Si deseas distinguir tus productos, servicios o ambos de los de otra empresa, es posible que necesites una marca o nombre comercial. Descubre qué son, en qué consiste su procedimiento de registro y qué implica.

Información sobre los plazos de presentación de solicitudes de transformación de marcas de la Unión Europea en marca nacional española. Más información


Si tienes un nuevo dispositivo, producto o procedimiento que resuelva un problema técnico o tenga una ventaja práctica, existen distintas formas de protegerlo en España y en otros países. Descubre cómo hacerlo.

¿Tu innovación reside en la estética, la ornamentación o la apariencia de tu producto? Protégela mediante un diseño industrial. Descubre qué derechos confiere el registro y cómo realizar la tramitación.

Las patentes publicadas en todo el mundo son una valiosa fuente de información científica, técnica y comercial.
Los Bonos 1 (no aplicable en España), 2 (Marcas y Diseños) y 3 (patentes nacionales, patentes europeas, informes tecnológicos de patentes y búsquedas retrospectivas) se encuentran cerrados desde el 20/08/2025. La solicitud del Bono 4 sigue abierta. Más adelante se informará sobre la reapertura de estos Bonos

Si eres emprendedor/a o una empresa y quieres potenciar y mejorar la rentabilidad de tu negocio protegiendo de forma adecuada los activos intangibles de tu organización, en este espacio encontrarás lo necesario.



 34
resultados
34
resultados
 Última actualización
06/10/2025 [07:12:00]
Última actualización
06/10/2025 [07:12:00]


Resumen de: US2025308512A1
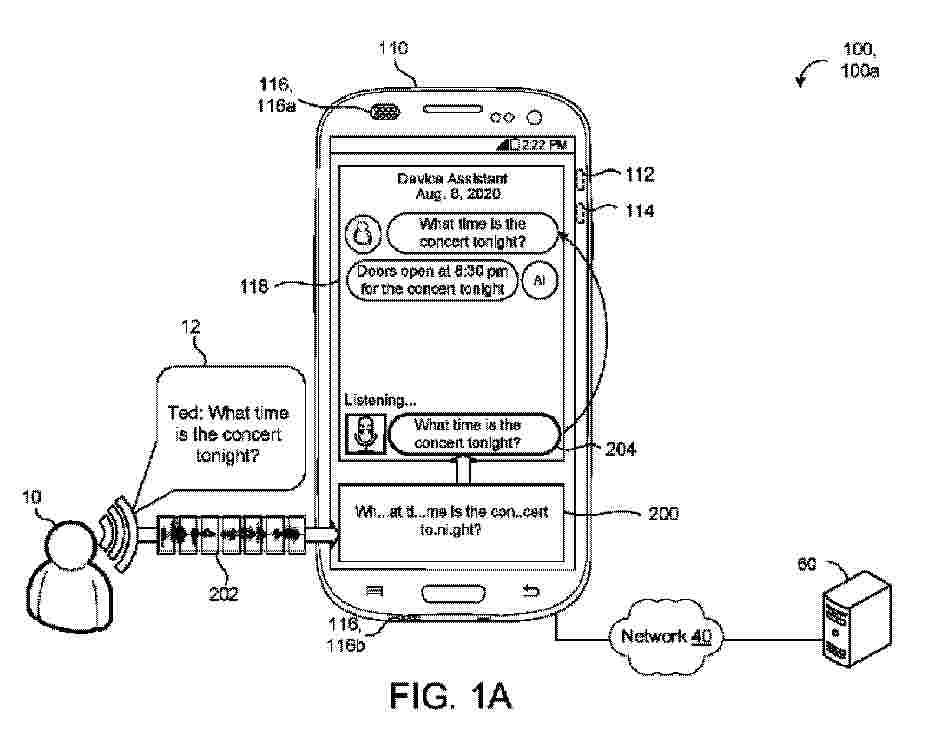
A method of text-only and semi-supervised training for deliberation includes receiving training data including unspoken textual utterances that are each not paired with any corresponding spoken utterance of non-synthetic speech, and training a deliberation model that includes a text encoder and a deliberation decoder on the unspoken textual utterances. The method also includes receiving, at the trained deliberation model, first-pass hypotheses and non-causal acoustic embeddings. The first-pass hypotheses is generated by a recurrent neural network-transducer (RNN-T) decoder for the non-causal acoustic embeddings encoded by a non-causal encoder. The method also includes encoding, using the text encoder, the first-pass hypotheses generated by the RNN-T decoder, and generating, using the deliberation decoder attending to both the first-pass hypotheses and the non-causal acoustic embeddings, second-pass hypotheses.

Resumen de: US2025305834A1
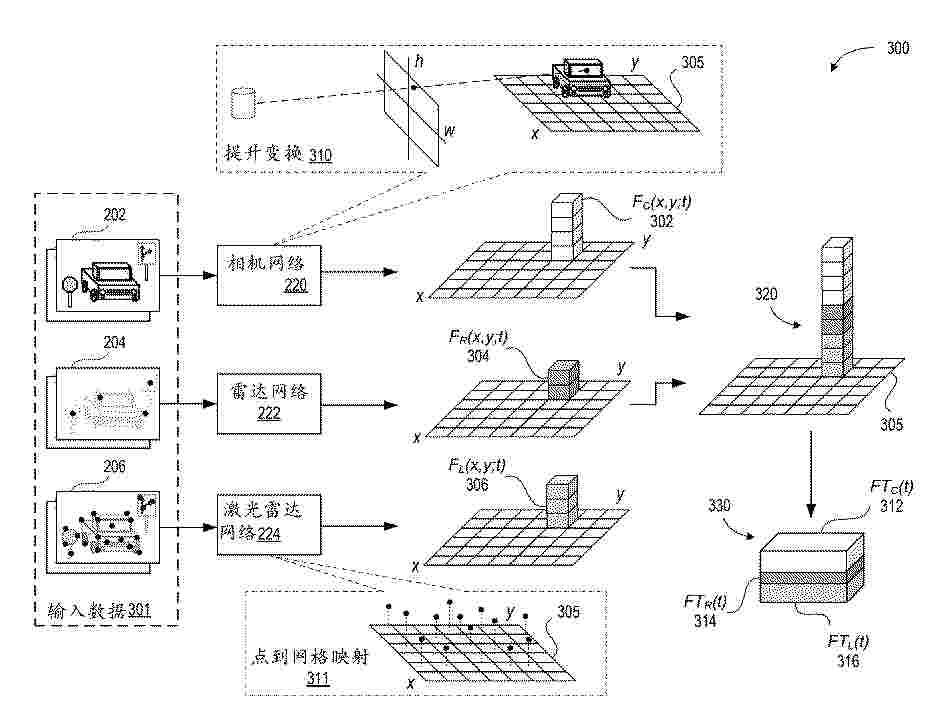
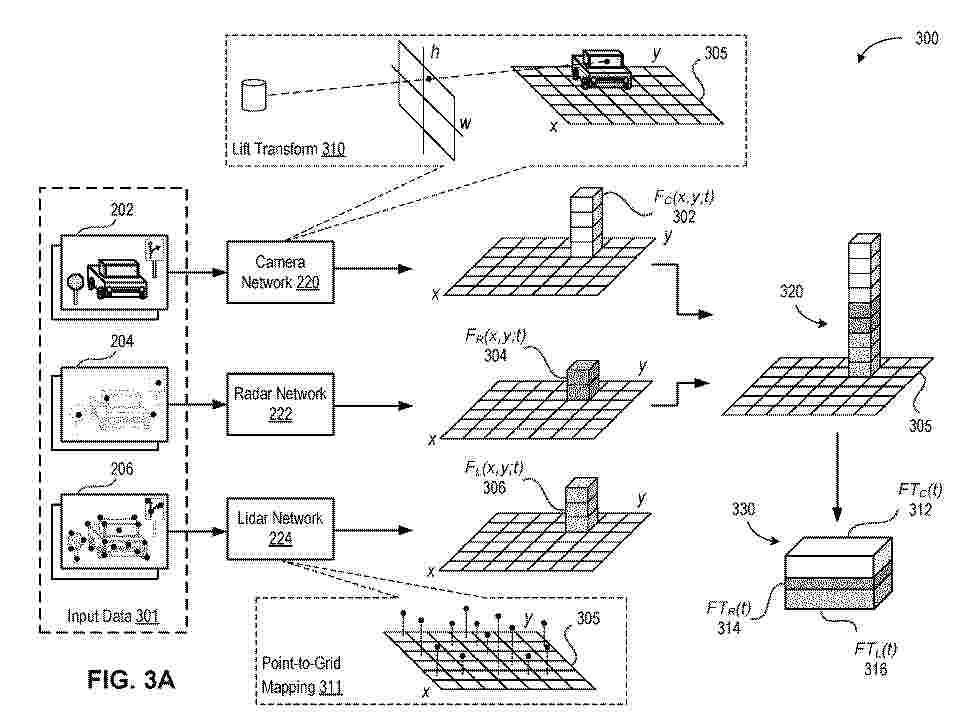
The disclosed systems and techniques facilitate efficient detection and navigation of reduced drivability areas in driving environments. The disclosed techniques include, obtaining, using a sensing system of a vehicle, a set of camera images, a set of radar images, and/or a set of lidar images of an environment. The techniques further include generating, using a first neural network (NN), camera feature(s) characterizing the camera images, generating, using a second NN, radar features characterizing the radar images, and/or generating, using a third NN, lidar feature(s) characterizing the lidar images. The techniques further include processing the camera feature(s), the radar feature(s), and the lidar feature(s) to obtain an indication of a reduced drivability area in the environment.
Resumen de: US2025305836A1
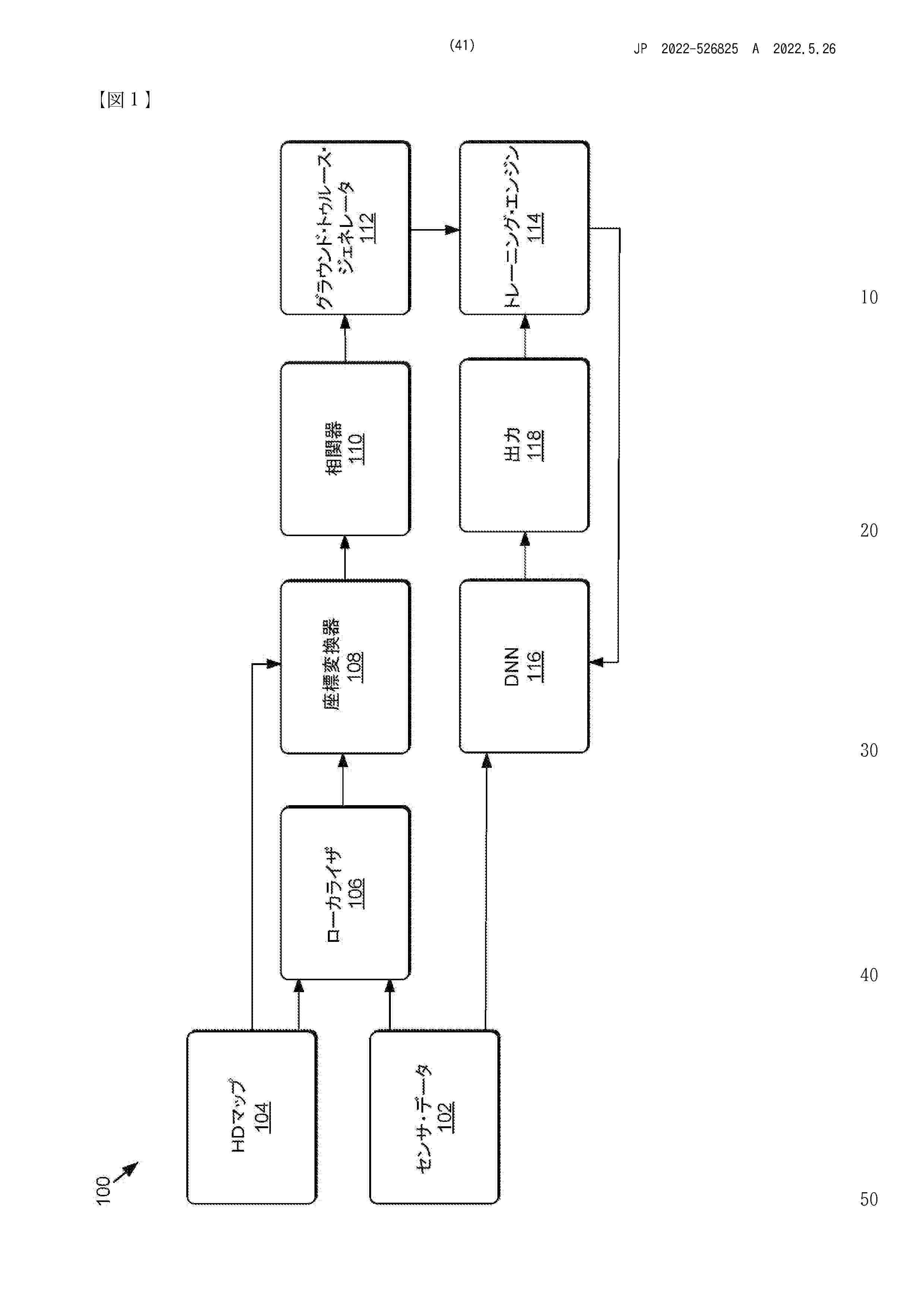
In various examples, training sensor data generated by one or more sensors of autonomous machines may be localized to high definition (HD) map data to augment and/or generate ground truth data—e.g., automatically, in embodiments. The ground truth data may be associated with the training sensor data for training one or more deep neural networks (DNNs) to compute outputs corresponding to autonomous machine operations-such as object or feature detection, road feature detection and classification, wait condition identification and classification, etc. As a result, the HD map data may be leveraged during training such that the DNNs—in deployment—may aid autonomous machines in navigating environments safely without relying on HD map data to do so.
Resumen de: WO2025207036A1
A method and apparatus for extracting commands between a controller and an operator, the method comprising: receiving a command and a response to the command; extracting an instruction from the command using a trained neural network model that processes text in a bidirectional manner; comparing the extracted instruction from the command and the response to the command to find text that is similar; and extracting text in the response to the command found to be most similar to the text in the extracted instruction of the command, wherein a fuzzy matching algorithm is used for comparing the extracted instruction of the command and the response to the command to find text that is similar, wherein the fuzzy matching algorithm compares a span of the extracted instruction of the command with a span of the response to the command and calculates a similarity score for the two compared spans.
Resumen de: US2025308219A1
A user directed video generation method and system obtains a natural language-based communication from a user requesting that a computer-implemented system generate a virtual environment that is based on a description that is provided by the user. The description is interpreted by a trained neural network. Representations of pixel patterns are generated by a trained neural network in accordance with the interpretation. The representations of the pixel patterns are evaluated for consistency with context and then selected based on the evaluation. The selected pixel patterns are embodied in a video stream that is provided to the user. Natural language that may be in audio form may be generated to accompany the video stream.
Resumen de: US2025308121A1
In various examples, animations may be generated using audio-driven body animation synthesized with voice tempo. For example, full body animation may be driven from an audio input representative of recorded speech, where voice tempo (e.g., a number of phonemes per unit time) may be used to generate a 1D audio signal for comparing to datasets including data samples that each include an animation and a corresponding 1D audio signal. One or more loss functions may be used to compare the 1D audio signal from the input audio to the audio signals of the datasets, as well as to compare joint information of joints of an actor between animations of two or more data samples, in order to identify optimal transition points between the animations. The animations may then be stitched together—e.g., using interpolation and/or a neural network trained to seamlessly stitch sequences together—using the transition points.
Resumen de: US2025307729A1
A system and method for variational annealing to solve financial optimization problems is provided. The financial optimization problem is encoded as objective function represented in terms of an energy function. An autoregressive neural network is trained to minimize the cost function via variational emulation of classical or quantum annealing. Optimal solutions to the financial optimization problem are obtained after a stopping criterion is set. An optimal solution may be selected according to user defined metrics, and optionally applied to a real-world system associated with the financial optimization problem.
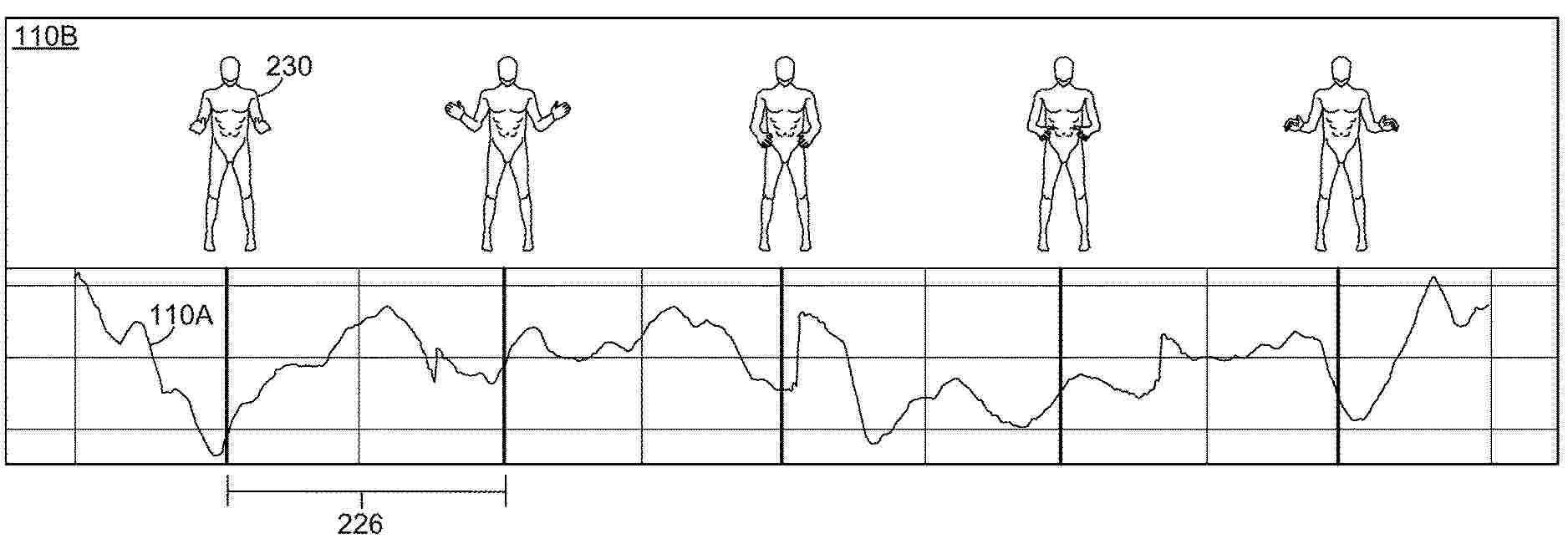
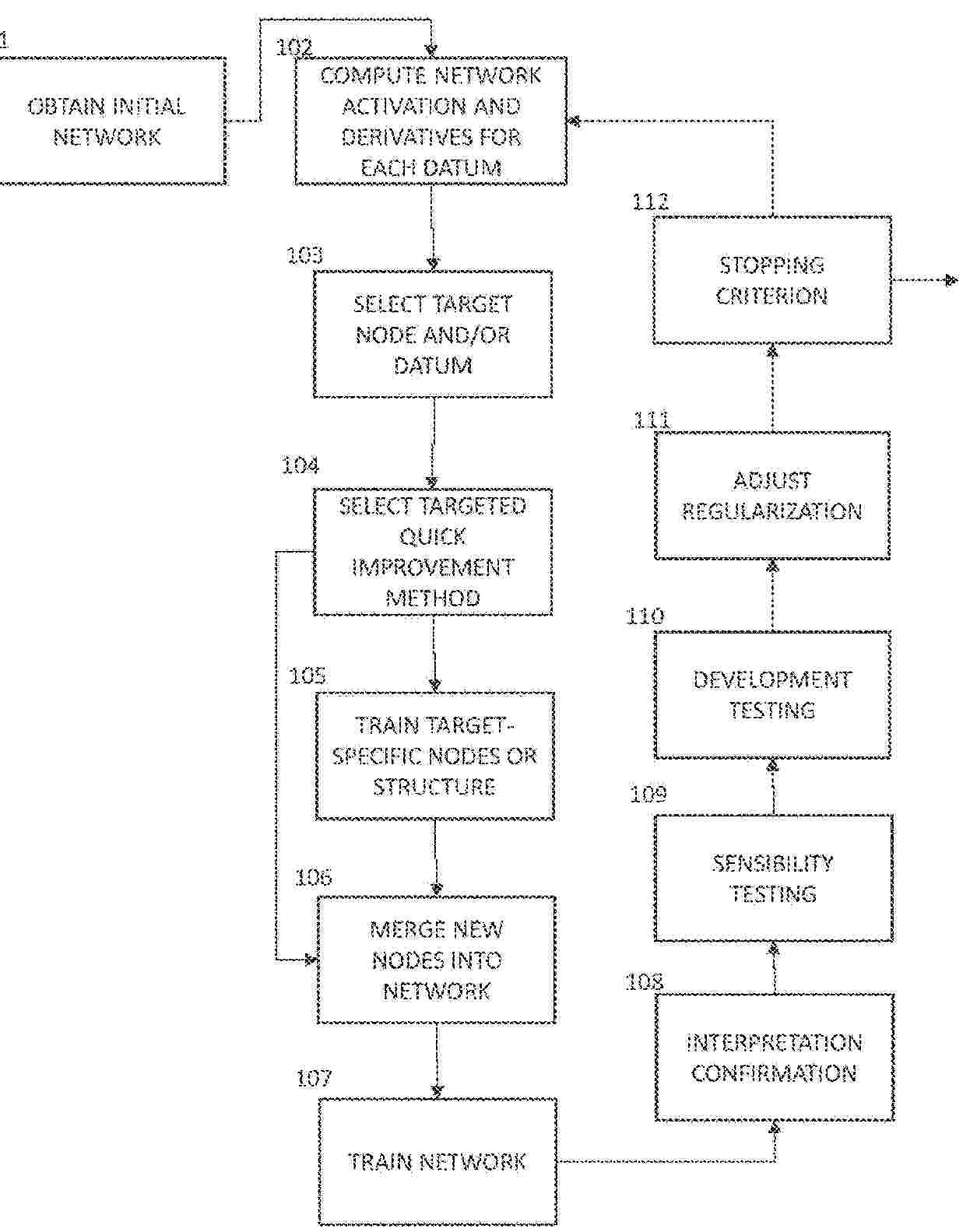
Resumen de: US2025307604A1
Computer systems and computer-implemented methods train a neural network, by:(a) computing for each datum in a set of training data, activation values for nodes in the neural network and estimates of partial derivatives of an objective function for the neural network for the nodes in the neural network; (b) selecting a target node of the neural network and/or a target datum in the set of training data; (c) selecting a target-specific improvement model for the neural network, wherein the target-specific improvement model, when added to the neural network, improves performance of the neural network for the target node and/or the target datum, as the case may be; (d) training the target-specific improvement model; (e) merging the target-specific improvement model with the neural network to form an expanded neural network; and (f) training the expanded neural network.
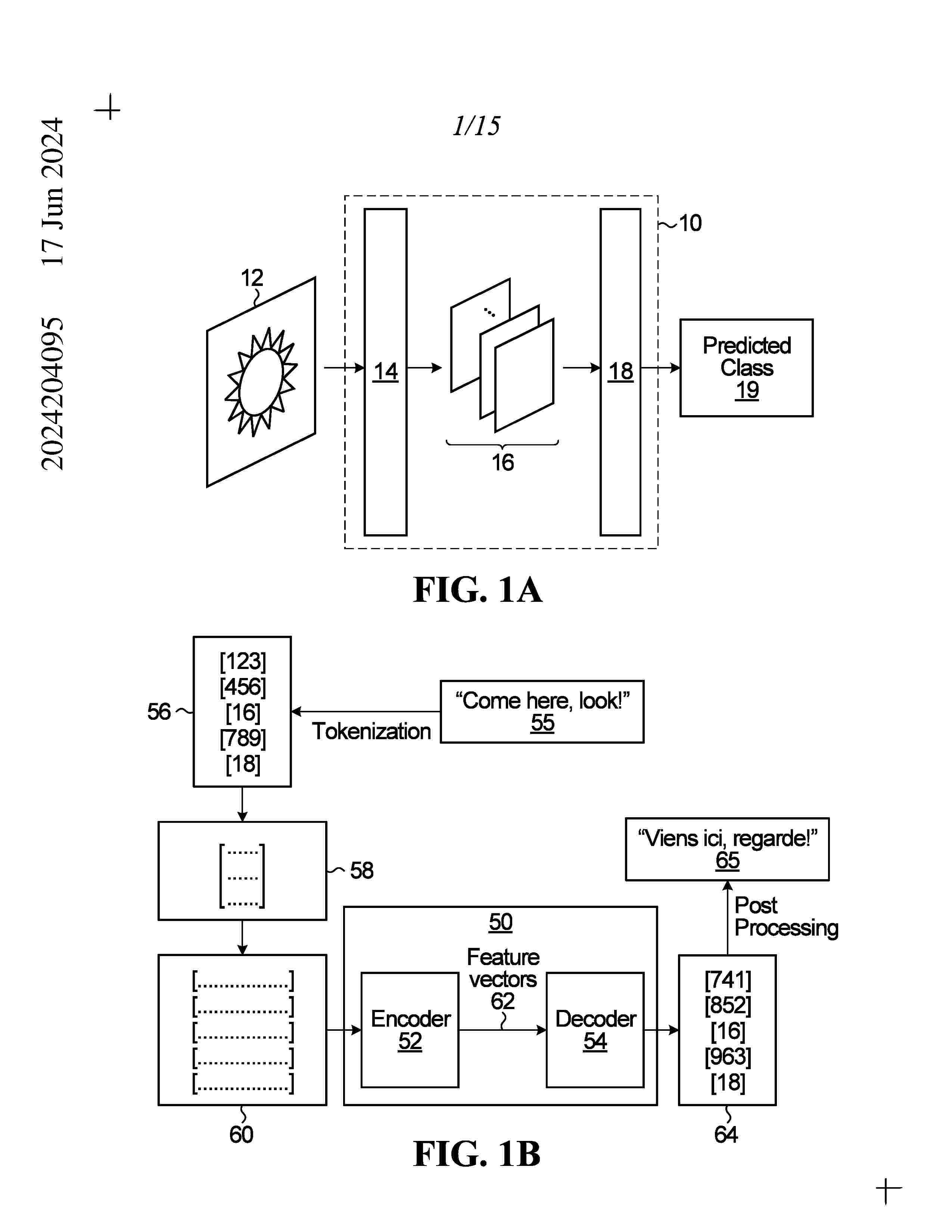
Resumen de: AU2024204095A1
Typical classifiers must be trained on a large input sample to accurately classify inputs. In addition, if a new classification category needs to be added to a taxonomy after the classifier has already been trained to classify within the taxonomy, the classifier must be recreated and retrained to classify within the updated taxonomy. To address at least these technical problems with classifiers, a generative language model may be used to perform classification. A generative language model is a machine learning model that generates language, typically in the form of a textual response to a data input. A generative language model may utilize a large neural network to determine probabilities for a next token of a sequence of text conditional on previous or historical tokens in the sequence of text. An LLM is an example of a generative language model. Typical classifiers must be trained on a large input sample to accurately classify inputs. In addition, if a new classification category needs to be added to a taxonomy after the classifier has already been trained to classify within the taxonomy, the classifier must be recreated and retrained to classify within the updated taxonomy. To address at least these technical problems with classifiers, a generative language model may be used to perform classification. A generative language model is a machine learning model that generates language, typically in the form of a textual response to a data input. A generative language model may
Resumen de: GB2639568A
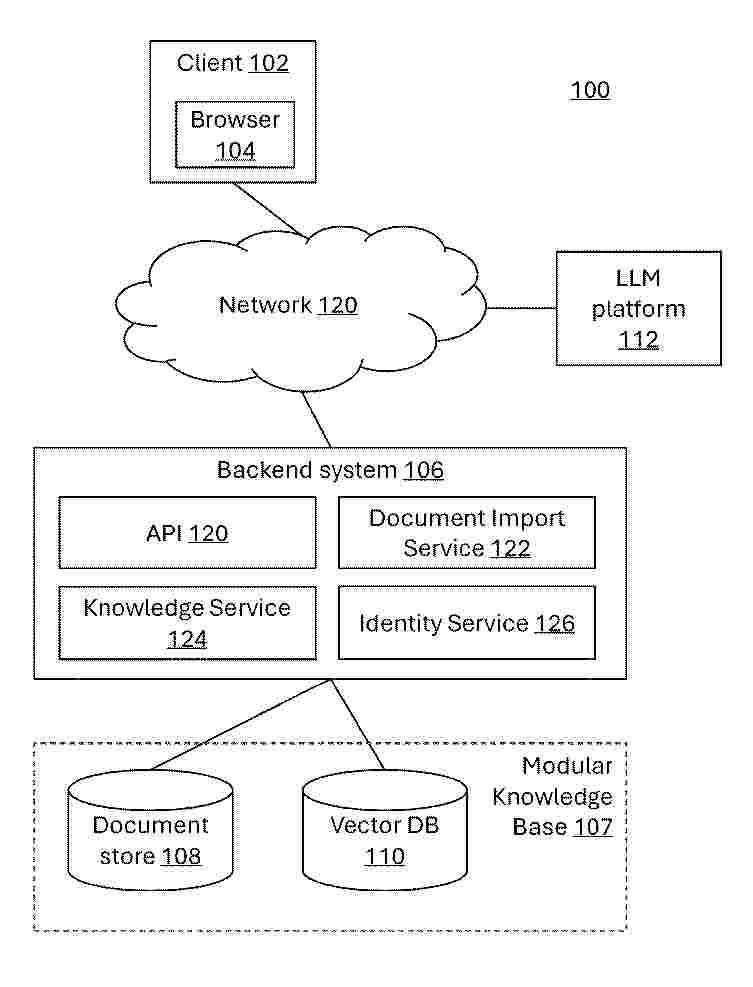
Disclosed is a method of processing a query using a trained artificial neural network (ANN) implementing a large language model (LLM). A database of documents is maintained for use in processing queries, the database defining multiple repositories, each containing one or more documents. The documents in the database are processed to generate, for each repository, a vector store comprising vector embeddings encoding information obtained from documents of the repository. A user inputs a query string and a selection of one or more of the repositories to be used to process the query. A query embedding corresponding to the query string is generated and the vector stores corresponding to each selected repository are searched using the query embedding to identify one or more vectors that are relevant to the query. An LLM query is formulated to include the query string, a query context comprising information determined based on the identified relevant vectors and a predefined LLM prompt. The LLM is invoked with the LLM query as input whereby the LLM query is processed using the ANN to generate an LLM output. A query response is provided to the user based on query response data received from the LLM.
Resumen de: EP4625249A1
A system and method for variational annealing to solve financial optimization problems is provided. The financial optimization problem is encoded as objective function represented in terms of an energy function. An autoregressive neural network is trained to minimize the cost function via variational emulation of classical or quantum annealing. Optimal solutions to the financial optimization problem are obtained after a stopping criterion is set. An optimal solution may be selected according to user defined metrics, and optionally applied to a real-world system associated with the financial optimization problem.
Resumen de: EP4624980A1
The disclosed systems and techniques facilitate efficient detection and classification of traffic signs in driving environments. The disclosed techniques include, obtaining, using a sensing system of a vehicle, a set of camera images, a set of radar images, and a set of lidar images of an environment. The techniques further include generating, using a first neural network (NN), camera feature(s) characterizing the camera images, generating, using a second NN, radar features characterizing the radar images, and generating, using a third NN, lidar feature(s) characterizing the lidar images. The techniques further include processing the camera feature(s), the radar feature(s), and the lidar feature(s) to obtain an indication of a reduced drivability area in the environment.
Resumen de: US2025299041A1
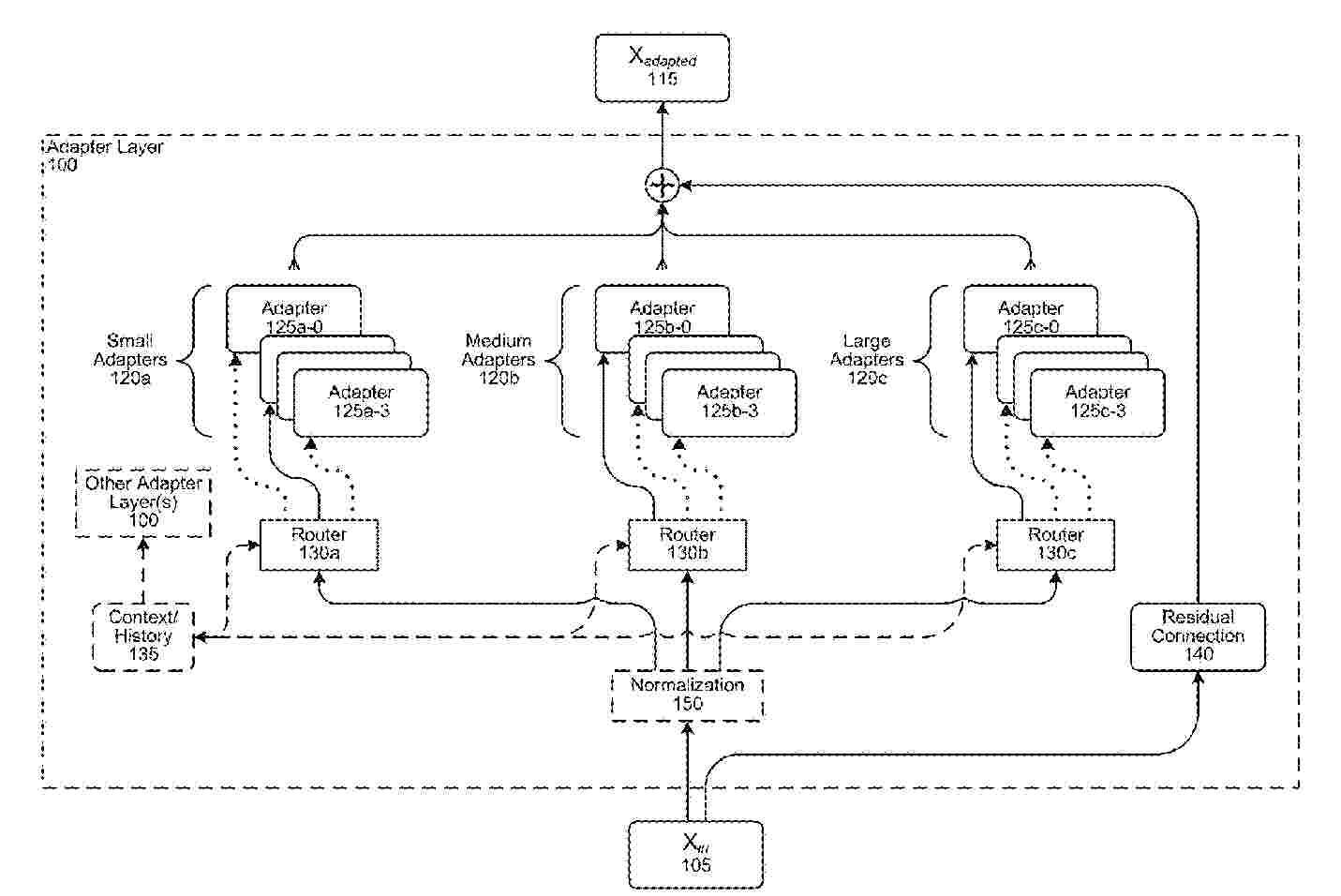
An adapter layer may be used to customize a machine learning component by transforming data flowing into, out of, and/or within the machine learning component. The adapter layer may include a number of neural network components, or “adapters,” configured to perform a transformation on input data. Neural network components may be configured into adapter groups. A router component can, based on the input data, select one or more neural network components for transforming the input data. The input layer may combine the results of any such transformations to yield adapted data. Different adapter groups can include adapters of different complexity (e.g., involving different amounts of computation and/or latency). Thus, the amount of computation or latency added by an adapter layer can be reduced for simpler transformations of the input data.
Resumen de: US2025299295A1
Apparatuses, systems, and techniques to enhance video are disclosed. In at least one embodiment, one or more neural networks are used to create a higher resolution video using upsampled frames from a lower resolution video.
Resumen de: US2025299051A1
An information processing apparatus configured to execute inference using a convolutional neural network, including: an obtainment unit configured to obtain target data from data for inference inputted in the information processing apparatus; and a computation unit configured to execute convolutional computation and output computation result data, the convolutional computation using computation data including the target data obtained by the obtainment unit and margin data different from the target data that is required to obtain the computation result data in a predetermined size, in which the obtainment unit obtains first data, which is a part of the margin data, from a data group existing around the target data separately from the target data in the data for inference and doses not obtain second data, which is the margin data except the first data, from the data group.
Resumen de: US2025299032A1
In an example, an apparatus comprises a compute engine comprising a high precision component and a low precision component; and logic, at least partially including hardware logic, to receive instructions in the compute engine; select at least one of the high precision component or the low precision component to execute the instructions; and apply a gate to at least one of the high precision component or the low precision component to execute the instructions. Other embodiments are also disclosed and claimed.
Resumen de: EP4621769A2
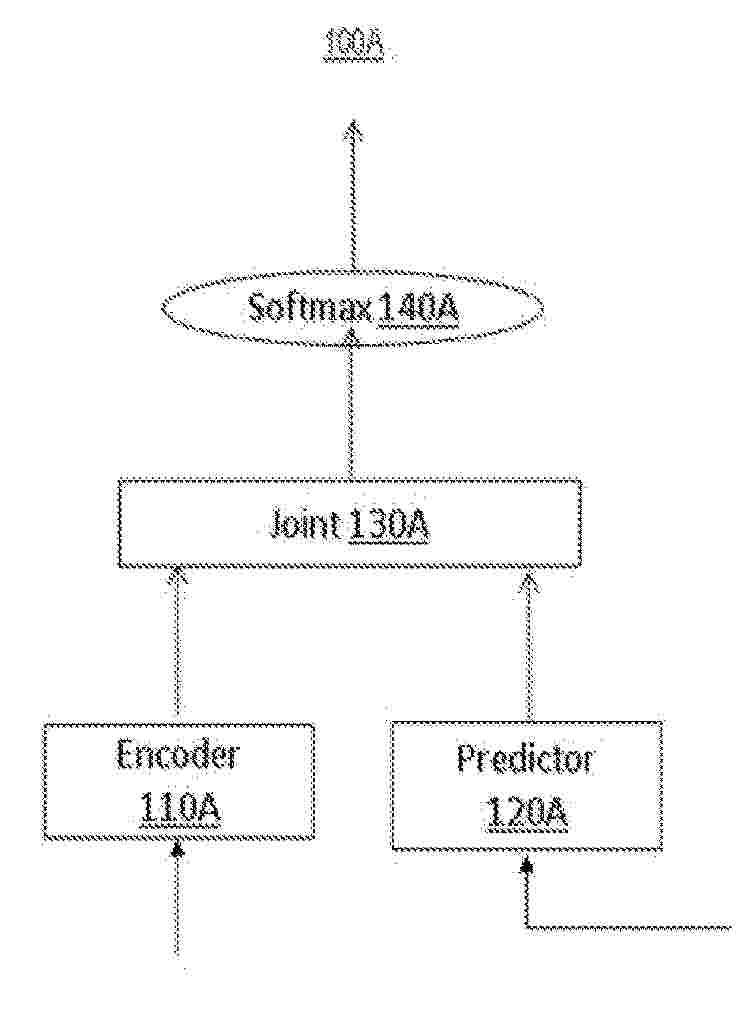
A computing system is configured to generate a transformer-transducer-based deep neural network. The transformer-transducer-based deep neural network comprises a transformer encoder network and a transducer predictor network. The transformer encoder network has a plurality of layers, each of which includes a multi-head attention network sublayer and a feed-forward network sublayer. The computing system trains an end-to-end (E2E) automatic speech recognition (ASR) model, using the transformer-transducer-based deep neural network. The E2E ASR model has one or more adjustable hyperparameters that are configured to dynamically adjust an efficiency or a performance of E2E ASR model when the E2E ASR model is deployed onto a device or executed by the device.
Resumen de: US2025291405A1
The present disclosure relates to an artificial neural network (ANN) computing system comprising: a buffer configured to store data indicative of input data received from an input device; an inference engine operative to process data from the buffer to generate an interest metric for the input data; and a controller. The controller is operative to control a mode of operation of the inference engine according to the interest metric for the input data.
Resumen de: US2025291828A1
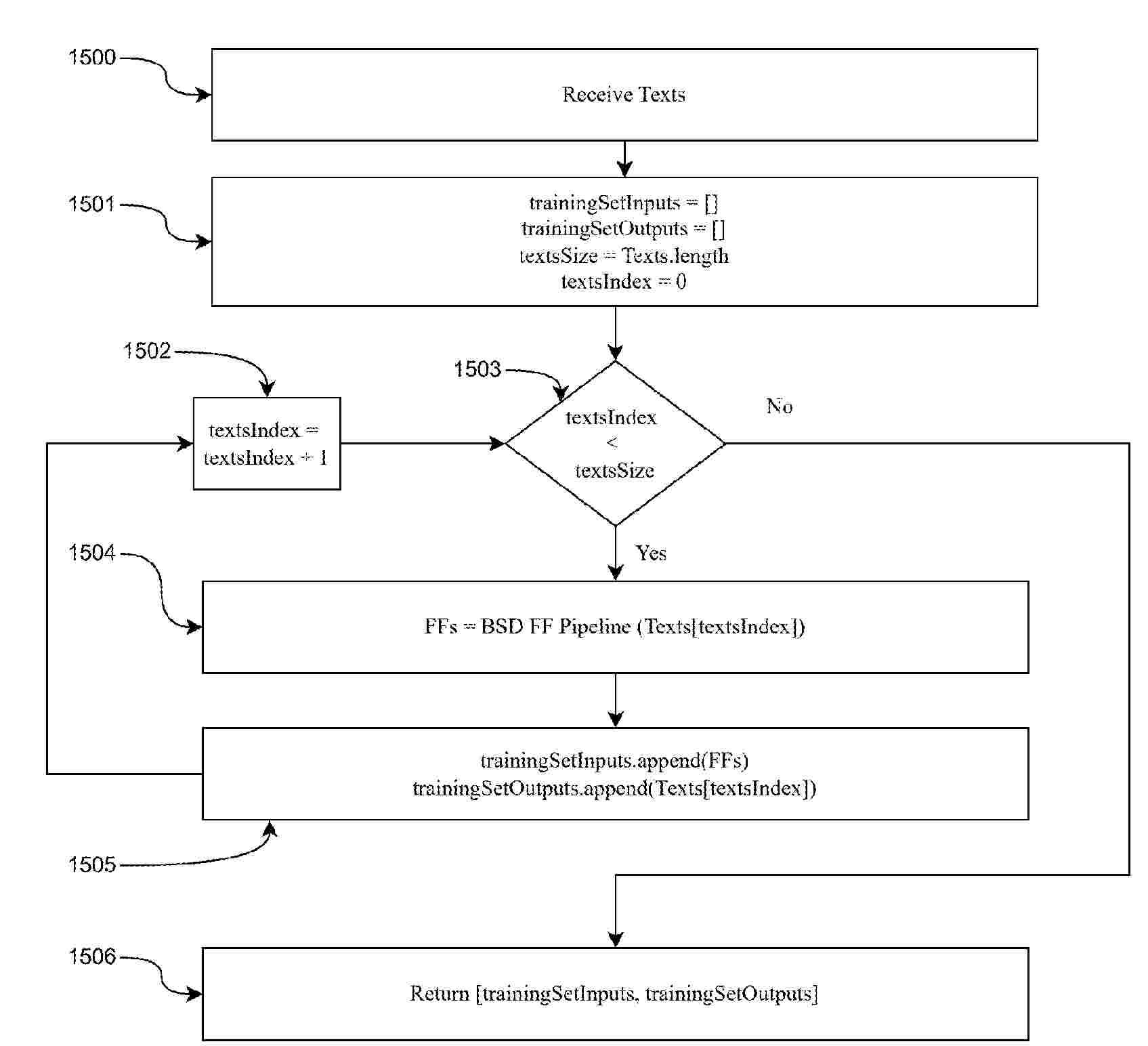
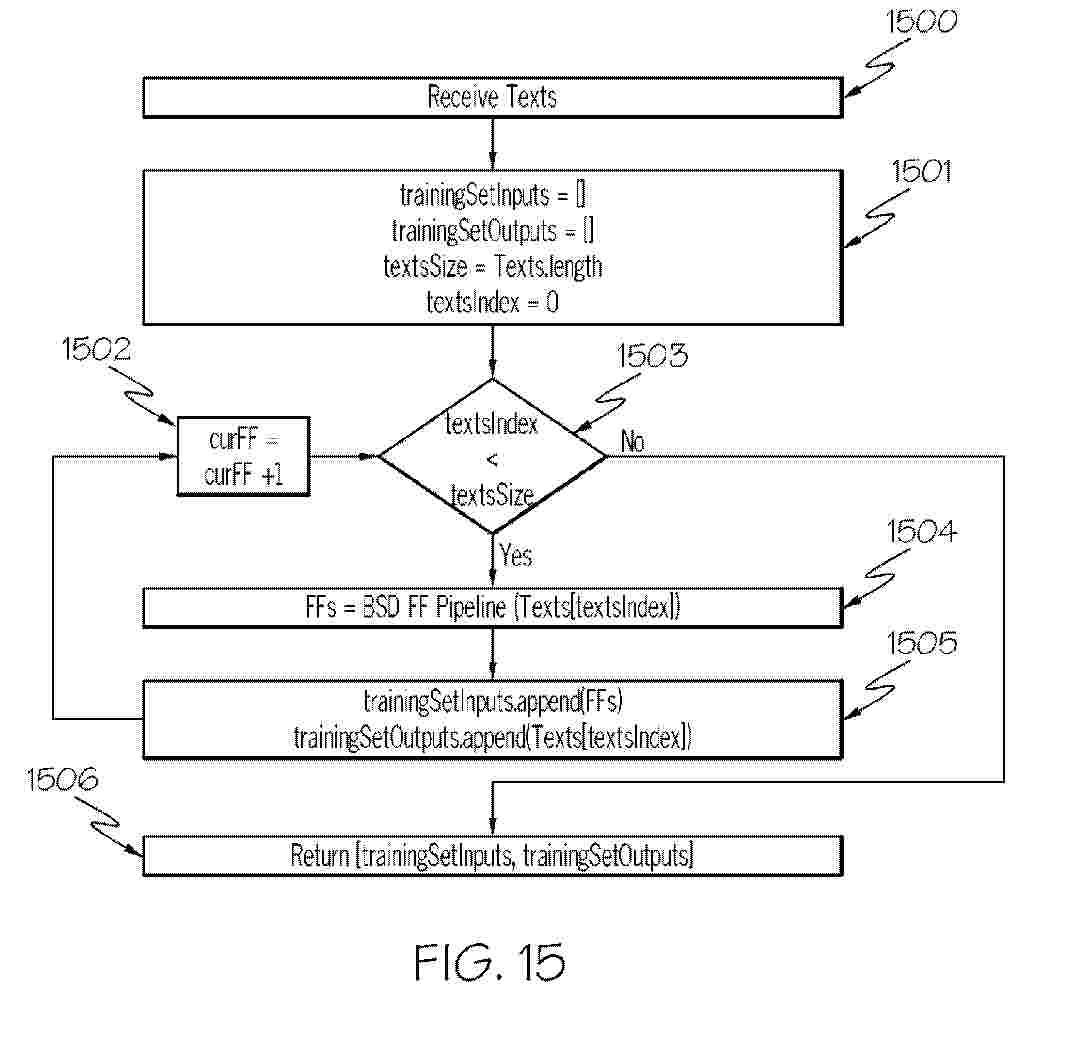
Systems and methods are described for obtaining accurate responses from large language models (LLMs) and chatbots, including for question and answering, exposition, and summarization. These systems and methods accomplish these objectives via use of noun phrase avoiding processes such as a noun phrase collision detection process, a query splitting process, and a topical splitting process as well as by use of formatted facts, formatted fact model correction interfaces (FF MCIs), bounded-scope deterministic (BSD) neural networks, processes and methods, and intelligent storage and retrieval (ISAR) systems and methods. These systems and methods avoid and bypass noun phrase collisions and correct for errors caused by noun phrase collisions so that hallucinations are eliminated from LLM responses.
Resumen de: US2025292065A1
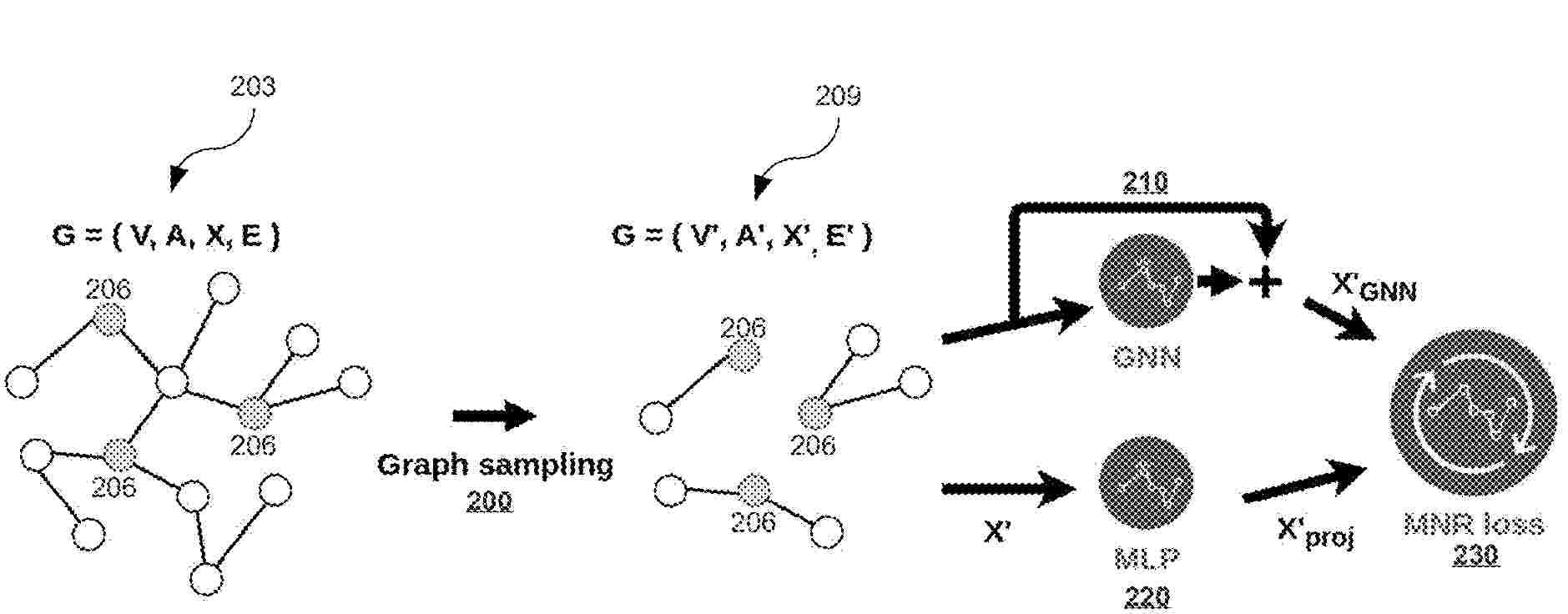
The present disclosure relates to entity resolution between graphs of entities and their relations. A language model (LM) and a graph neural network (GNN) may be iteratively trained. A plurality of first node embeddings for a plurality of nodes in a graph may be generated using the LM. A plurality of second node embeddings for the plurality of nodes based at least in part on the plurality of first node embeddings and the graph may be generated using the GNN. A first node and a second node of the plurality of nodes that both represent a particular entity may be identified based at least in part on a similarity between one of the plurality of second node embeddings associated with the first node and one of the plurality of second node embeddings associated with the second node
Resumen de: US2025292125A1
A computer-implemented video generation training method and system performs unsupervised training of neural networks using training sets that comprise images, which may be sequentially arranged as videos. The unsupervised training includes obscuring subsets of pixels that are within each of the images. During the training the neural networks automatically learn correspondences among subsets of pixels in the images. An instruction is received from a user and representations of pixel patterns are generated by the trained computer-implemented neural networks in response to the instruction. The pixel patterns are included within a video stream that is provided to the user.
Resumen de: US2025292044A1
To suppress an increase in processing time due to a load of inference processing while improving reading accuracy by the inference processing of machine learning. An optical information reading device includes a processor including: an inference processing part that inputs a code image to a neural network and executes inference processing of generating an ideal image corresponding to the code image; and a decoding processing part that executes first decoding processing of decoding the code image and second decoding processing of decoding the ideal image generated by the inference processing part. The processor executes the inference processing and the first decoding processing in parallel, and executes the second decoding processing after completion of the inference processing.
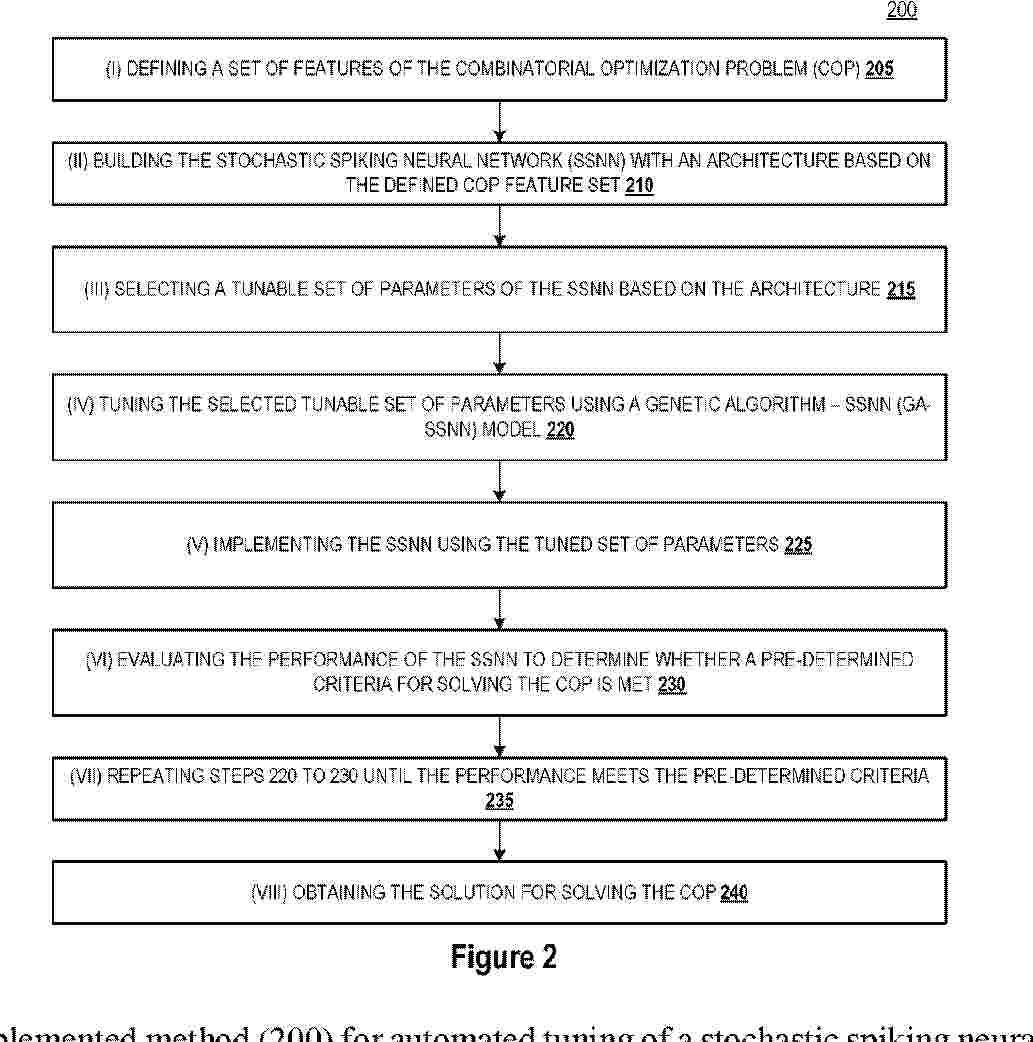
Resumen de: WO2025191315A1
A computer-implemented method (200) for automated tuning of a stochastic spiking neural network (SSNN) for solving a combinatorial optimization problem (COP). The method includes (i) defining (205) a set of features of the COP. The method further includes (ii) building (210) the SSNN with an architecture based on the defined COP feature set. The method further includes (iii) selecting (215) a tunable set of parameters of the SSNN based on the architecture. The method further includes (iv) tuning (220) the selected tunable set of parameters using using a genetic algorithm - SSNN (GA-SSNN) model. The method further includes (v) implementing (225) the SSNN using the tuned set of parameters. The method further includes (vi) evaluating (230) the performance of the SSNN to determine whether a pre-determined criteria for solving the COP is met. The method further includes (vii) repeating (235) steps (iv) to (vi) until the performance meets the pre-determined criteria. The method further includes (viii) obtaining (240) the solution for solving the COP.
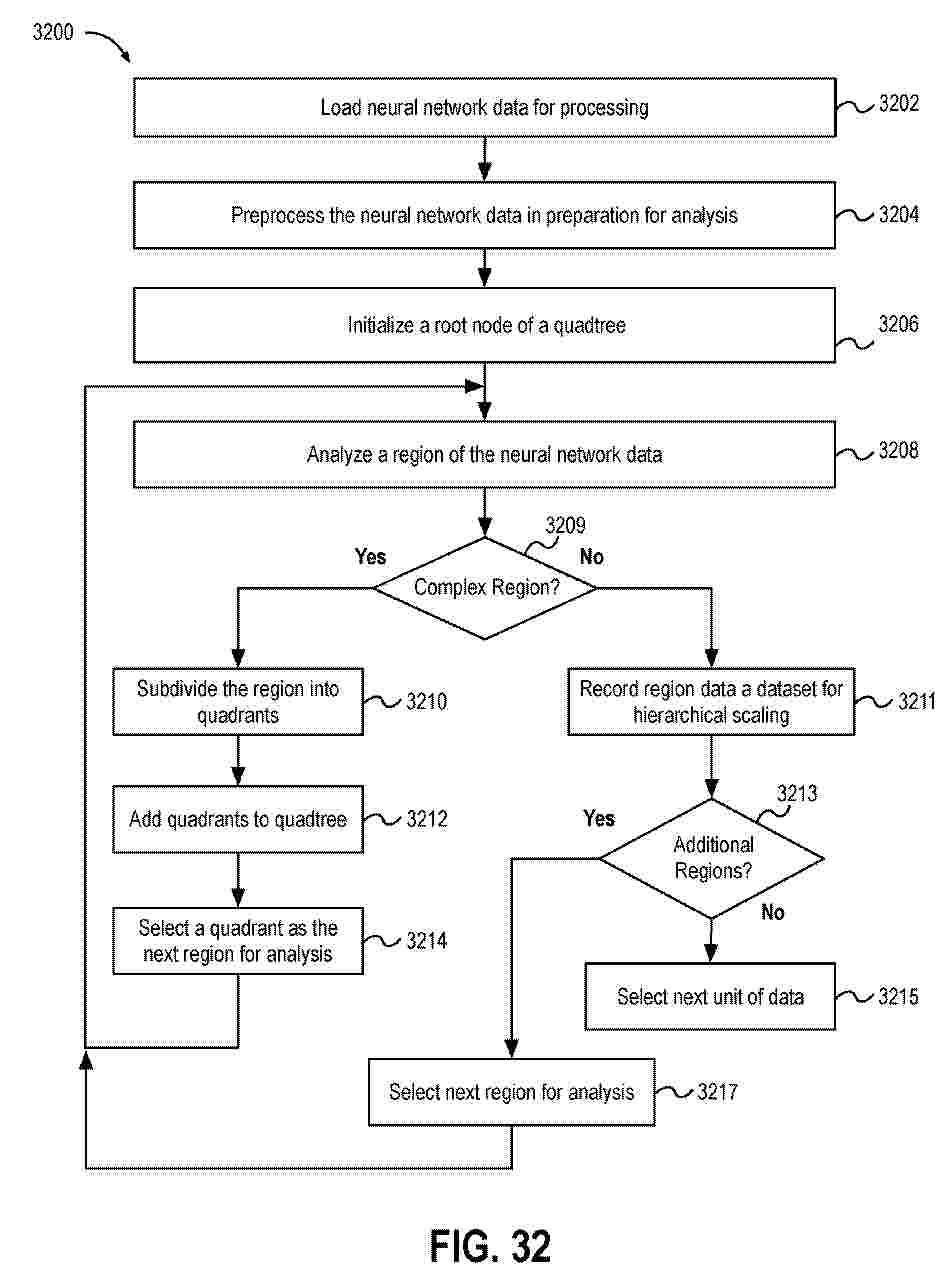
Resumen de: US2025292362A1
Embodiments described herein provide techniques to facilitate hierarchical scaling when quantizing neural network data to a reduced-bit representation. The techniques includes operations to load a hierarchical scaling map for a tensor associated with a neural network, partition the tensor into a plurality of regions that respectively include one or more subregions based on the hierarchical scaling map, hierarchically scale numerical values of the tensor based on a first scale factor and second scale factor via the matrix accelerator circuitry, the first scale factor based on a statistical measure of a subregion of numerical values of within a region of the plurality of regions and the second scale factor based on a statistical measure of the region that includes the subregion, and generate a quantized representation of the tensor via quantization of hierarchically scaled numerical values.
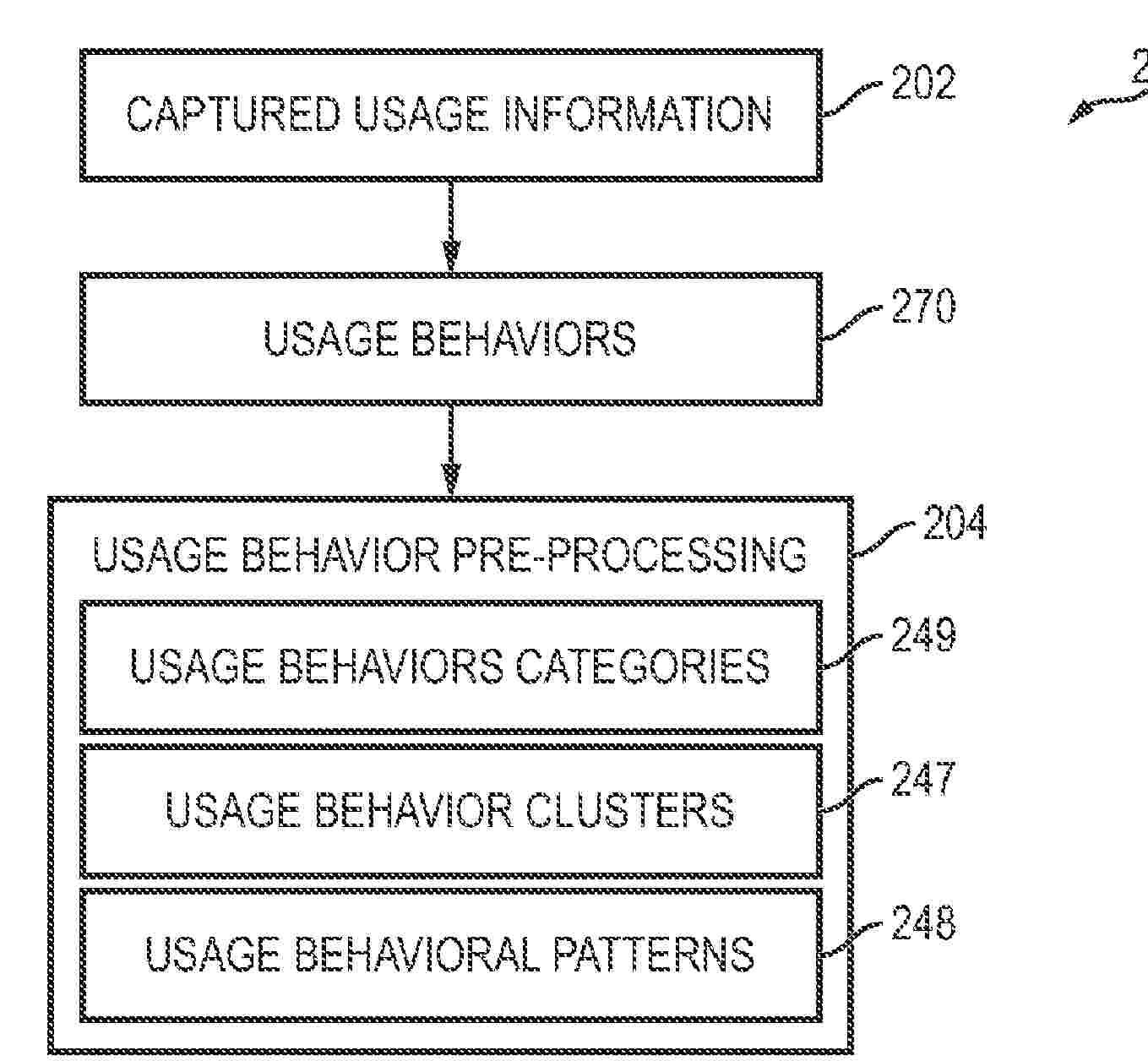
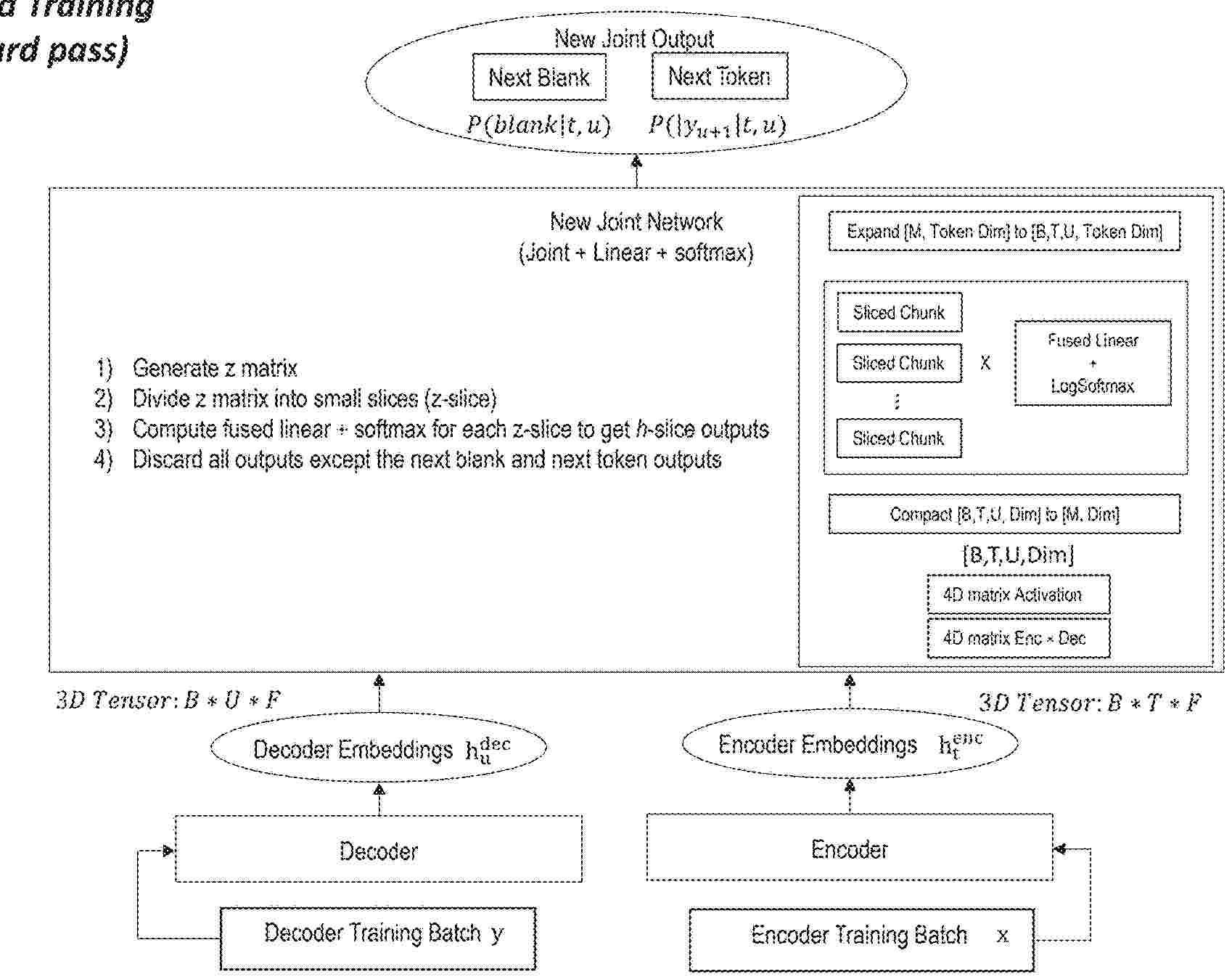
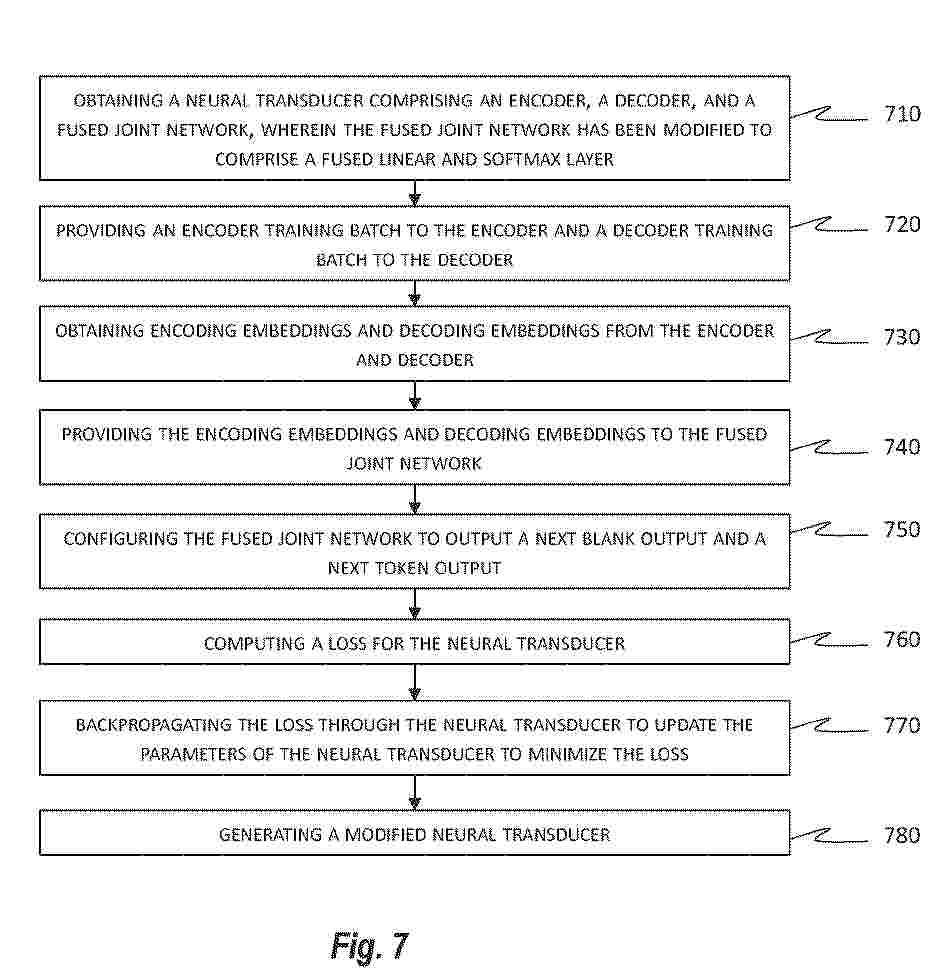
Resumen de: US2025292764A1
Efficient training is provided for models comprising RNN-T (recurrent neural network transducers). The model transducers comprise an encoder, a decoder, and a fused joint network. The fused joint network receives encoding and decoding embeddings from the encoder and decoder. During training, the model stores the probability data for the next blank output and the next token at each time step rather than storing all probabilities for all possible outputs. This can significantly reduce requirements for memory storage, while still preserving the relevant information required to calculate the loss that will be backpropagated through the neural transducer during training to update the parameters of the neural transducer and to generate a trained or modified neural transducer. The computation of embeddings can also be divided into small slices and some of the utterance padding used for the training samples can also be removed to further reduce the memory storage requirements.
Resumen de: WO2025193562A1
Systems and methods are described for obtaining accurate responses from large language models (LLMs) and chatbots, including for question and answering, exposition, and summarization. These systems and methods accomplish these objectives via use of noun phrase avoiding processes such as a noun phrase collision detection process, a query splitting process, and a topical splitting process as well as by use of formatted facts, formatted fact model correction interfaces (FF MCIs), bounded-scope deterministic (BSD) neural networks, processes and methods, and intelligent storage and retrieval (ISAR) systems and methods. These systems and methods avoid and bypass noun phrase collisions and correct for errors caused by noun phrase collisions so that hallucinations are eliminated from LLM responses.
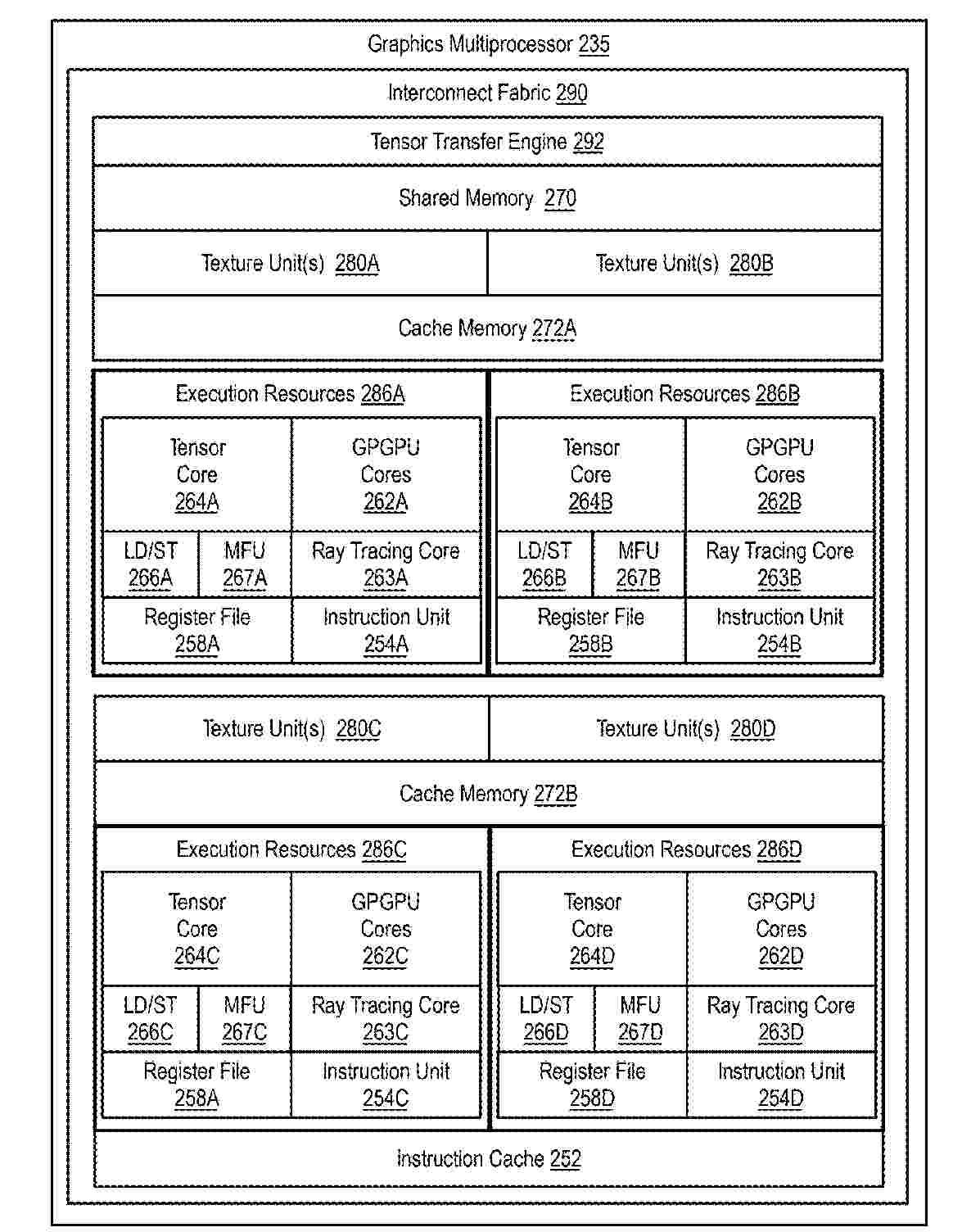
Resumen de: US2025292357A1
One embodiment provides a graphics processor comprising a base die including a plurality of chiplet sockets and a plurality of chiplets coupled with the plurality of chiplet sockets. At least one of the plurality of chiplets include a graphics processing cluster including a plurality of processing resources. The plurality of processing resources including a matrix accelerator having circuitry to perform operations for a neural network in which model topology and weights of the neural network are encrypted. The matrix accelerator configured to execute commands of a command buffer, the commands generated based on a decomposition of the model topology of the neural network and access encrypted weights in memory of the graphics processor via circuitry configured to decrypt the encrypted weights via a key that is programmed to the hardware of the circuitry.
Resumen de: WO2025190472A1
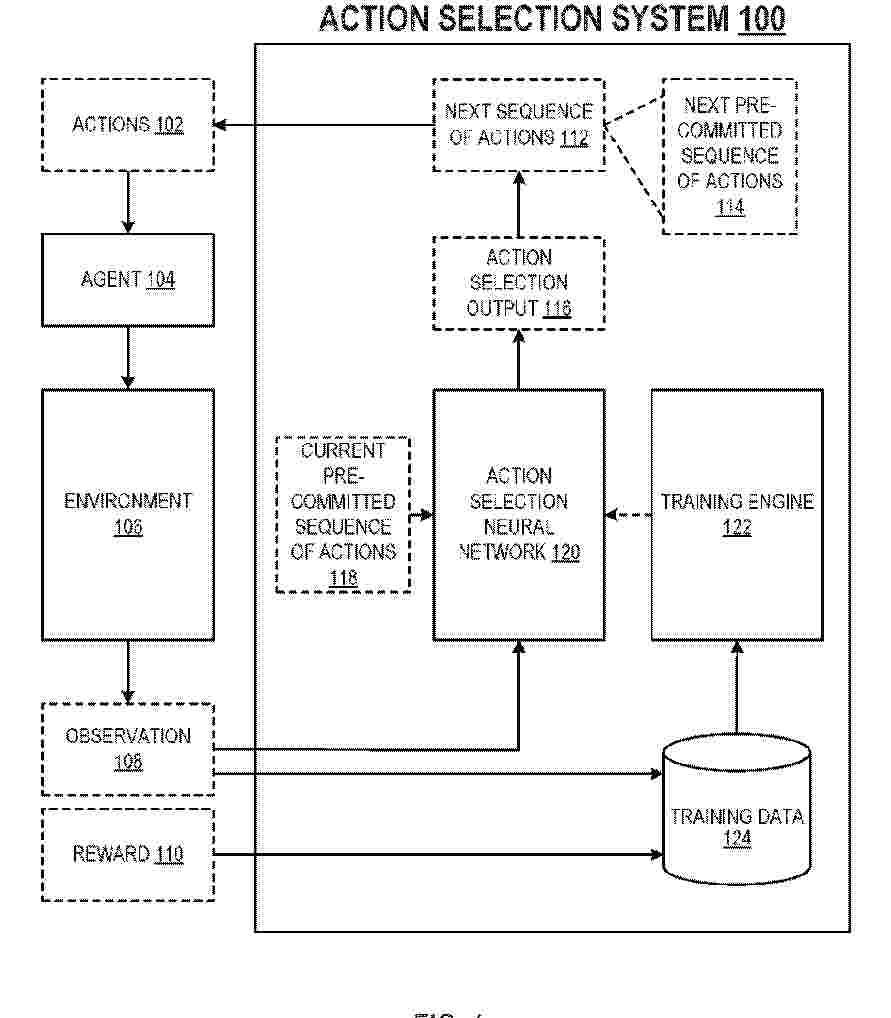
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for controlling an agent interacting with an environment by selecting actions to be performed by the agent using an action selection neural network. In one aspect, a method comprises, at each of a plurality of action selection iterations: receiving data identifying a current observation and a current pre-committed sequence of actions; processing a network input comprising: (i) the current observation, and (ii) the current pre-committed sequence of actions, using the action selection neural network, to generate an action selection output; selecting a next sequence of actions based on the action selection output, wherein the next sequence of actions comprises a predefined number of actions that define a next pre-committed sequence of actions; and causing the agent to perform the next pre-committed sequence of actions after the agent has performed the current pre-committed sequence of actions.
Resumen de: EP4618073A2
Efficient training is provided for models comprising RNN-T (recurrent neural network transducers). The model transducers comprise an encoder, a decoder, and a fused joint network. The fused joint network receives encoding and decoding embeddings from the encoder and decoder. During training, the model stores the probability data for the next blank output and the next token at each time step rather than storing all probabilities for all possible outputs. This can significantly reduce requirements for memory storage, while still preserving the relevant information required to calculate the loss that will be backpropagated through the neural transducer during training to update the parameters of the neural transducer and to generate a trained or modified neural transducer. The computation of embeddings can also be divided into small slices and some of the utterance padding used for the training samples can also be removed to further reduce the memory storage requirements.
Resumen de: EP4617952A1
Embodiments described herein provide techniques to facilitate hierarchical scaling when quantizing neural network data to a reduced-bit representation. The techniques includes operations to load a hierarchical scaling map for a tensor associated with a neural network, partition the tensor into a plurality of regions that respectively include one or more subregions based on the hierarchical scaling map, hierarchically scale numerical values of the tensor based on a first scale factor and second scale factor via the matrix accelerator circuitry, the first scale factor based on a statistical measure of a subregion of numerical values of within a region of the plurality of regions and the second scale factor based on a statistical measure of the region that includes the subregion, and generate a quantized representation of the tensor via quantization of hierarchically scaled numerical values.
Resumen de: WO2025189097A1
Provided herein are methods of training a model for cardiac phenotyping using cardiac ultrasonography images and videos adaptable to point-of-care acquisition. The method includes providing an echocardiogram dataset; labeling the echocardiogram dataset with at least one condition of interest; splitting the echocardiogram dataset into a derivation dataset and a testing dataset; initializing a deep neural network (DNN); automating the extraction of echocardiographic view quality metrics; generating natural and synthetic augmentations of cardiac images and videos; and implementing a loss function that accounts for variations in view quality to train noise-adjusted computer vision models for phenotyping at the point-of-care. Also provided herein is a method of cardiac phenotyping employing the model.
Resumen de: US2025284541A1
Examples described herein relate to stateful inference of a neural network. A plurality of feature map segments each has a first set of values stored in a compressed manner. The first sets of values at least partially represent an extrinsic state memory of the neural network after processing of a previous input frame. Operations are performed with respect to each feature map segment. The operations include decompressing and storing the first set of values. The operations further include updating at least a subset of the decompressed first set of values based on a current input frame to obtain a second set of values. The second set of values is compressed and stored. Memory resources used to store the decompressed first set of values is released. The second sets of values at least partially represent the extrinsic state memory of the neural network after processing of the current input frame.
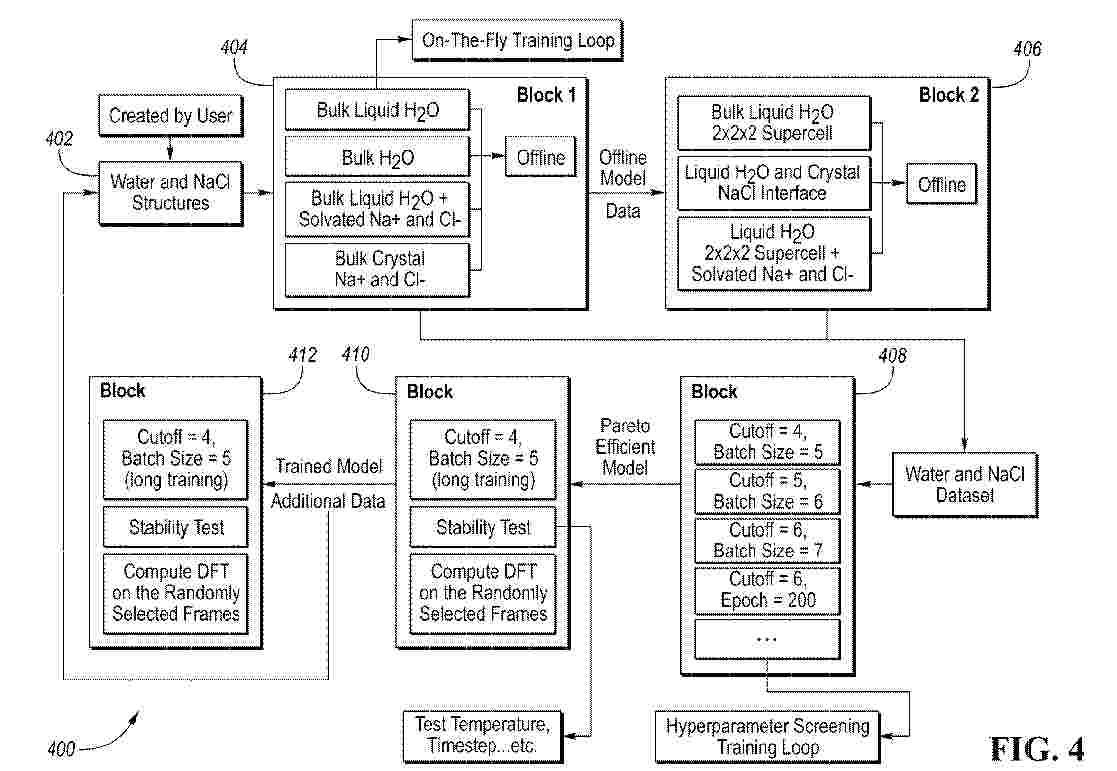
Resumen de: GB2639070A
An iterative machine learning interatomic potential (MLIP) training method which includes training a first multiplicity of first MLIP models in a first iteration of a training loop; training a second multiplicity of second MLIP models in a second iteration of the training loop in parallel with the first training step; then combining the first MLIP models and the second MLIP models to create an iteratively trained MLIP configured to predict one or more values of a material. The values may be total energy, atomic forces, atomic stresses, atomic charges, and/or polarization. The MLIP may be a Gaussian Process (GP) based MLIP (e.g. FLARE). The MLIP may be a graph neural network (GNN) based MLIP (e.g. NequIP or Allegro). A third MLIP model may be used when predicted confidence or predicted uncertainty pass a threshold. The MLIP models may use different sets of hyperparameters. The first and second MLIP models may use different starting atomic structures or different chemical compositions. Iteration can involve selection of the model with the lowest error rate. Combination can be to account for atomic environment overlap or atomic changes in energies. Training may be terminated when a model is not near a Pareto front.
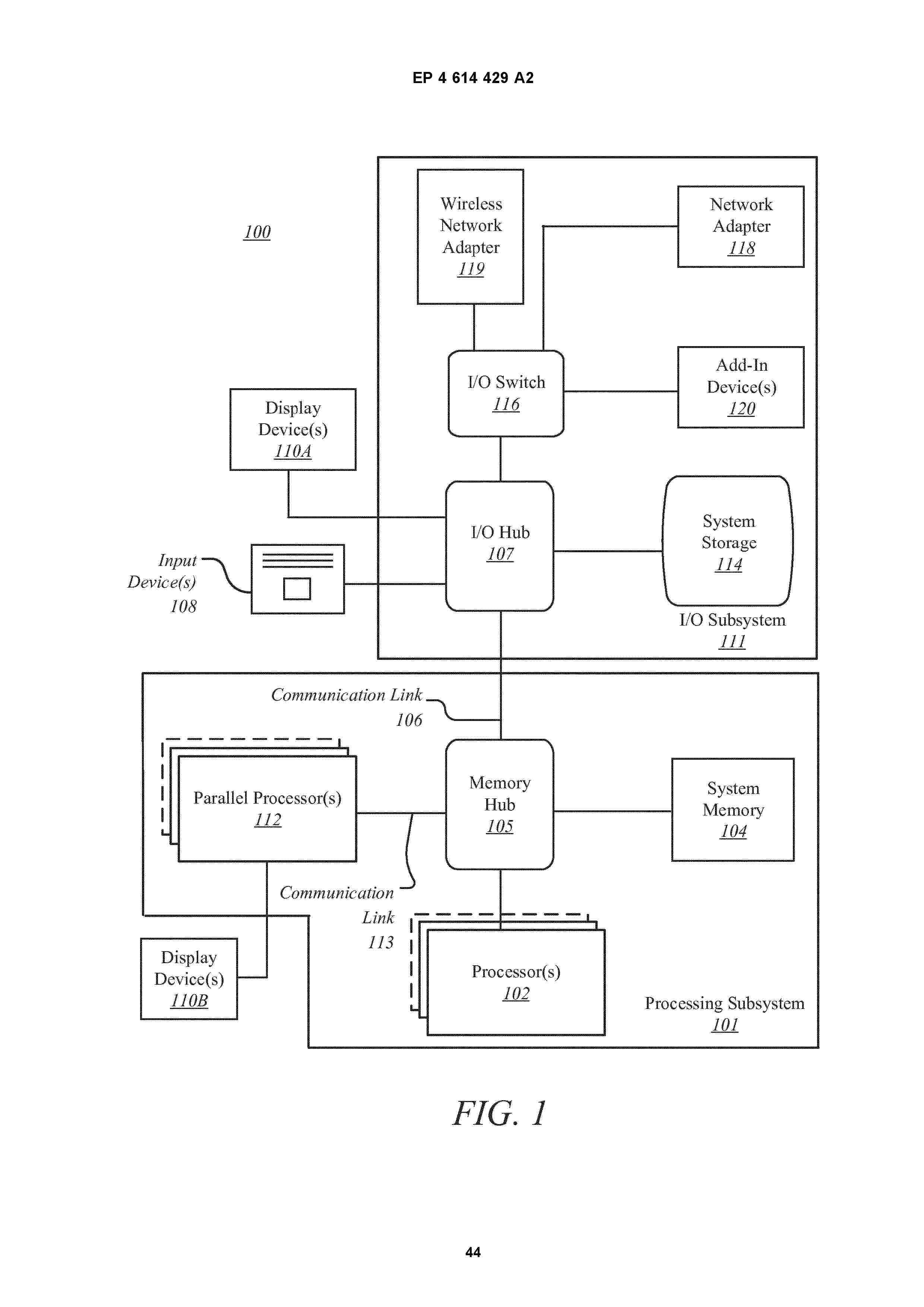
Nº publicación: EP4614429A2 10/09/2025
Solicitante:
INTEL CORP [US]
INTEL Corporation
Resumen de: EP4614429A2
An apparatus of embodiments, as described herein, includes a processing system including a graphics processor, the graphics processor including a plurality of processing resources for inference employment in neural networks, the plurality of processing resources configured to be partitioned into a plurality of physical resource slices; and a scheduler to receive specification of a limitation on usage of the plurality of processing resources by a plurality of application processes and schedule shared resources in the processing system for a plurality of application processes associated with a plurality of clients of the processing system according to the limitation on usage. The processing system has a capability to limit usage of the plurality of processing resources of the graphics processor by the plurality of application processes based on the specification of the limitation on usage. The limitation on usage of the plurality of processing resources of the graphics processor includes to limit execution of threads of each application process of the plurality of application processes to a specified portion of available threads provided by the plurality of processing resources of the graphics processor, the specified portion being less than all available threads provided by the plurality of processing resources of the graphics processor.
 BOPI
BOPI
 Sede Electrónica
Sede Electrónica