Si deseas distinguir tus productos, servicios o ambos de los de otra empresa, es posible que necesites una marca o nombre comercial. Descubre qué son, en qué consiste su procedimiento de registro y qué implica.

Información sobre los plazos de presentación de solicitudes de transformación de marcas de la Unión Europea en marca nacional española. Más información


Si tienes un nuevo dispositivo, producto o procedimiento que resuelva un problema técnico o tenga una ventaja práctica, existen distintas formas de protegerlo en España y en otros países. Descubre cómo hacerlo.

¿Tu innovación reside en la estética, la ornamentación o la apariencia de tu producto? Protégela mediante un diseño industrial. Descubre qué derechos confiere el registro y cómo realizar la tramitación.

Las indicaciones geográficas protegen el nombre de un producto originario de una zona geográfica, a la cual le debe una determinada calidad, reputación u otra característica. Descubre qué son, en qué consiste su procedimiento de registro y qué beneficios conceden.

Las patentes publicadas en todo el mundo son una valiosa fuente de información científica, técnica y comercial.

Si eres emprendedor/a o una empresa y quieres potenciar y mejorar la rentabilidad de tu negocio protegiendo de forma adecuada los activos intangibles de tu organización, en este espacio encontrarás lo necesario.



 133
resultados
133
resultados
 Última actualización
14/07/2026 [07:58:00]
Última actualización
14/07/2026 [07:58:00]



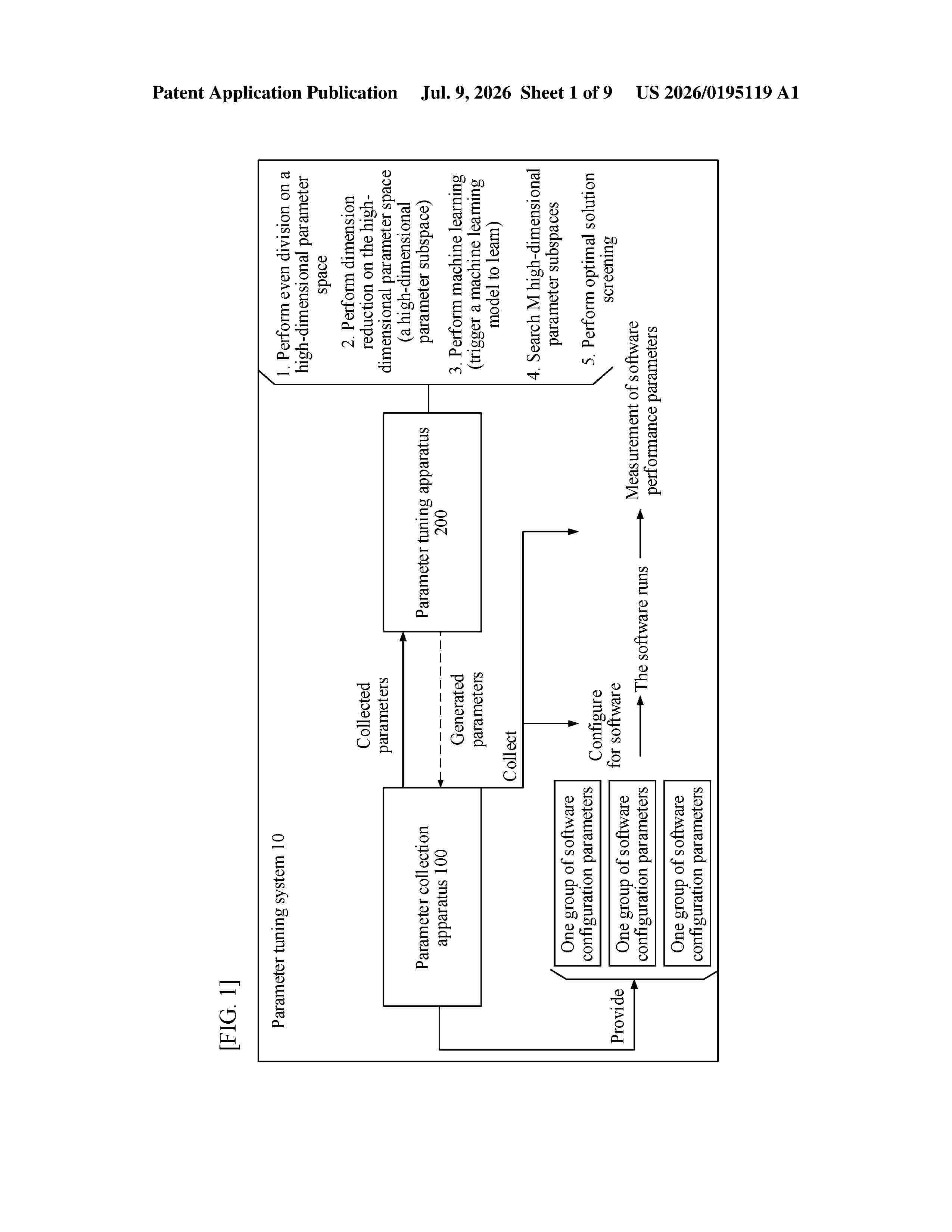
Resumen de: US20260195119A1
0000 This application provides example parameter tuning methods. In one example method, a high-dimensional parameter space is divided based on one or more groups of software configuration parameters that are configured for software and corresponding software performance parameters, to form M high-dimensional parameter subspaces, where the M high-dimensional parameter subspaces satisfy: a similarity between data in any one of the high-dimensional parameter subspaces is greater than a similarity threshold, and a difference between amounts of data included in any two of the high-dimensional parameter subspaces is not greater than an amount threshold. M machine learning models are invoked to learn the M high-dimensional parameter subspaces. A target high-dimensional parameter subspace is selected from the M high-dimensional parameter subspaces, and a to-be-configured software configuration parameter is determined by using a machine learning model corresponding to the target high-dimensional parameter subspace.

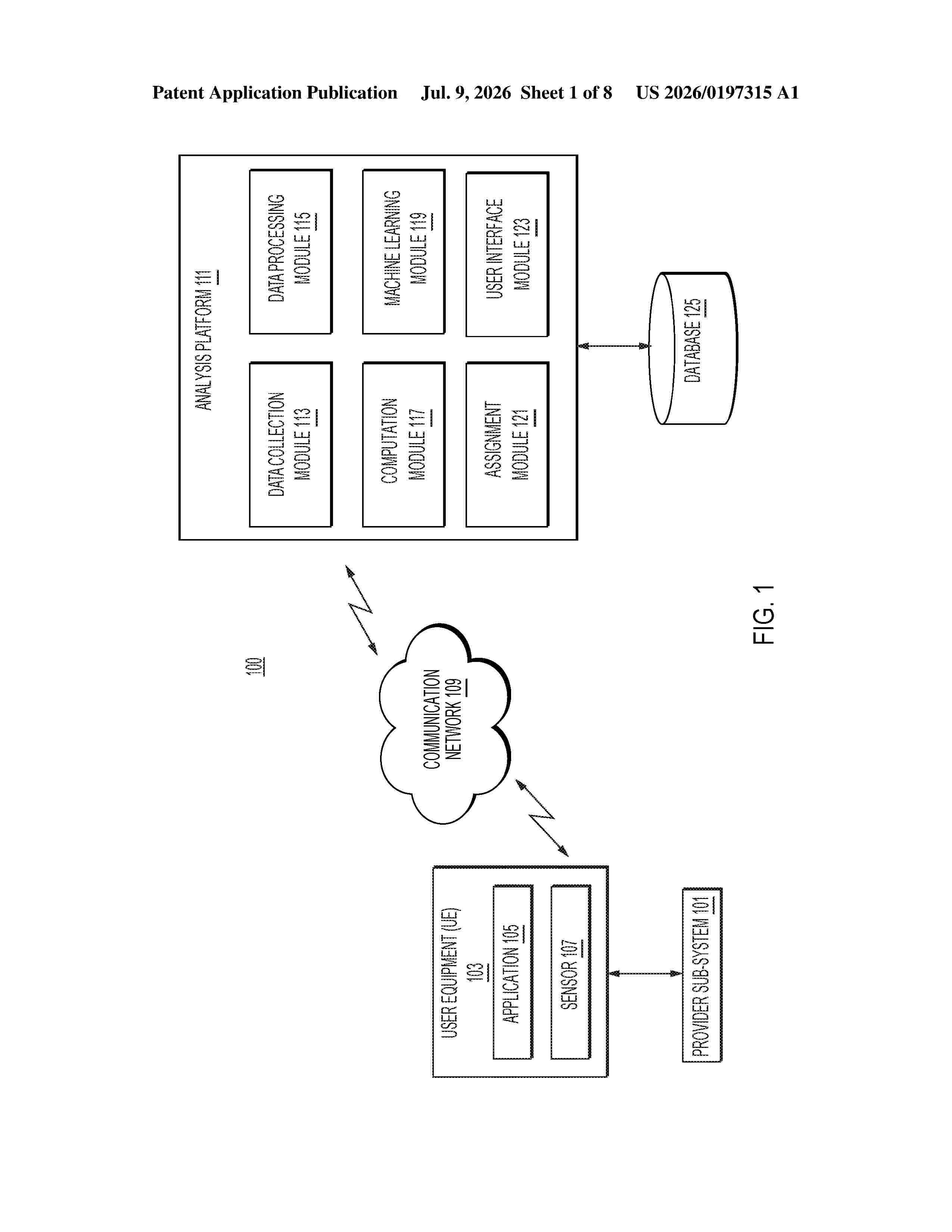
Resumen de: US20260197315A1
Systems and methods are disclosed for determining authenticity of a resource system. The method includes receiving a dataset that includes a first subset and a second subset associated with a first resource system; down-sampling the first subset but not the second subset; generating a first feature for a machine learning model based on the down-sampled first subset; generating a second feature for the machine learning model based on the second subset; generating, via input of at least one of the first feature or the second feature into the machine learning model that is trained to output a fraudulent measure, one or more data objects indicative of validating the fraudulent measure; and initiating performance of one or more prediction-based actions in response to the generating.
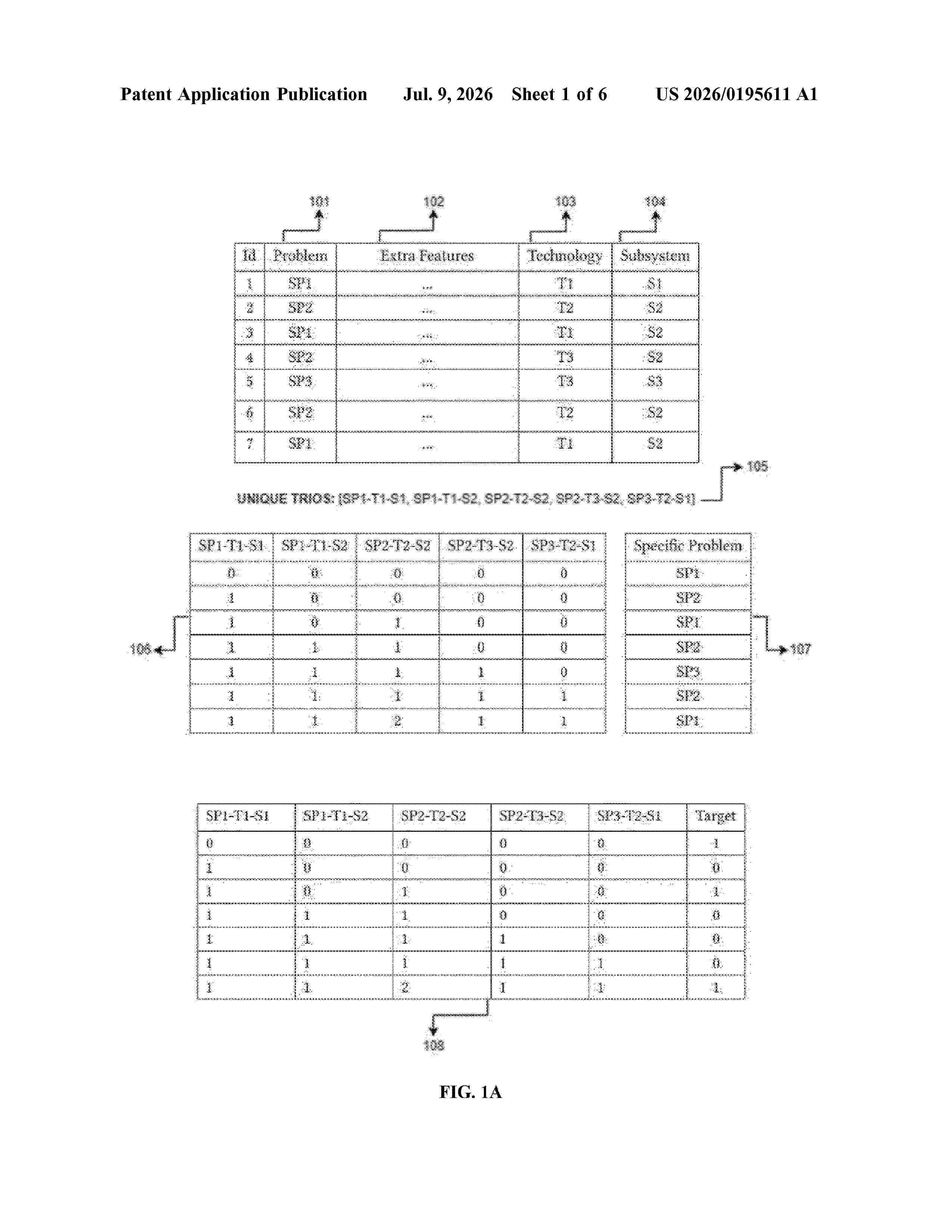
Resumen de: US20260195611A1
The present invention describes a self-adaptive system capable of extracting correlations between multiple faults from net-work topologies, with the innovative component being the data preprocessing phase generating causality matrices to provide as an input to ML models. The proposed fault correlation system is responsible for, without any configuration, identifying the hierarchical relationships be-tween the multiple alarms, allowing for a better understanding of the causality and impact of each malfunction, hence assisting the implementation of RCA rules. This allows, not only for a huge dimensionality reduction of alarms needed to be processed by a TO's, but also significantly increases the knowledge about the topology, thus reducing downtime and increasing the quality of service of the network and services.
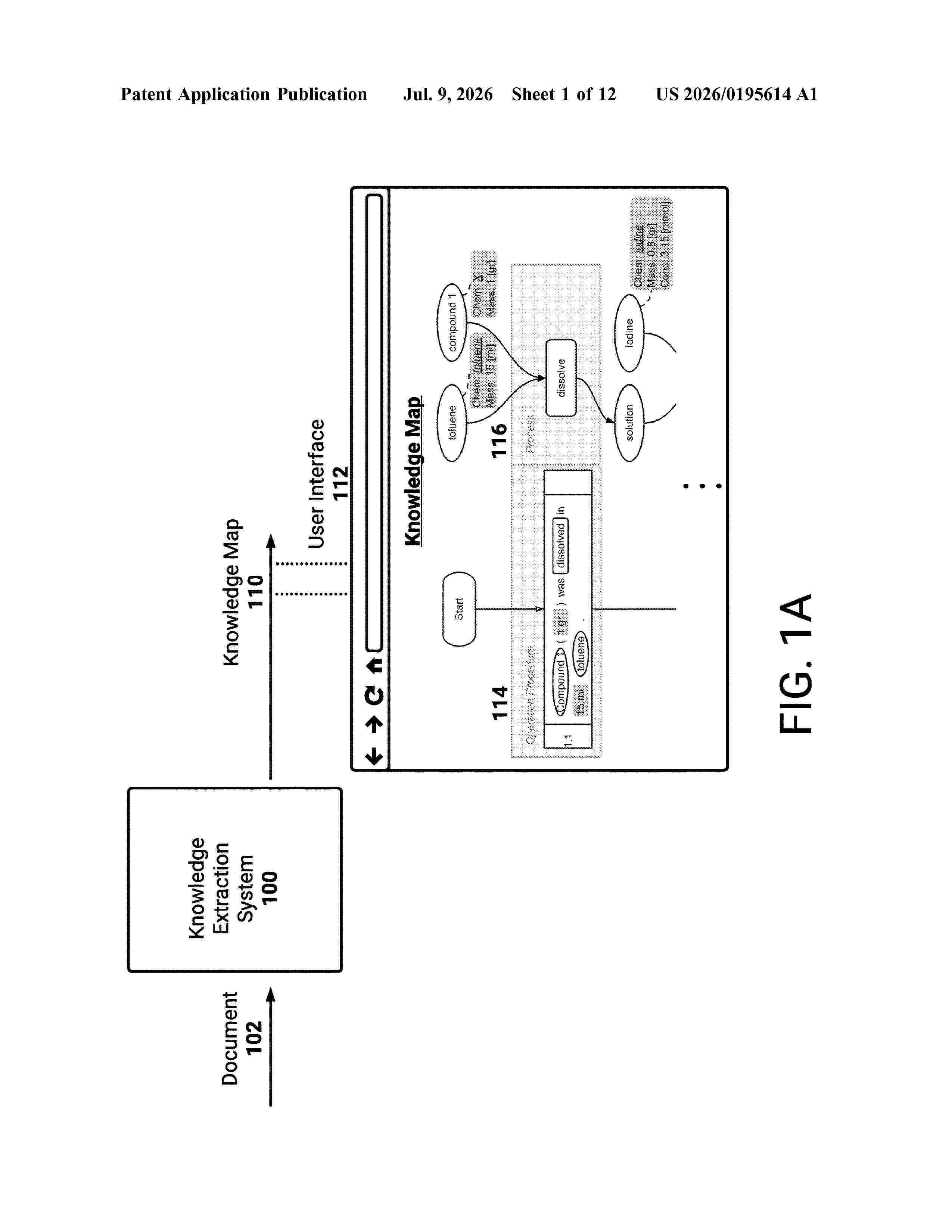
Resumen de: US20260195614A1
Systems and methods for extracting information from documents and constructing corresponding knowledge maps with respect to defined knowledge models. Deep-learning based models for Natural Language Processing (NLP) are applied to tokenize words, tag, parse, and lemmatize sentences of input documents. Then an information extractor traverses the dependency tree of NLP object to recursively extract the entities of interest to the knowledge models. Finally, a knowledge map constructor traverses the dependency tree of NLP object to determine the relationships among the extracted entities and construct knowledge maps recursively following the defined knowledge models.
Resumen de: US20260196354A1
0000 There are provided methods, systems and non-transitory storage mediums for predicting growth of an abdominal aortic aneurysm (AAA) of a patient having been diagnosed with AAA. Segmented regions of interest (ROI) comprising the aorta and adjacent structures are received by segmenting a set of images. A wall shear stress parameter and intraluminal thickness parameter is determined. A 3D parametric mesh comprising a plurality of concentric 3D mesh layers is generated, where each concentric 3D mesh layer includes a same predetermined number of nodes. The generation includes encoding the segmented ROIs, the wall shear stress parameter and the intraluminal thickness parameter as features at respective node locations in the 3D parametric mesh. A trained growth prediction machine learning model predicts, based at least on a subset of features of the 3D parametric mesh, if the given patient will show AAA growth. The training of the growth prediction model is also disclosed.
Resumen de: US20260195643A1
0000 Example implementations provide a computer-implemented method for training a machine-learned model, the method comprising: processing, using a layer of the machine-learned model, positive input data in a first forward pass; updating one or more weights of the layer to adjust, in a first direction, a goodness metric of the layer for the first forward pass; processing, using the layer, negative input data in a second forward pass; and updating the one or more weights to adjust, in a second direction, the goodness metric of the layer for the second forward pass.
Resumen de: WO2026147368A1
The invention relates to a system for processing, analyzing, and classifying graph data in the fields of machine learning and data science, and an operation method of said system.
Resumen de: US20260195338A1
0000 Data digitization via custom integrated machine learning ensembles is provided. For example, a system integrates multiple trained machine learning ensembles to identify, extract, and map data. The system receives a data set from sources. The system identifies ensembles can include machine learning models that can determine an outcome. The system filters a subset of data from the data set. The system identifies a layout for the data set based on a vendor type, data type, and the data set. The system executes a block detection module to identify blocks of the layout. The system executes a header detection module. The system executes a policy detection module to identify the headers as policies. The system transforms, based on the headers, the layout, the blocks, and the policies, the data set into a second file type, and presents the transformed data set for integration into a capital management system.
Resumen de: US20260197254A1
0000 Embodiments relate to analyzing network packets in a telecommunication networks using machine learning models. The network packets are correlated and then labeled to indicate successes or failures in a subtask of communication flow. Features are extracted based on the labels and correlated network packets. The extracted features are applied to a machine learning model to predict or infer success or failure of the entire communication flow. The result from the machine learning model may again be applied to subsequent machine learning models to predict root cause of a failure or to predict or infer the type of success. In this way, more accurate diagnosis of network issues in the telecommunication networks may be made in a more expedient manner.
Resumen de: US20260195821A1
0000 The present system provides a method and apparatus for predicting a likelihood of injury of an individual. The system generates a frailty score that represents the likelihood of a person being injured. The frailty score is generated by using Artificial Intelligence (AI) and machine learning using a specialized data set. The frailty score can then trigger actions to reduce the possibility of injury or to determine whether to engage in the injury risking behavior at all.
Resumen de: WO2026146097A1
The collected information is distributed (306) between input data and output data with a view to training (308) a machine learning model in order to obtain predictions identifying which peers are most likely to transmit missing blocks and at what time. The machine learning model thus trained enables each peer to determine a scheduling of demands made by said peer on the other peers in the consensus process for the elaboration of the blockchain, according to the predictions obtained. The consensus process is therefore more efficient.
Resumen de: US20260195639A1
Training a differential privacy-aware (DP-aware) machine learning model includes transmitting epsilon hyperparameters to federated learning (FL) nodes. A differential privacy-aware (DP-aware) machine learning model is generated based on noise-infused surrogate histograms received from the FL nodes, each noise-infused surrogate histogram based on an epsilon hyperparameter and representing a node-specific dataset. The DP-aware machine learning model is transmitted to the FL nodes. A DP-aware aggregate histogram is generated by merging DP-aware gradients and DP-aware Hessians determined by the FL nodes based on each FL node generating predictions by applying the DP-aware machine learning model to a node-specific dataset therein. A decision tree of the DP-aware machine learning model is expanded by dividing data in one or more decision tree nodes. The machine learning model is iteratively trained by successively merging further DP-aware gradients and DP-aware Hessians generated by FL nodes based on updated versions of the DP-aware machine learning model.
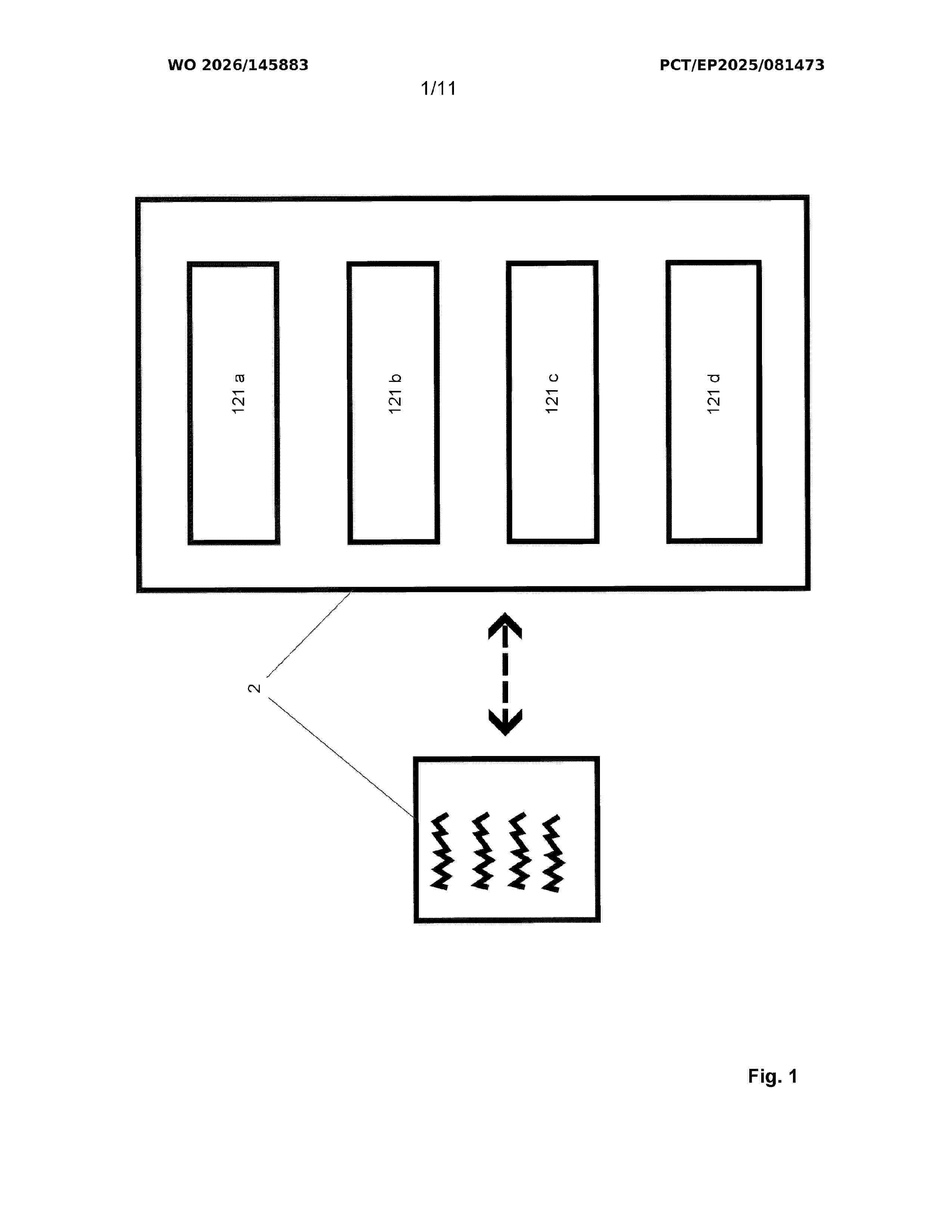
Resumen de: WO2026145883A1
Proposed is a novel machine learning system (1) for contract intelligence automation, and corresponding method for training the machine learning system for automated text analysis and for applying it. A plurality of contracts (2) with a plurality of clauses (22) is received by the system (1), wherein wordings of equivalent clauses (22) vary across contracts (2); contract text (21) is read into a data processing system (15); clause text chunks (121) are identified, that are equivalent across contracts (2), and assigned a contract term category (122). Considering a respective semantic context (131) of each of the contracts (2), a semantic meaning (132) of each of the clause text chunks (121) is determined and encoded in a clause embedding space (141) and stored in vector database (14); data automation tasks can be performed using entries of the vector database (14), particularly automatic consistency monitoring (197) and outlier detection across contracts (2) and a monitoring of clause (22) nuances across contracts (2) e.g. via a graphical representation (16).
Resumen de: US20260195357A1
Aspects of the present disclosure provide techniques for machine learning based disambiguation. Embodiments include receiving a query via a user interface; generating an enriched query by rewording the query based on conversation history data associated with the query. Embodiments include retrieving relevant information from a data store based on using an embedding of the enriched query to perform a semantic search. Embodiments include providing the enriched query and the relevant information to a language processing machine learning model along with a prompt that instructs the language processing machine learning model to generate an answer to the enriched query based on the relevant information and to generate a disambiguation question if one or more conditions are met. Embodiments include receiving an output from the language processing machine learning model in response to the prompt. Embodiments include providing a response to the query via the user interface based on the output.
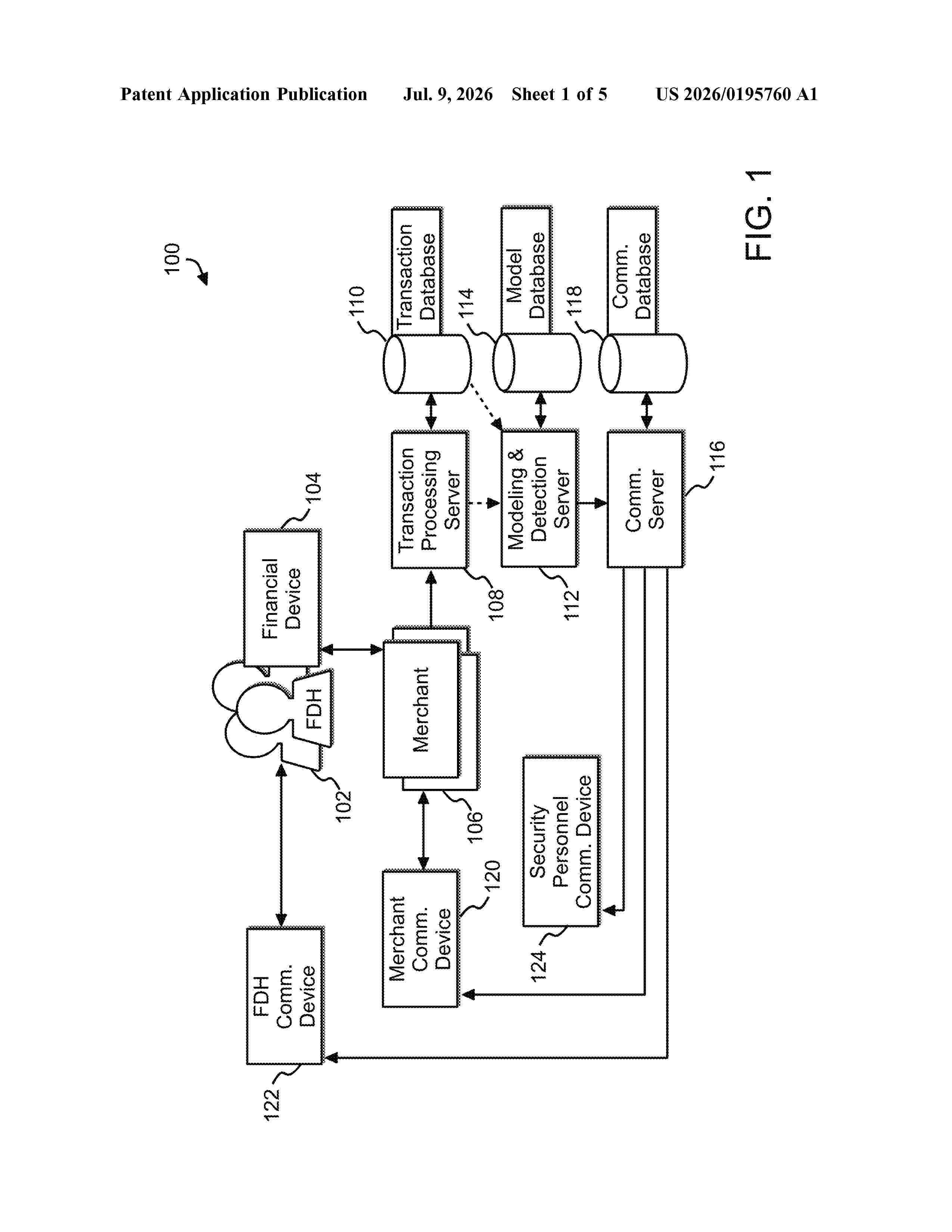
Resumen de: US20260195760A1
Provided are systems, methods, and computer program products for early detection of a merchant data breach through machine-learning analysis. An example system includes a processor configured to receive transaction authorization request data. The processor is also configured to generate a metric based on security-testing transaction activity. The processor is further configured to generate features for training one or more models. The processor is further configured to generate a first dataset based on the features and associated with a plurality of merchants, and a second dataset based on the features and associated with a previously breached merchant. The processor is further configured to train an ensembled model to associate merchants with a likelihood of data breach. The processor is further configured to determine a breached merchant, automatically freeze a transaction, retrain the ensembled model, and determine another breached merchant based on the updated models.
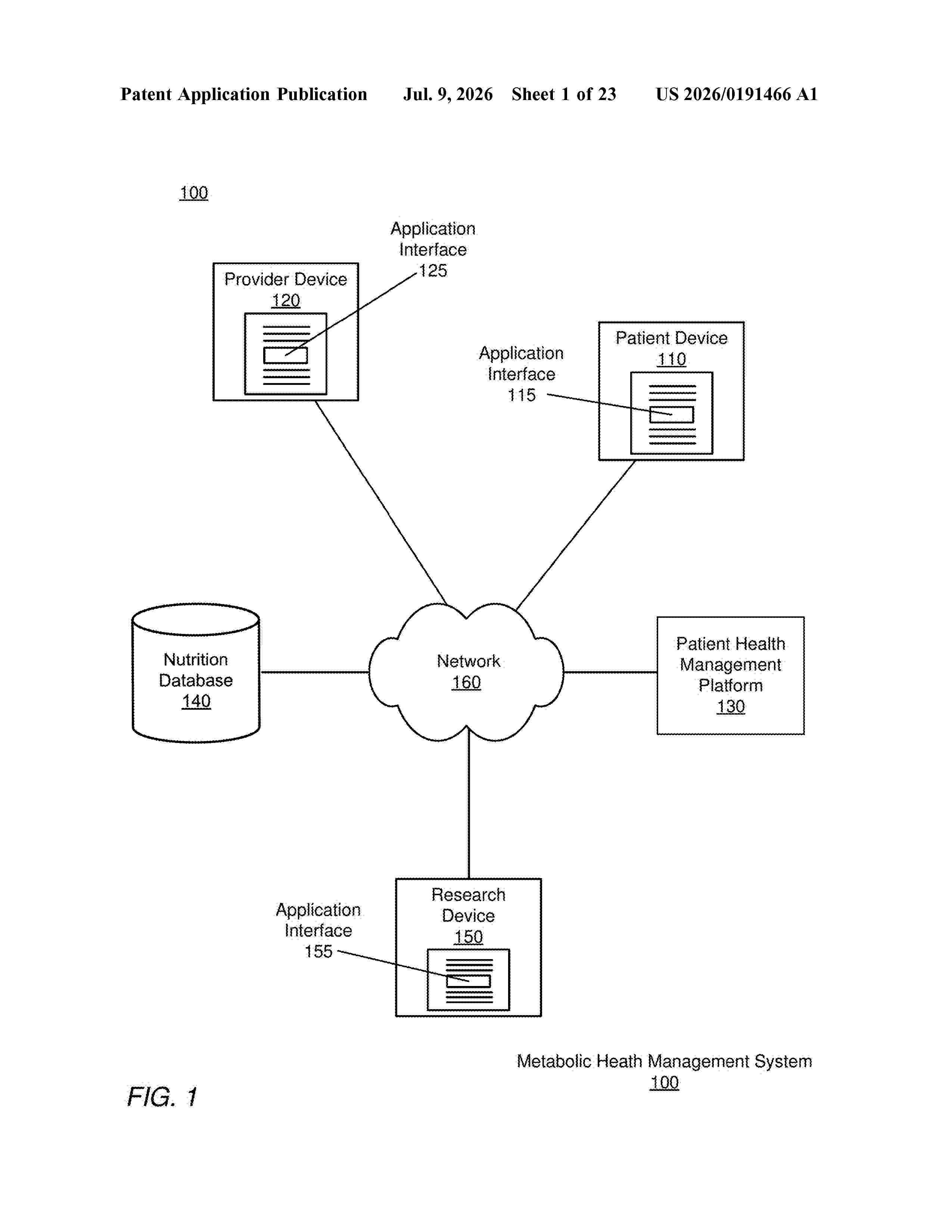
Resumen de: US20260191466A1
A patient health management platform accesses a metabolic profile for a patient and biosignals recorded for the patient during a current time period comprising sensor data and/or lab test data collected for the patient. The platform encodes the biosignals into a vector representation and inputs the vector representation into a patient-specific metabolic model to determine a metabolic state of the patient at a conclusion of the current time period. The patient-specific metabolic model comprises a set of parameter values determined based on labels assigned to the previous metabolic states and a function representing one or more effects of the plurality of biosignals of the personalized metabolic profile. The platform compares the determined metabolic state of the patient to a threshold metabolic state representing a target metabolism. The platform generates a patient-specific treatment recommendation outlining instructions for the patient to improve the determined metabolic state to the functional metabolic state.
Resumen de: US20260195418A1
A system may be configured to perform a method for generating customized training. The system may receive first user interaction data associated with a user. The system may determine, using a machine learning model (MLM), whether the first user interaction data exceeds a predetermined threshold. Based on such determination, the system may assign a training module to the user. The system may access a user profile associated with the user, the user profile comprising a plurality of training modules. The system may generate a training plan based on the training module and the plurality of training modules. The system may receive second user interaction data associated with the user, and may determine an efficacy level of the training plan based on the second user interaction data. The system may dynamically update the training plan based on the efficacy level, and may dynamically display the training plan in the user profile.
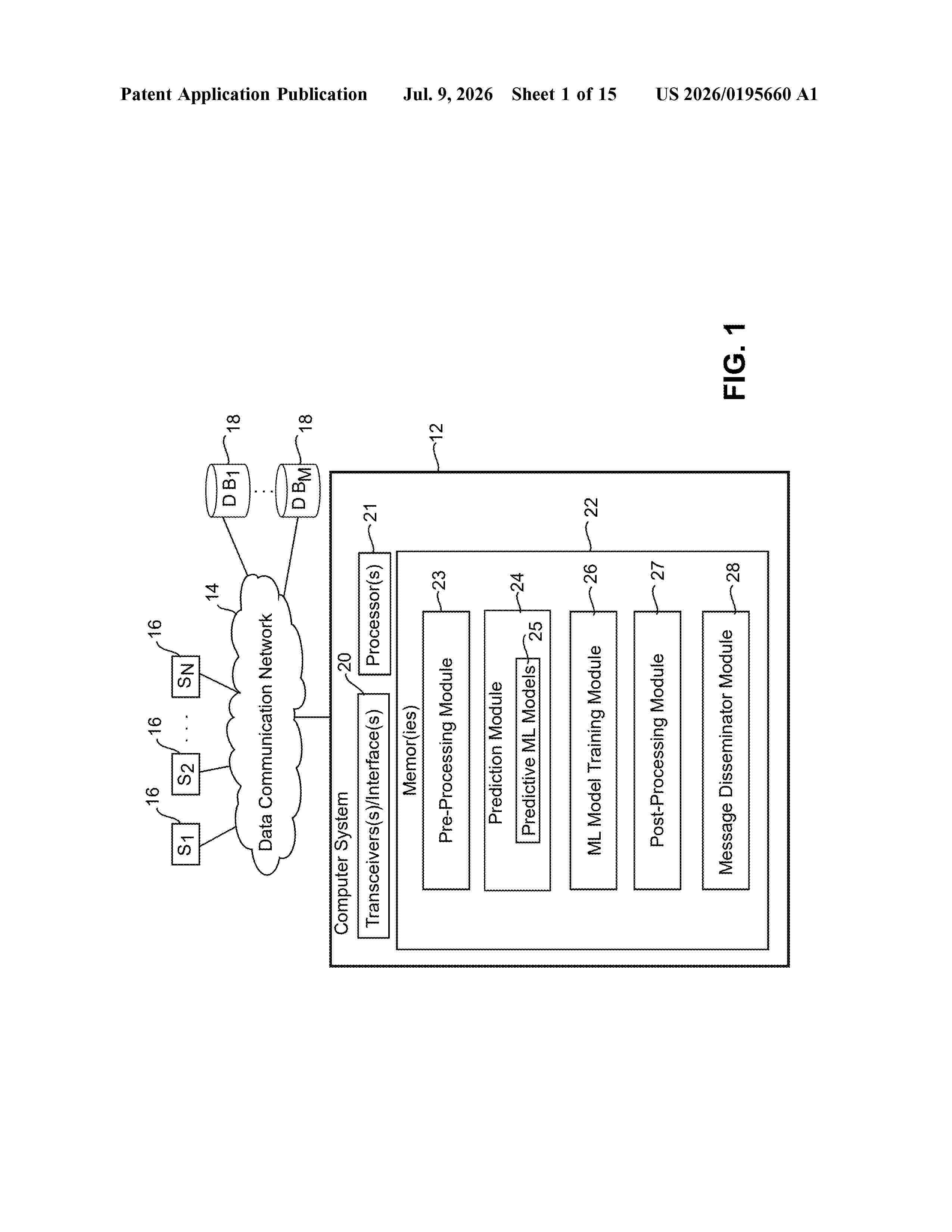
Resumen de: US20260195660A1
A computer system includes a transceiver that receives over a data communications network different types of input data and multiple data transaction objects from multiple source nodes. A pre-processor processes the different types of input data and the data transaction objects to generate an input data structure. Based on the input data structure, one or more predictive machine learning models is trained and used to predict a probability of execution of each of the data transaction objects at a future execution time. Output data messages are then generated for transmission by the transceiver over the data communications network indicating the probability of execution for at least one of the data transaction objects at the future execution time.
Resumen de: WO2025046310A1
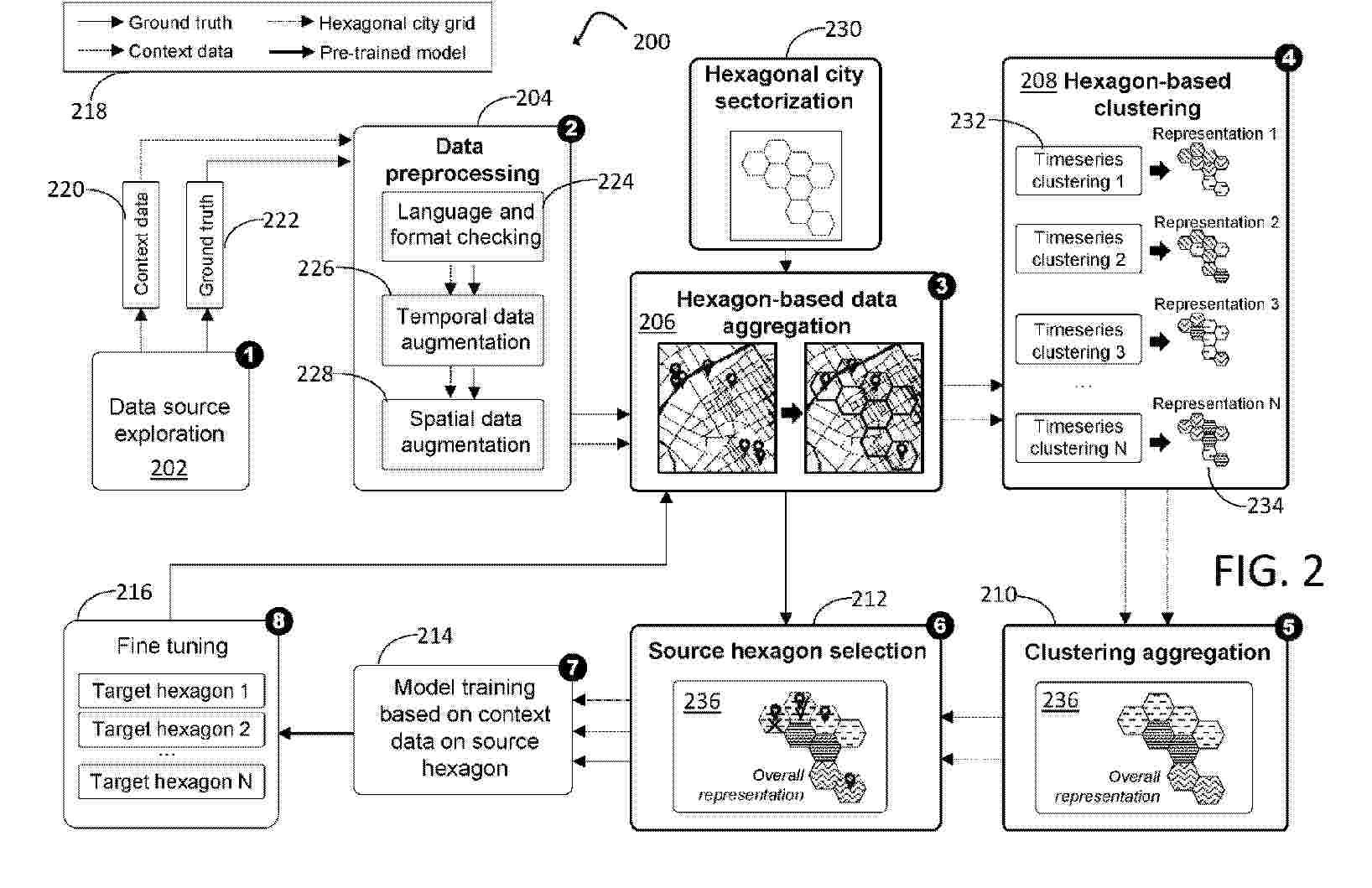
A computer-implemented, machine learning method for spatiotemporal transfer learning. Sectors of an area are aggregated using preprocessed data from one or more data sources. The sectors are clustered based on different representations obtained for each context feature associated with each of the sectors. One or more context features that have a higher impact on a target feature to be predicted than other context features are identified from a plurality of context features and aggregated to obtain a representation of the area. Using the representation of the area, a particular sector within each of the clustered sectors is selected based on similarity to a respective centroid of the cluster to generate a set of particular sectors. A model associated with a source sector of the set of particular sectors is trained. The method has applications including, but not limited to smart cities, public safety and energy optimization.
Resumen de: EP4773657A2
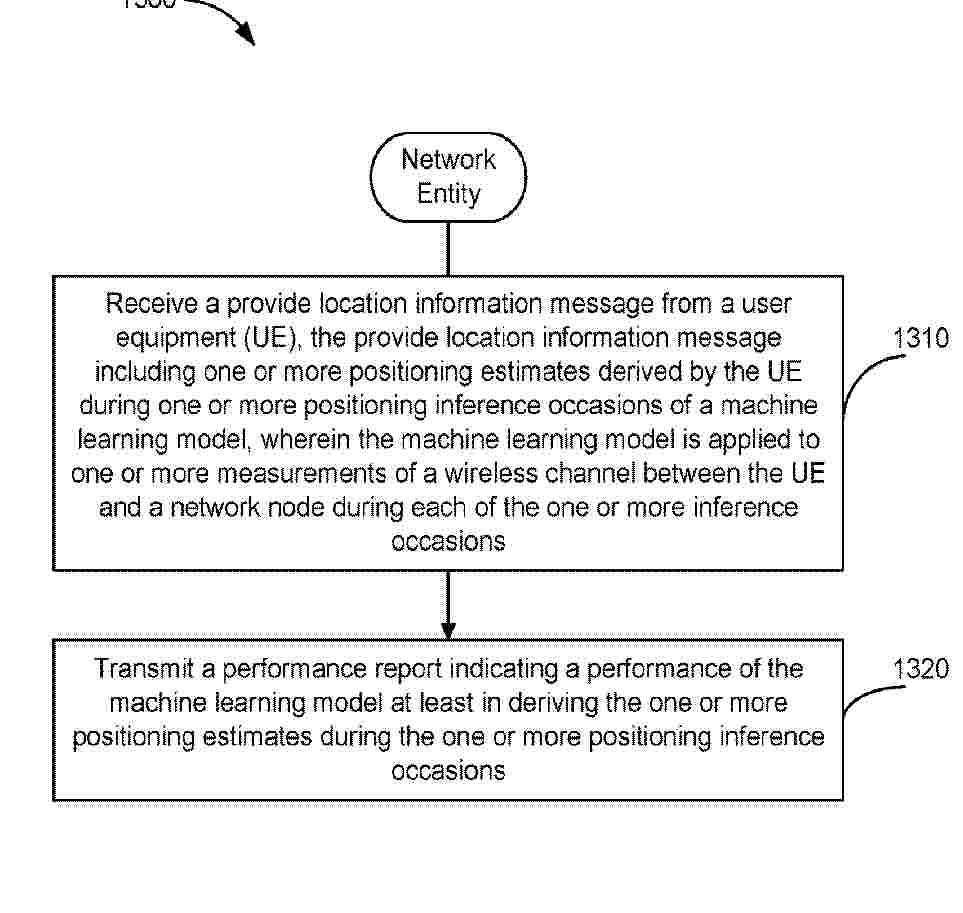
0001 Disclosed are techniques for wireless communication. In an aspect, a network entity receives a provide location information message from a user equipment (UE), the provide location information message including one or more positioning estimates derived by the UE during one or more positioning inference occasions of a machine learning model, wherein the machine learning model is applied to one or more measurements of a wireless channel between the UE and a network node during each of the one or more positioning inference occasions, and transmits a performance report indicating a performance of the machine learning model at least in deriving the one or more positioning estimates during the one or more positioning inference occasions.
Resumen de: EP4773049A1
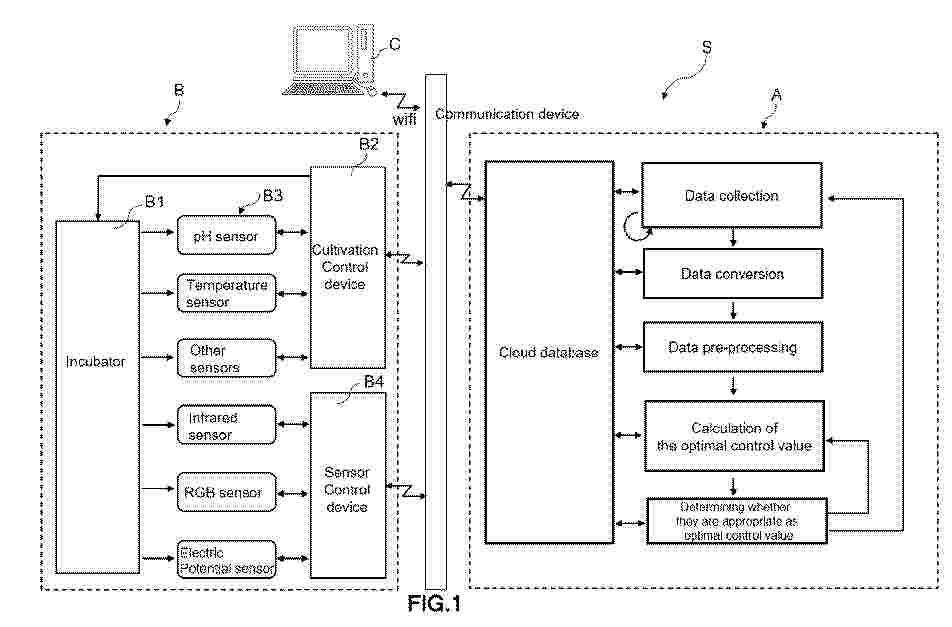
0001 Provided are a control variable optimization method capable of determining improved culture conditions using a predictive model based on machine learning, and a bioresource production method and a bioresource production system using the same. 0002 A bioresource production system S according to another aspect of the present invention includes: a cultivation system B for performing bioresource production; and a control variable optimization system A for optimizing control variables obtained from the cultivation system. 0003 The control variable optimization system separates the control variables into initial variables and manipulated variables, creates predictive models adapted to the initial variables and the manipulated variables, respectively, and optimizes the control variables by combining the predictive models.
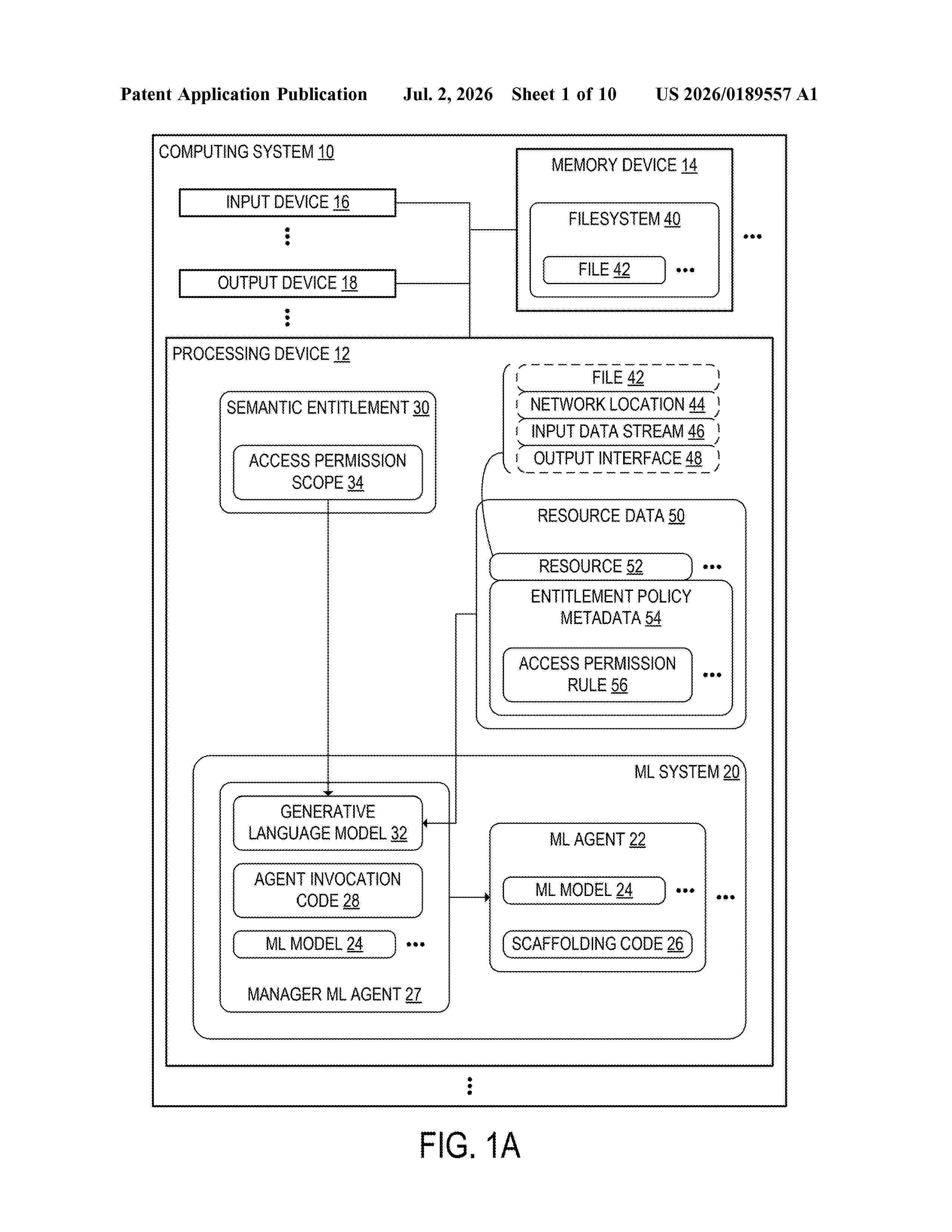
Resumen de: US20260189557A1
0000 A computing system including one or more processing devices configured to receive a semantic entitlement that semantically specifies an access permission scope of a machine learning (ML) agent included in an ML system. The semantic entitlement has a natural language format. At least in part by processing the semantic entitlement at a generative language model included in the ML system, the one or more processing devices identify one or more resources that are included in the access permission scope indicated in the semantic entitlement. The one or more processing devices grant an ML agent of the plurality of ML agents access to the one or more identified resources. At the ML agent, the one or more processing devices compute an agent output based at least in part on the one or more identified resources. The one or more processing devices output the agent output to an additional computing process.
Resumen de: WO2026137061A1
The method (200) comprises extracting (210) a set of selected features from at least one charge-discharge cycle (C) of a battery and estimating (230) the remaining useful life of the battery (1) by applying a machine learning model (140) to the set of selected features. The machine learning model (140) is trained during a preliminary phase (100), comprising: extracting (110) a set of primary features from the charge-discharge cycles (C) of reference batteries; processing (120) the set of primary features by applying an outlier detection process (25) and/or a data smoothing process to a primary feature (F) versus charge-discharge cycles (C) curve (F(C)A); selecting (130) the features from among the processed primary features using correlation between the set of primary features and the remaining useful lives of the reference batteries; and training the machine learning model (140) with a training set of the selected features extracted from multiple charge-discharge cycles (C) of the reference batteries.
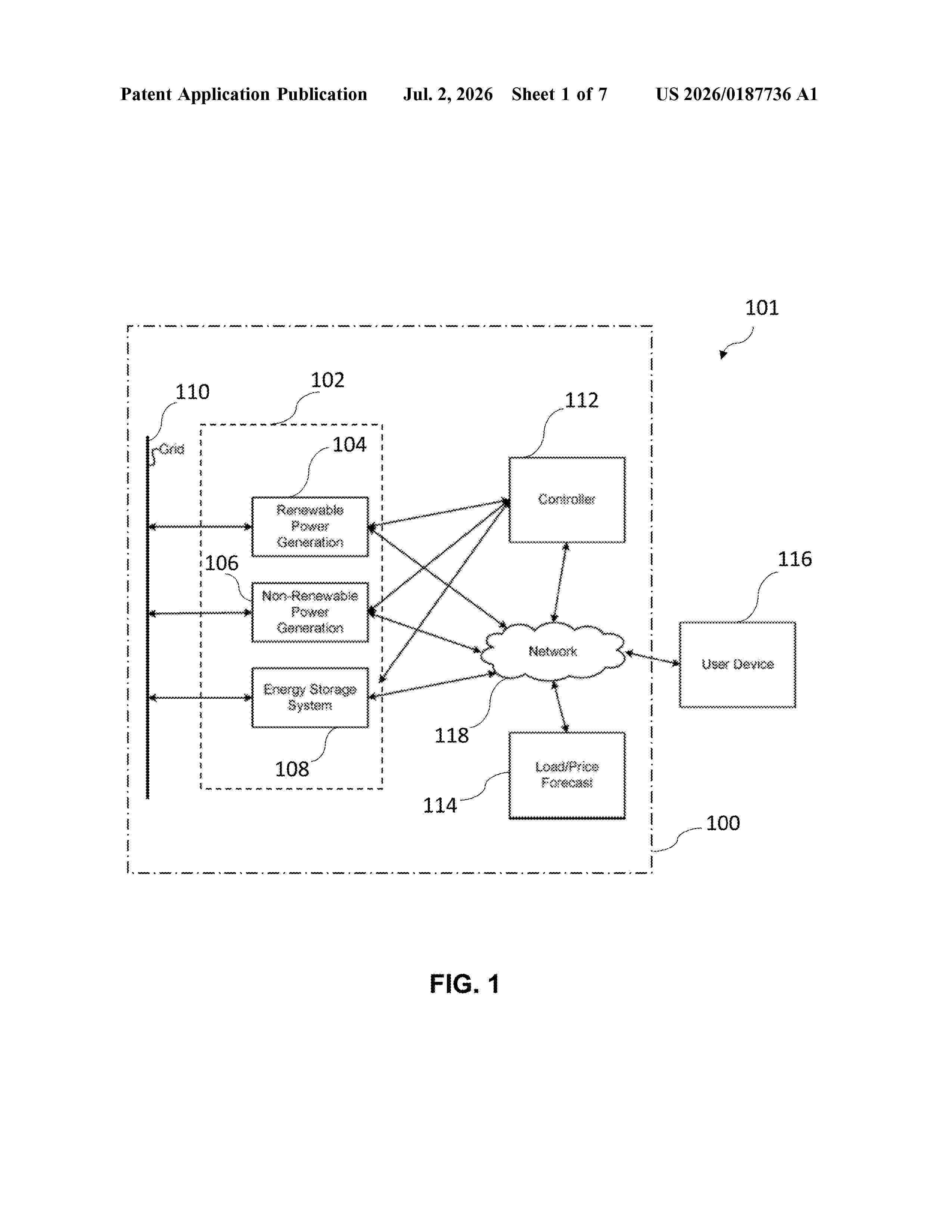
Resumen de: US20260187736A1
A computer-implemented method and computer program product for predicting a required committed capacity of an electric utility are provided. The method includes the steps of: (a) performing a stochastic optimization of raw data to produce a total committed capacity from conventional thermal units as a target data, wherein the raw data comprises grid operating conditions; (b) combining the total committed capacity from conventional thermal units with raw features and engineered features to generate training data; (c) training a machine learning model for predicting the required committed capacity of the electric utility using the generated training data; (d) predicting the required committed capacity of the electric utility using the trained machine learning model; and (e) running an augmented version of a deterministic dispatch optimization model based on the predicted required committed capacity of the electric utility. The computer program performs the aforementioned steps.
Nº publicación: AU2025216427A1 02/07/2026
Solicitante:
VIRRIDY DIGITAL LLC
VIRRIDY DIGITAL LLC
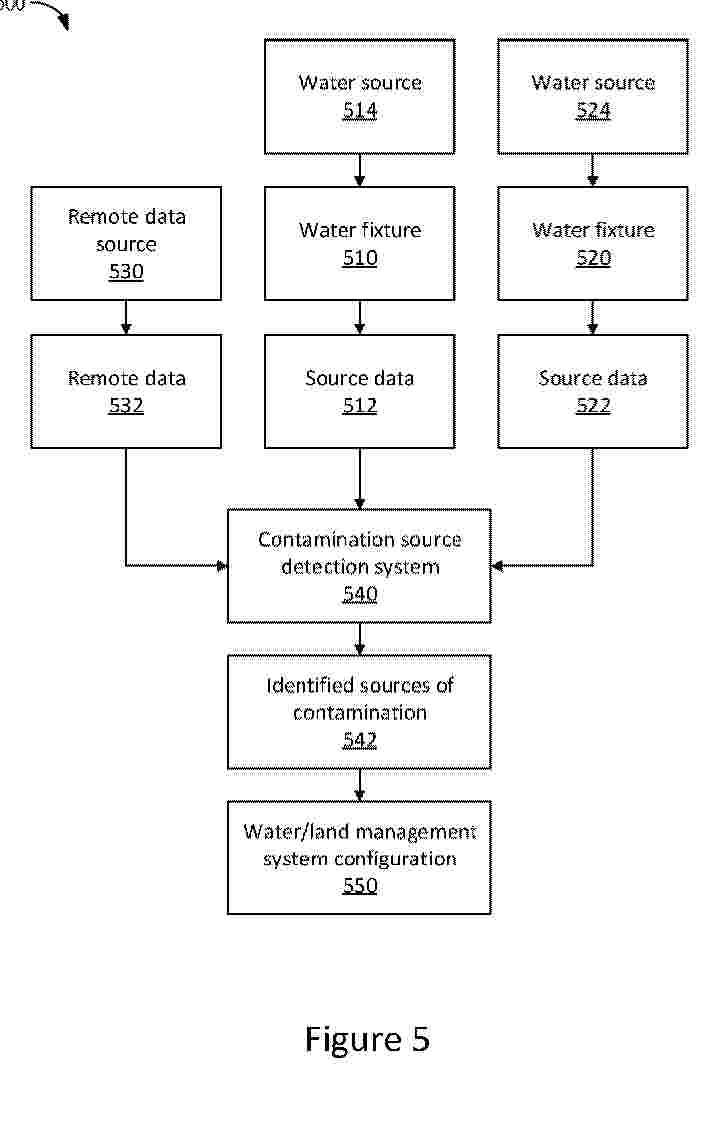
Resumen de: AU2025216427A1
Attribution of in-stream water quality via monitoring reporting and verification sensor geospatial fusion networks may be provided by a system comprising a plurality of separate water fixtures, wherein each of the plurality of separate fixtures includes an optical sensor configured to measure a water quality metric of a water source and a data transmission system configured to transmit source data from each of the plurality of water fixtures, respectively, a remote data source configured to transmit remote data which includes survey data about one or more land use metrics, a contamination source detection system configured to receive the source data from the plurality of water fixtures and the remote data from the remote data source and employ a process-based land-surface model ensemble and a machine learning-based model to identify a land-based source of predicted contamination of a water source based upon the remote data and the source data.
 BOPI
BOPI
 Sede Electrónica
Sede Electrónica