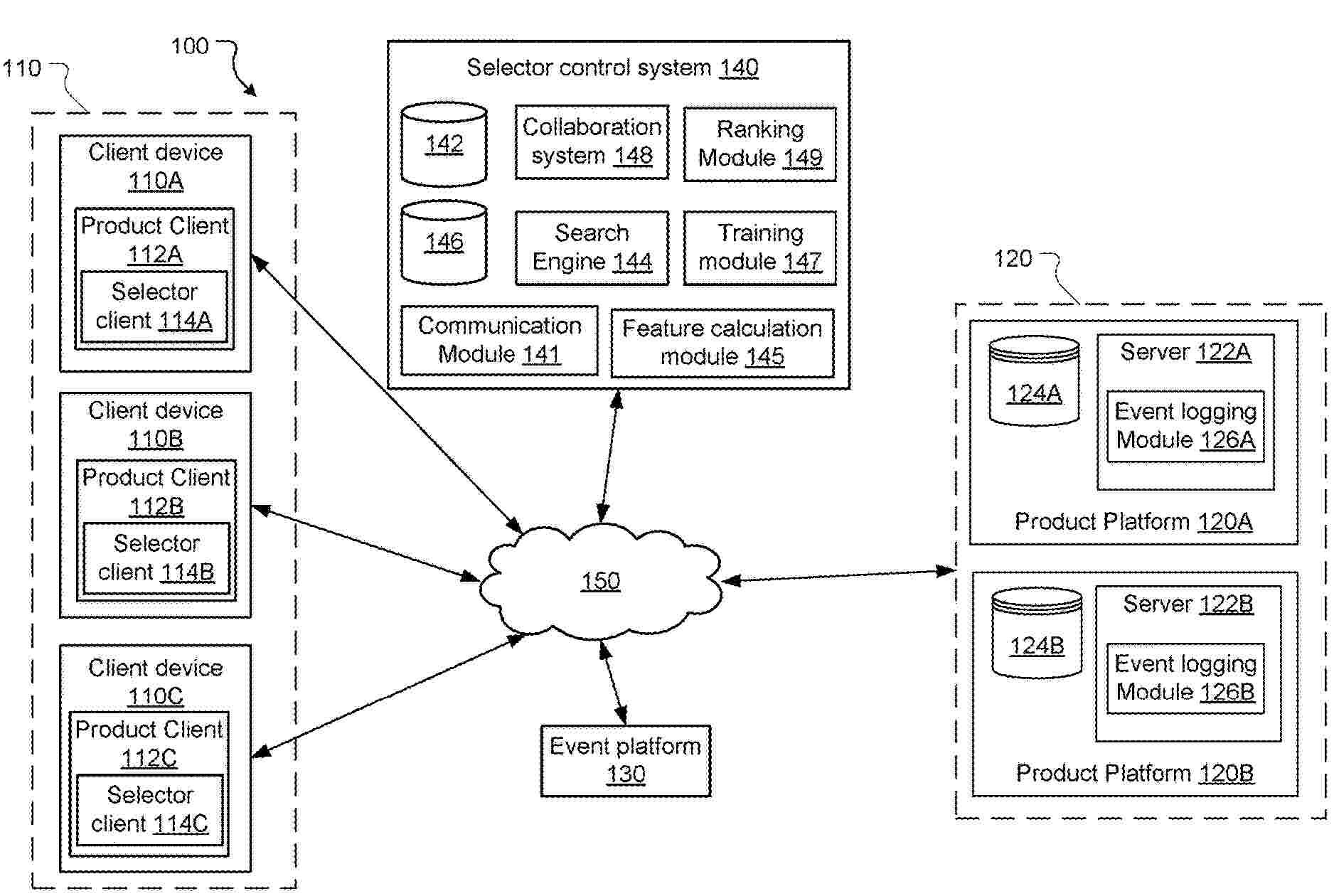
Methods and systems for intelligently recommending selections for a selector control are disclosed. The method includes receiving a recommendation request from a selector control client, the recommendation request comprising a search string and a unique identifier of a user interacting with a selector control; identifying user identifiers of usernames matching the search string; retrieving machine learning features corresponding to the user identifiers of usernames matching the search string; applying a machine learning model to the retrieved machine learning features to assign weights to the retrieved machine learning features; computing recommendation scores for the user identifiers based on the assigned weights to the retrieved machine learning features; ranking the user identifiers based on the recommendation scores; and forwarding a ranked list of user identifiers to the selector control client for displaying in the selector control for selection by the user interacting with the selector control.
Resumen de: US2025225473A1
A system and method are disclosed for a low-touch centralized system to predict service level failure in a supply chain using machine learning. Embodiments include receiving only historical supply chain data from an archiving system for one or more supply chain entities storing items at stocking locations, predicting one or more supply chain events during a prediction period by applying a predictive model to a sample of historical supply chain data, calculating an occurrence risk score for at least one of the one or more supply chain events and indicating a possibility that the at least one of the one or more supply chain events will occur, generating one or more alerts identifying at least one item and at least one alert stocking location, rendering an alert heatmap visualization comprising one or more selectable user interface elements, and provide one or more tools for initiating corrective actions to be undertaken.
Resumen de: US2025225439A1
A medical information processing device of an embodiment includes processing circuitry. The processing circuitry is configured to acquire a machine learning model and training data used to train the machine learning model, determine an inference basis for each piece of the training data using the machine learning model to generate inference basis visualization results, determine a concept emphasized by the machine learning model during inference based on the inference basis visualization results, calculate a concept reflection degree of each piece of the training data related to the concept, and generate visualization information of a dependency between the concept and a feature interpretable by a user in the training data based on the concept reflection degree and the feature interpretable by the user.
Resumen de: US2025225523A1
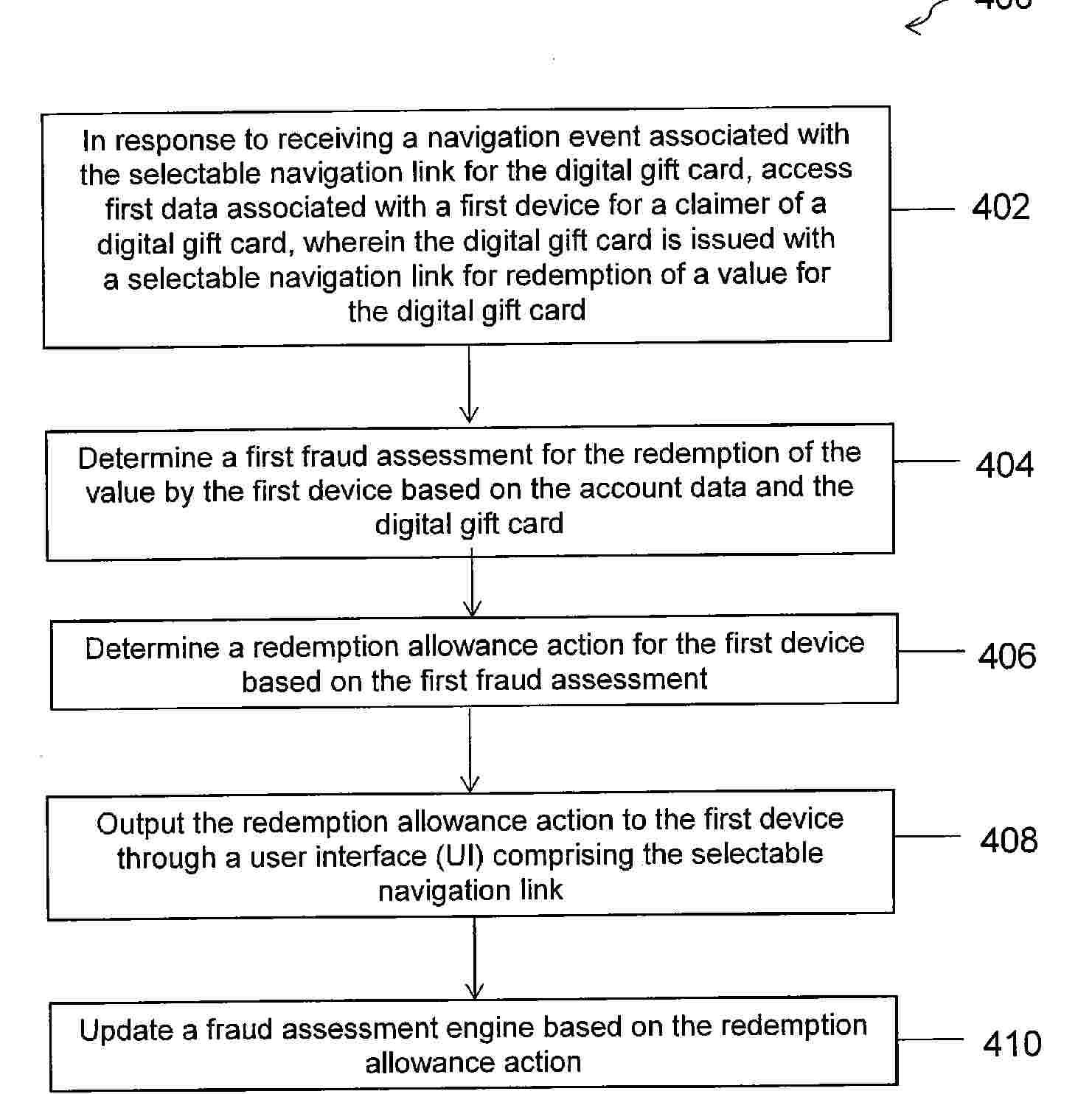
A machine learning engine may be trained using artificial intelligence techniques and used according to techniques discussed herein. While an initial electronic transaction for a resource may be permitted, a subsequent related transaction to the initial electronic transaction may be analyzed in view of additional electronic information that was not available at the time of the initial transaction. Analysis of the subsequent related transaction, using the machine learning engine, may indicate a new classification related to the resource and/or the acquisition of the resource. Based on this new classification, usage of the resource may be restricted and/or denied, and the initial transaction for the resource may even be canceled retroactively.
Resumen de: US2025225441A1
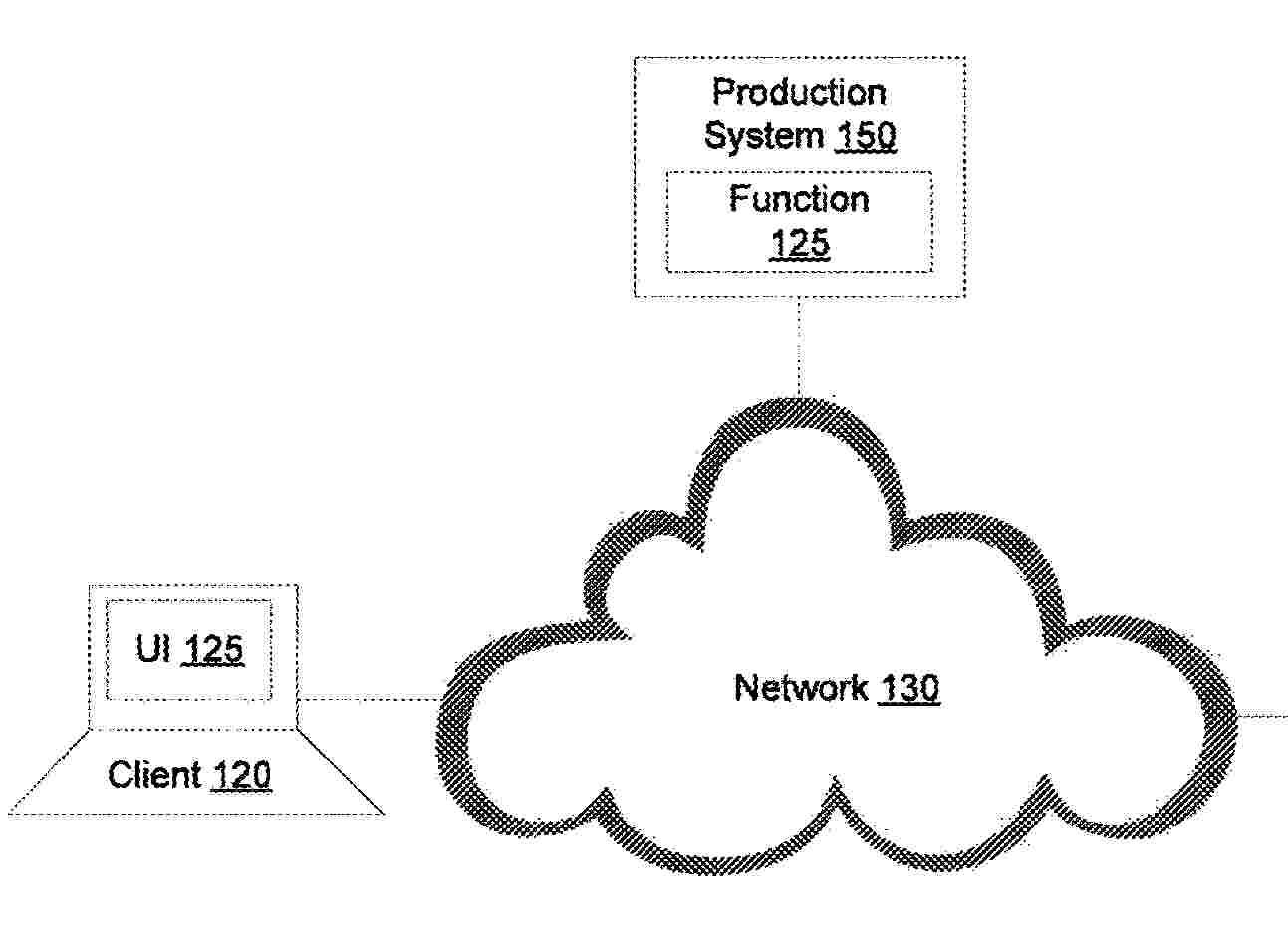
A method for determining the performance metric of a function may include interpolating the performance metric of the function relative to a known performance metric of a reference function. The performance metric of the function may be interpolated based on a first difference in a performance of the function measured by applying a first machine learning model and a performance of the function measured by applying a second machine learning model. The performance metric of the function may be further interpolated based on a second difference in a performance of the reference function measured by applying the first machine learning model and a performance of the reference function measured by applying the second machine learning model. The function may be deployed to a production system if the performance metric of the function exceeds a threshold value. Related systems and articles of manufacture, including computer program products, are also provided.
Resumen de: US2025225445A1
A computer-implemented method for generating machine learning training data may include obtaining mechanism of action (MOA) data that is indicative of a hierarchical tree structure of relationships between the MOA data; generating linear representations of branches of the hierarchical tree structure; determining association rules for the MOA data by applying one or more frequent pattern mining algorithm to the linear representations; and determining, as at least a portion of the generated machine learning training data, MOA clusters by applying a clustering model to the linear representations and the association rules.
Resumen de: AU2023407504A1
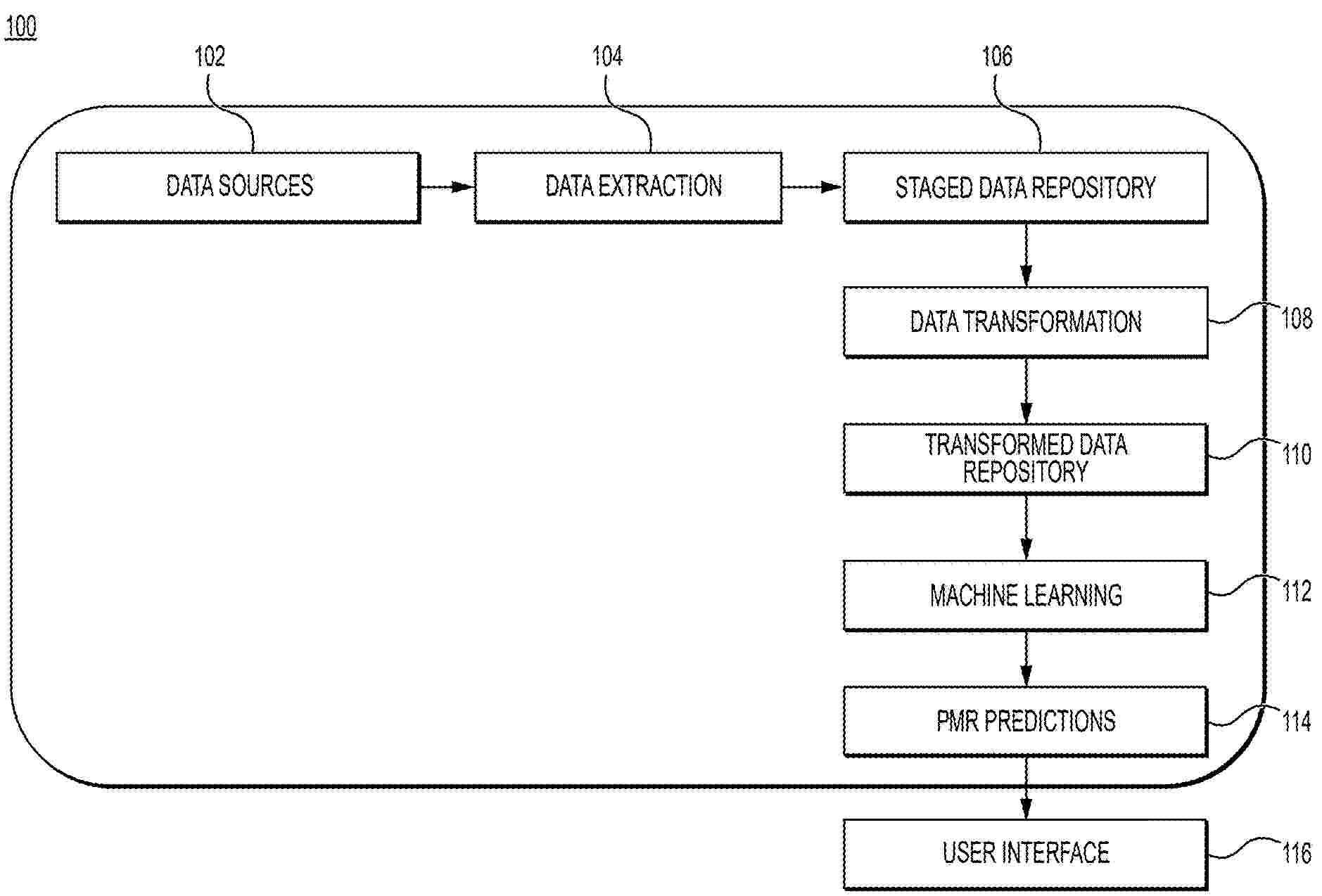
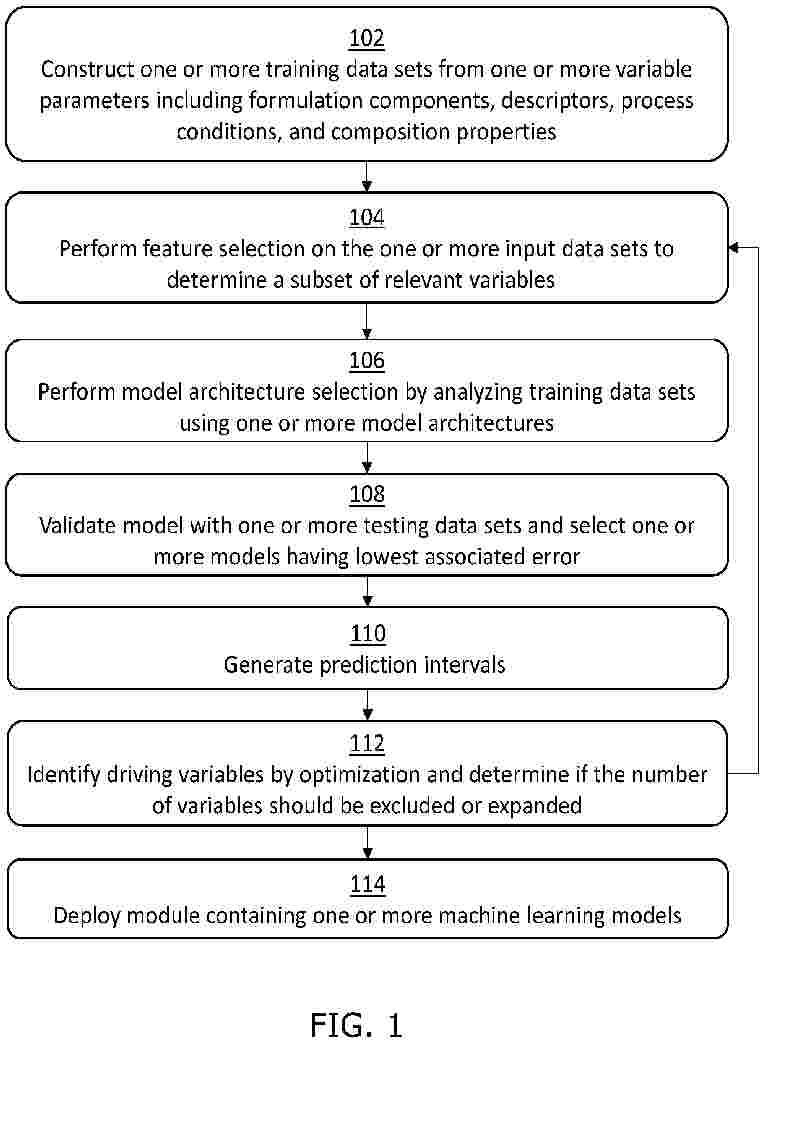
Methods include training a machine learning module to predict one or more target product properties for a prospective chemical formulation, including (a) constructing or updating a training data set from one or more variable parameters; (b) performing feature selection on the training data set; (c) building one or more machine learning models using one or more model architectures; (d) validating the one or more machine learning models; (e) selecting at least one of the one or more machine learning models and generating prediction intervals; (g) interpreting the one or more machine learning models; and (h) determining if the one or more target product properties calculated are acceptable and deploying one or more trained machine learning models, or optimizing the one or more machine learning models by repeating steps (b) to (g). Methods also include application of trained machine learning modules to predict formulation properties from prospective data.
Resumen de: US2025226063A1
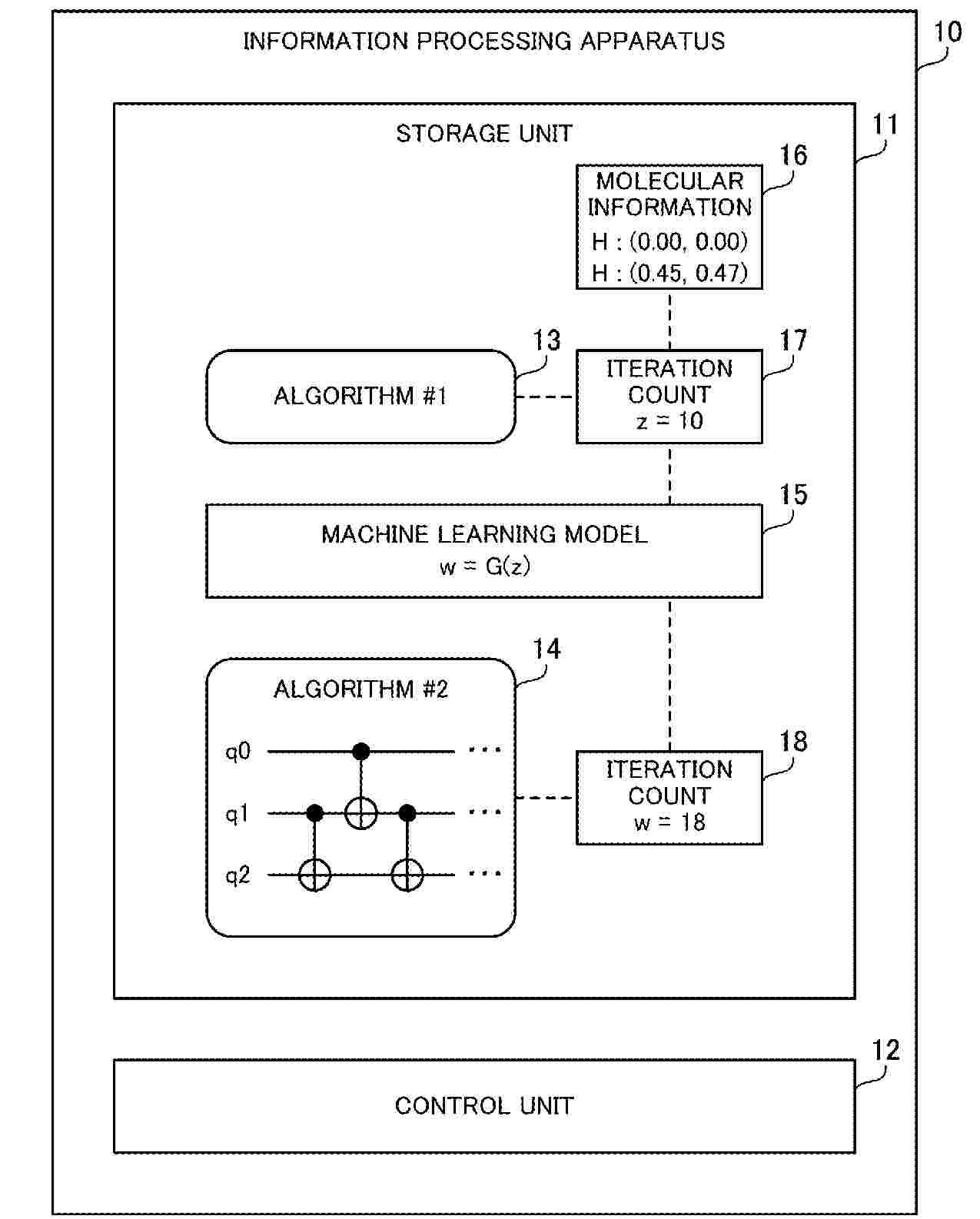
A computer executes, among algorithms configured to obtain energy of a molecule through an iterative process and including a first algorithm and a second algorithm that uses quantum circuit data and is different from the first algorithm, the first algorithm based on molecular information specifying a molecule to be analyzed, to obtain a first iteration count of the first algorithm. The computer enters the first iteration count into a machine learning model trained with an iteration count of the first algorithm as an explanatory variable and an iteration count of the second algorithm as a response variable. The computer outputs an estimated value of a second iteration count of the second algorithm obtained from the machine learning model, for execution of the second algorithm based on the molecular information.
Resumen de: WO2025147274A1
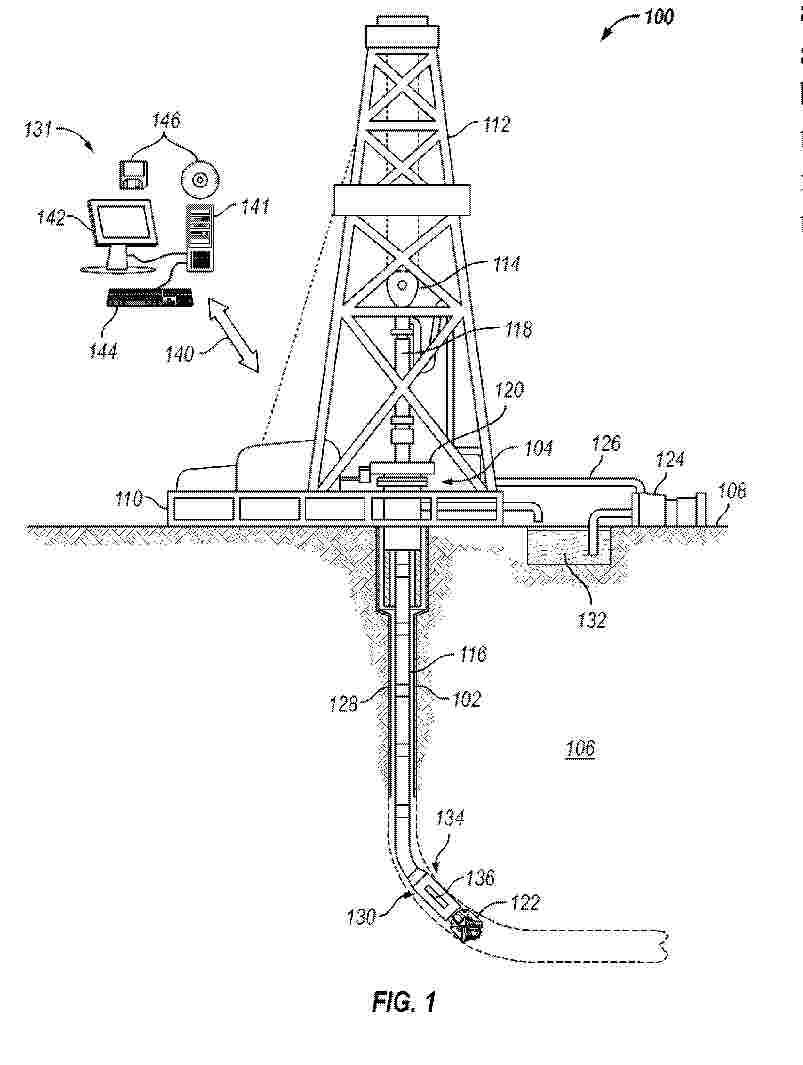
A method and a system comprising: disposing a bottom hole assembly (BHA) into a wellbore, wherein the BHA comprises a measurement assembly; acquiring one or more measurements with the measurement assembly; acquiring historical data from the wellbore; extracting relevant information from the historical data; training a machine learning (ML) model with the relevant information to form a trained ML model; and providing an answer to a question utilizing the trained ML model.
Resumen de: AU2022492000A1
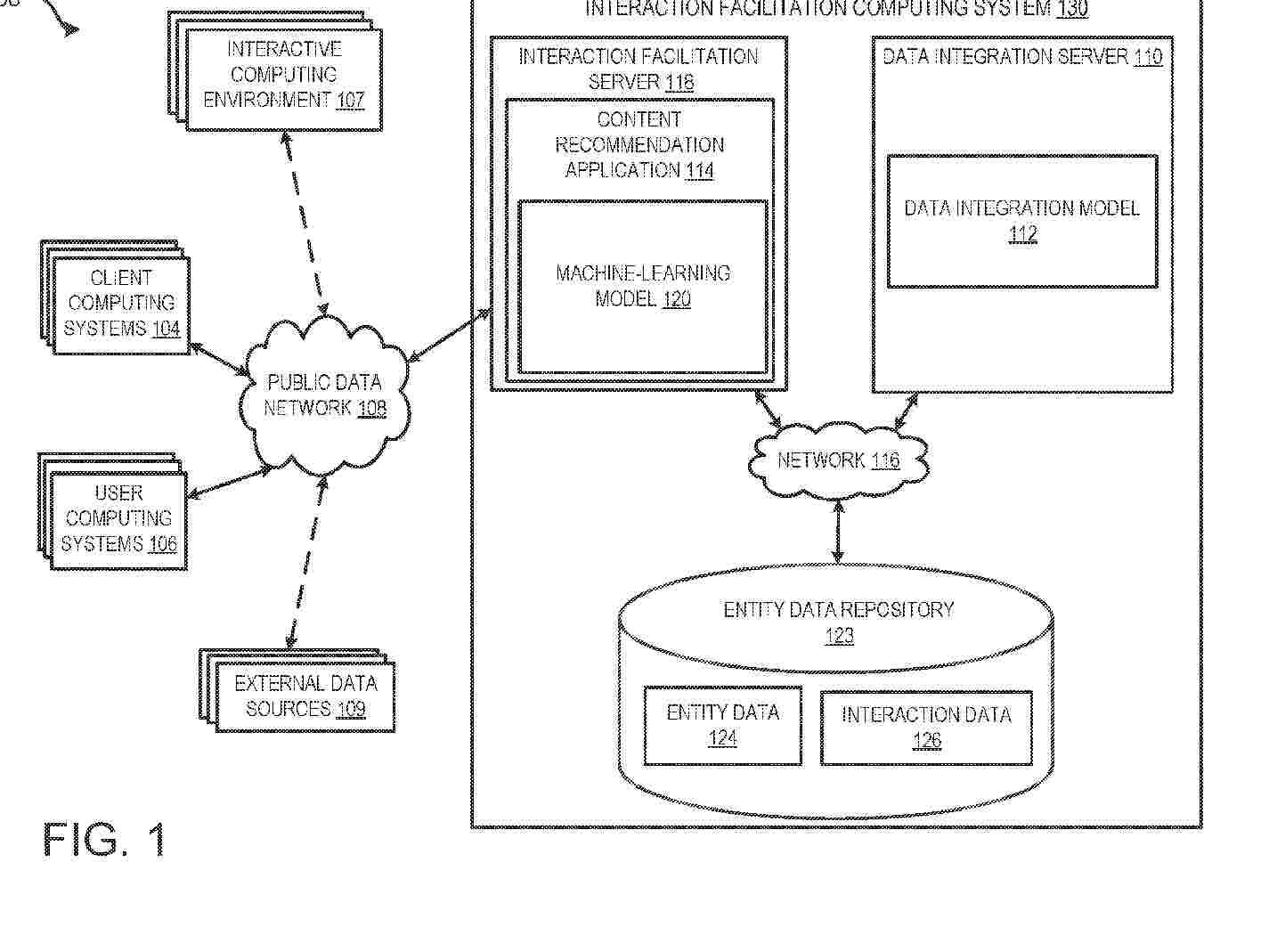
A system can generate content recommendations and facilitate interactions using machine-learning. The system can receive a request from a provider entity. The system can receive entity data and interaction data associated with a target entity. The system can generate at least a first graph structure and a second graph structure. The system can generate a linked graph structure based on the first graph structure and the second graph structure. The system can determine among a plurality of operations, one or more target operations to perform on data included in the linked graph structure. The system can execute using a trained machine-learning model, the target operations to generate a content recommendation for facilitating an interaction. The system can provide a responsive message based on the content recommendation usable to facilitate the interaction.
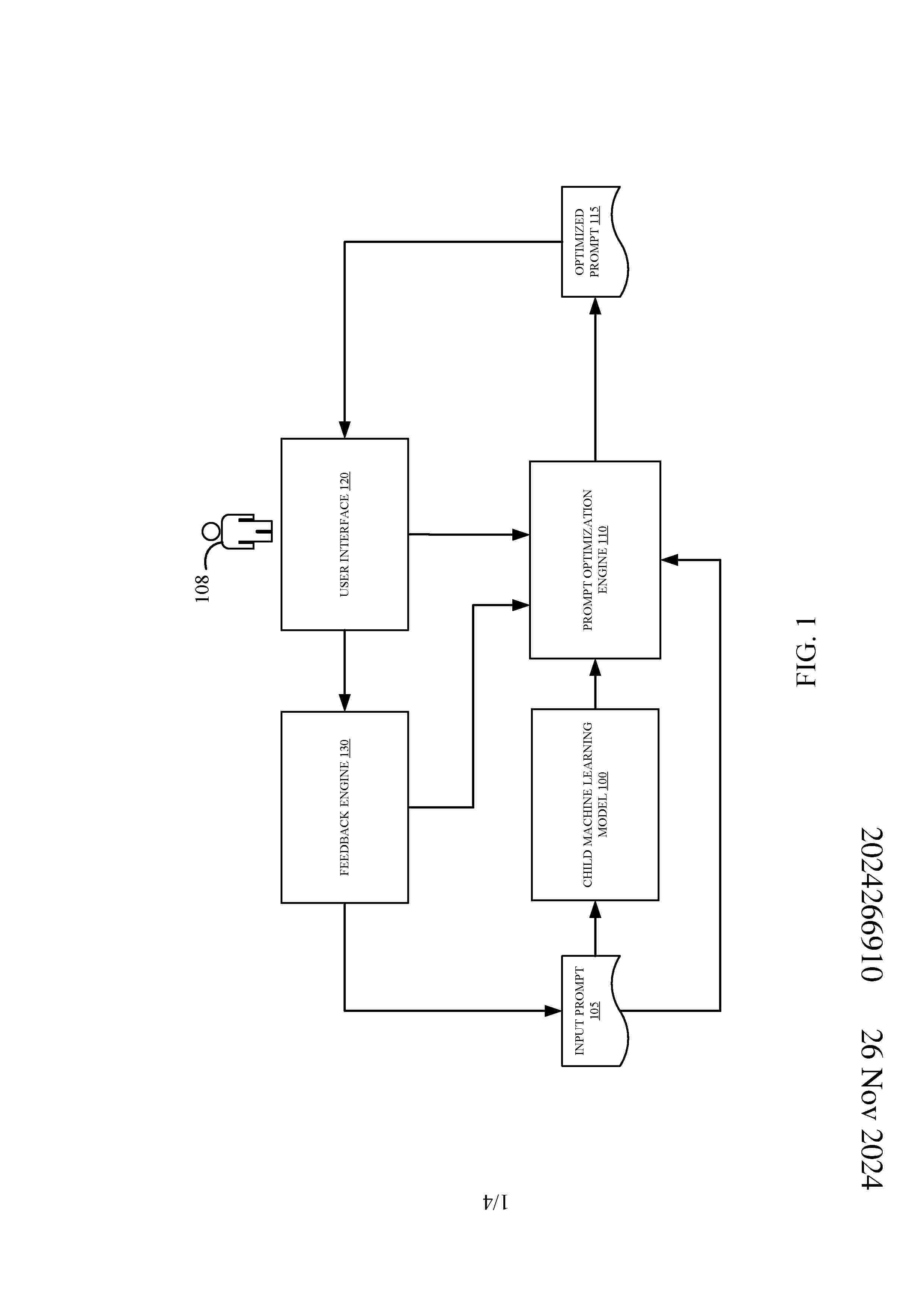
Resumen de: AU2024266910A1
Aspects of the present disclosure relate to generating optimized machine learning model prompts. Embodiments include providing an input prompt to a child machine learning model that directs the child machine learning model to generate an output. Embodiments further include generating a parent model prompt comprising instructions to generate a score for the input prompt based on one or more scoring criteria, the input prompt, and the output of the child machine learning model. Embodiments further include providing the parent model prompt to a parent machine learning model. Embodiments further include generating, by a generative machine learning model, an optimized prompt for the child machine learning model based on the generated score for the input prompt. Aspects of the present disclosure relate to generating optimized machine learning model prompts. Embodiments include providing an input prompt to a child machine learning model that directs the child machine learning model to generate an output. Embodiments further include generating a parent model prompt comprising instructions to generate a score for the input prompt based on one or more scoring criteria, the input prompt, and the output of the child machine learning model. Embodiments further include providing the parent model prompt to a parent machine learning model. Embodiments further include generating, by a generative machine learning model, an optimized prompt for the child machine learning model based on the gene
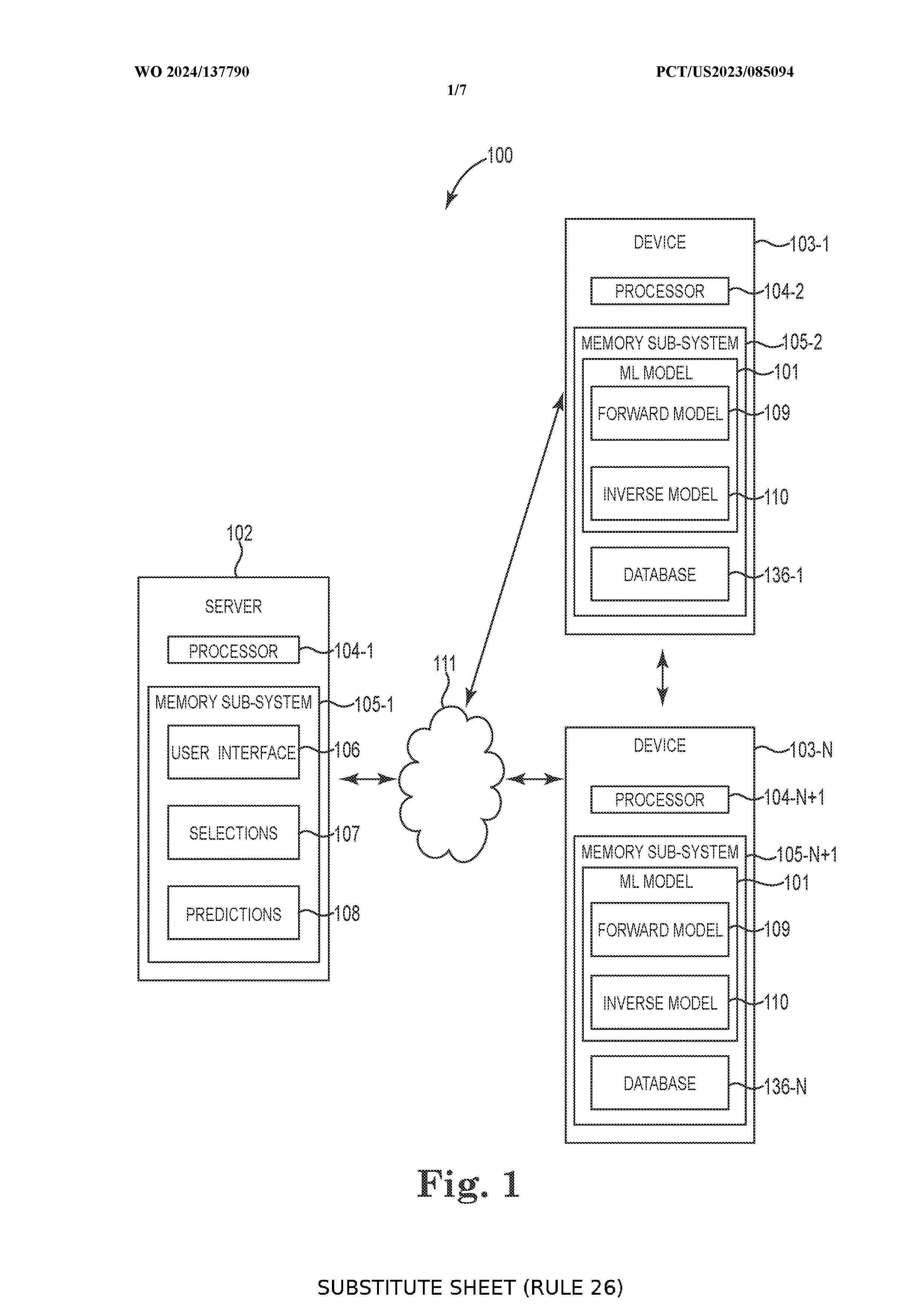
Resumen de: AU2023409235A1
Machine learning can be used to predict formulations for an output formulation. The machine learning can be implemented by a machine learning model, which employs a forward model and an inverse model. A user interface can be used to gather raw materials selections and output formulation property selections. The selections can be used to generate formulations that comply with selections using the ML model.
Resumen de: WO2024064077A1
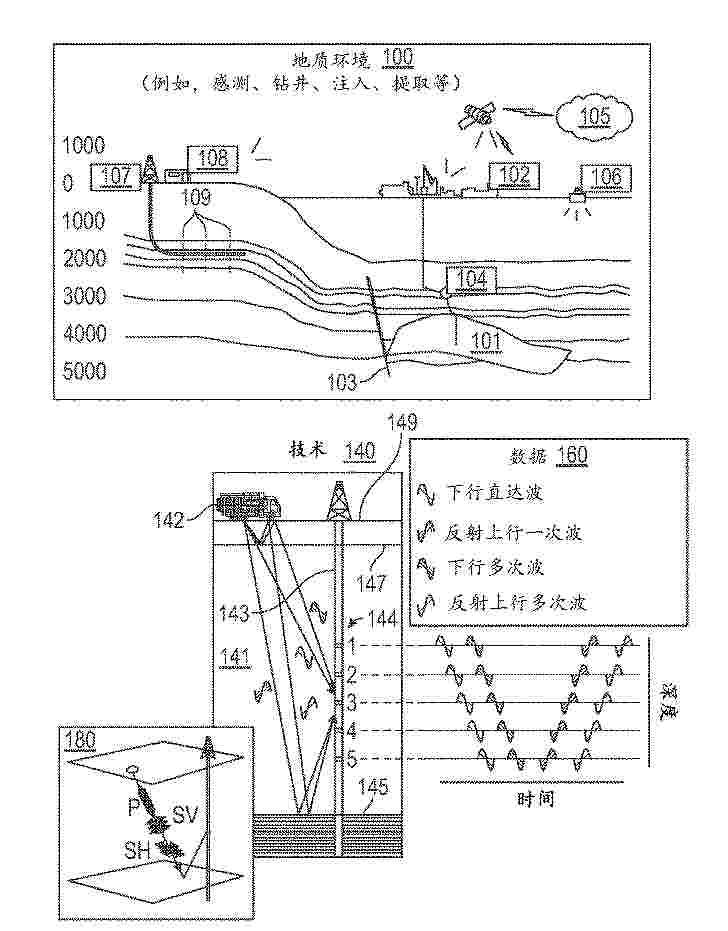
Disclosed are methods, systems, and computer programs for placing one or more optimal infill well locations within a reservoir. The methods include: generating a first multi-dimensional reservoir model of a first reservoir that is parameterized; assigning well placement data to the first reservoir model to generate a simulation model; applying a stochastic optimization process in a first simulation on the simulation model; determining infill well locations data based on the first simulation; configuring a second multi-dimensional reservoir model based on the infill well locations data; and generating using the second multi-dimensional reservoir model, one or more of: pressure delta data for one or more infill locations associated with a second reservoir, and a simulation opportunity index indicating reservoir properties for the one or more infill locations associated with the second reservoir.
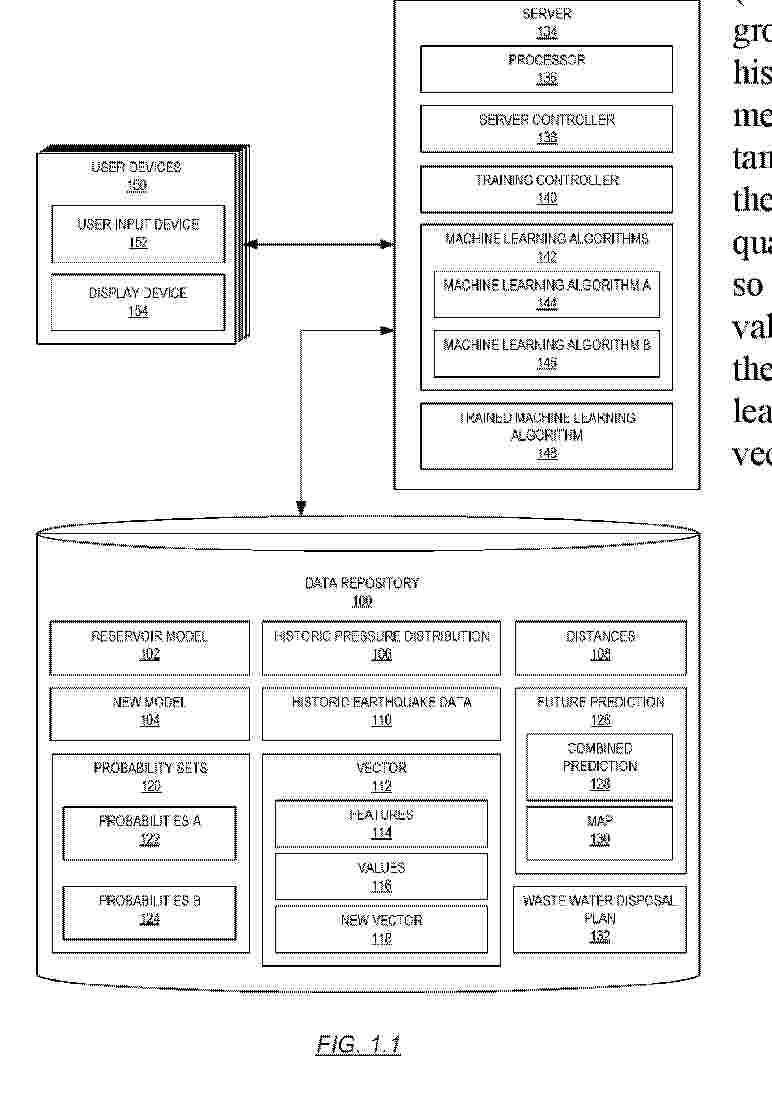
Resumen de: WO2024064009A1
A method including receiving a reservoir model of a target underground region. The method also includes extracting, from the reservoir model, a historic pressure distribution in grid cells of the target underground region. The method also includes extracting, from the reservoir model, distances. Each distance represents a distance between a grid cell and a corresponding lineament in the target underground region. The method also includes receiving historic earthquake data of past earthquakes in the target underground region. The method also includes generating a vector. The vector includes features and corresponding values for at least i) the historic pressure distribution, ii) the distances, and iii) the historic earthquake data. The method also includes training a trained machine learning algorithm by recursively executing a machine learning algorithm on the vector until convergence.
Resumen de: WO2024063797A1
Methods, computing systems, and computer-readable media for a machine learning method of modeling fault-related properties of a geological region are presented. The techniques include: obtaining seismic geological data for a geological region; obtaining from a user identifications of a plurality of faults in the geological region; automatically generating values for descriptors of respective faults of the plurality of faults; automatically partitioning faults of the plurality of faults into a plurality of groups according to the values for the descriptors; obtaining a mapping of respective groups of the plurality of groups to modeling parameter values; applying the mapping to a fault in the geological region outside of the plurality of faults to obtain a modeling parameter value for the fault outside of the plurality of faults; and modeling a fault-related property of the geological region based on the modeling parameter value for the fault outside of the plurality of faults.
Nº publicación: EP4581763A1 09/07/2025
Solicitante:
HUGHES NETWORK SYSTEMS LLC [US]
Hughes Network Systems, LLC
Resumen de: US2024396814A1
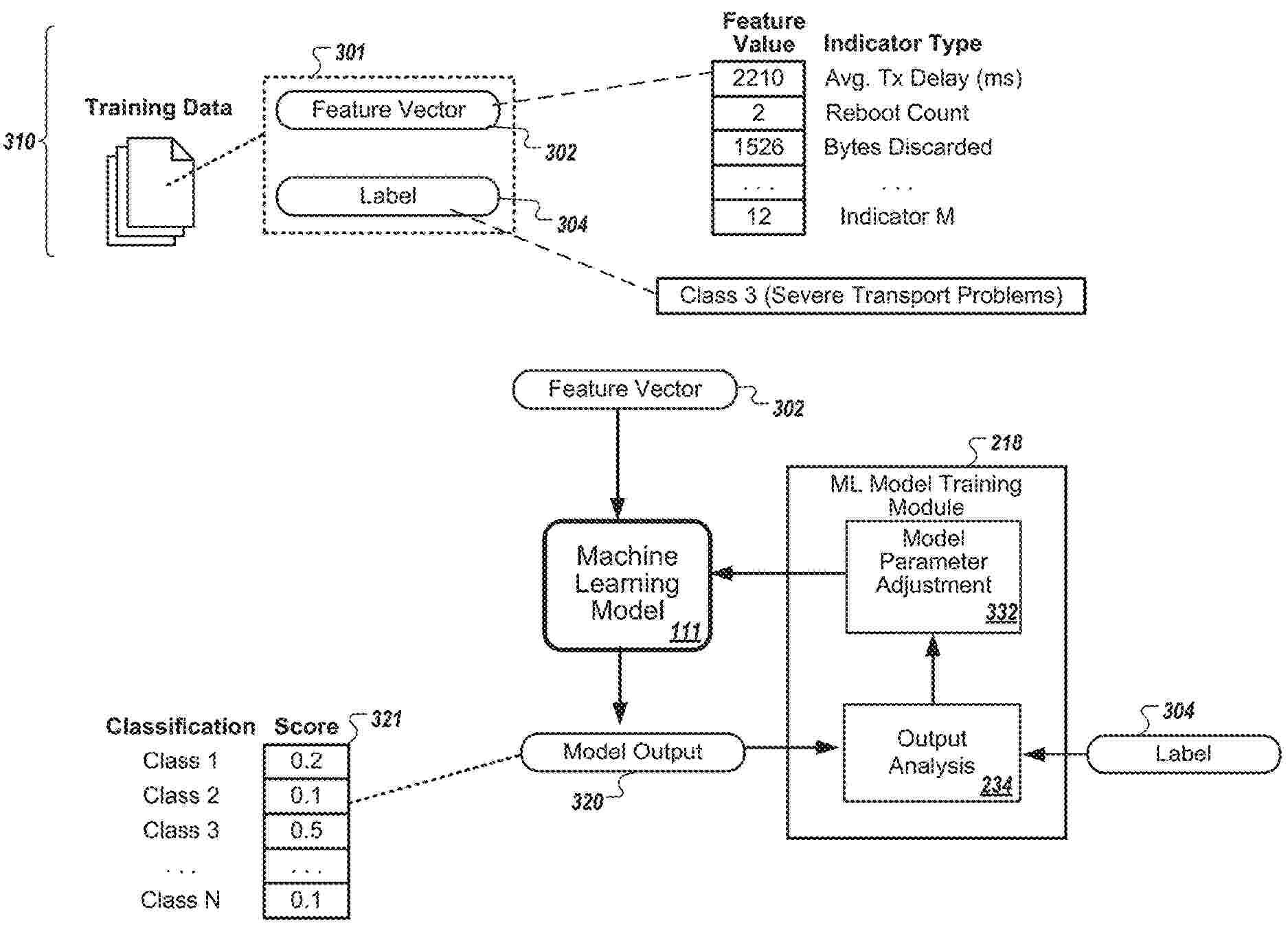
Methods, systems, and apparatus, including computer programs encoded on computer-storage media, for using machine learning to detect and correct satellite terminal performance limitations. In some implementations, a system retrieves data indicating labels for clusters of network performance anomalies. The system generates a set of training data to train a machine learning model, the set of training data being generated by assigning the labels for the clusters to sets of performance indicators used to generate the clusters. The system trains a machine learning model to predict classifications for communication devices based on input of performance indicators for the communication devices. The system determines a classification for the communication device based on output that the trained machine learning model generates.
 BOPI
BOPI
 Sede Electrónica
Sede Electrónica