Si deseas distinguir tus productos, servicios o ambos de los de otra empresa, es posible que necesites una marca o nombre comercial. Descubre qué son, en qué consiste su procedimiento de registro y qué implica.

Información sobre los plazos de presentación de solicitudes de transformación de marcas de la Unión Europea en marca nacional española. Más información


Si tienes un nuevo dispositivo, producto o procedimiento que resuelva un problema técnico o tenga una ventaja práctica, existen distintas formas de protegerlo en España y en otros países. Descubre cómo hacerlo.

¿Tu innovación reside en la estética, la ornamentación o la apariencia de tu producto? Protégela mediante un diseño industrial. Descubre qué derechos confiere el registro y cómo realizar la tramitación.

Las indicaciones geográficas protegen el nombre de un producto originario de una zona geográfica, a la cual le debe una determinada calidad, reputación u otra característica. Descubre qué son, en qué consiste su procedimiento de registro y qué beneficios conceden.

Las patentes publicadas en todo el mundo son una valiosa fuente de información científica, técnica y comercial.

Si eres emprendedor/a o una empresa y quieres potenciar y mejorar la rentabilidad de tu negocio protegiendo de forma adecuada los activos intangibles de tu organización, en este espacio encontrarás lo necesario.



 104
resultados
104
resultados
 Última actualización
27/06/2026 [07:03:00]
Última actualización
27/06/2026 [07:03:00]


 Resultados 25 a 50 de 104
Resultados 25 a 50 de 104

Resumen de: US20260170363A1
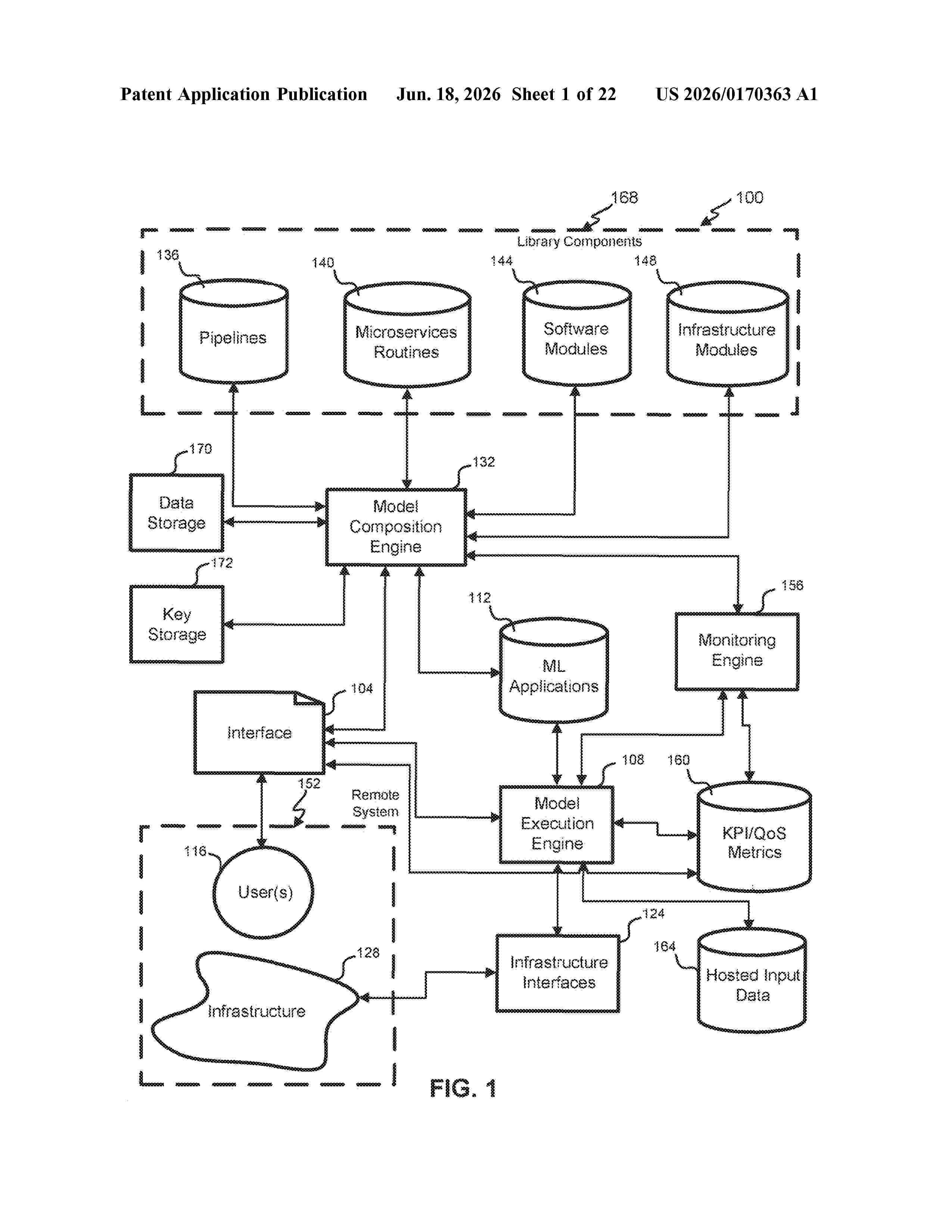
0000 The present disclosure relates to systems and methods for an intelligent assistant (e.g., a chatbot) that can be used to enable a user to generate a machine learning system. Techniques can be used to automatically generate a machine learning system to assist a user. In some cases, the user may not be a software developer and may have little or no experience in either machine learning techniques or software programming. In some embodiments, a user can interact with an intelligent assistant. The interaction can be aural, textual, or through a graphical user interface. The chatbot can translate natural language inputs into a structural representation of a machine learning solution using an ontology. In this way, a user can work with artificial intelligence without being a data scientist to develop, train, refine, and compile machine learning models as stand-alone executable code.

Resumen de: US20260171247A1
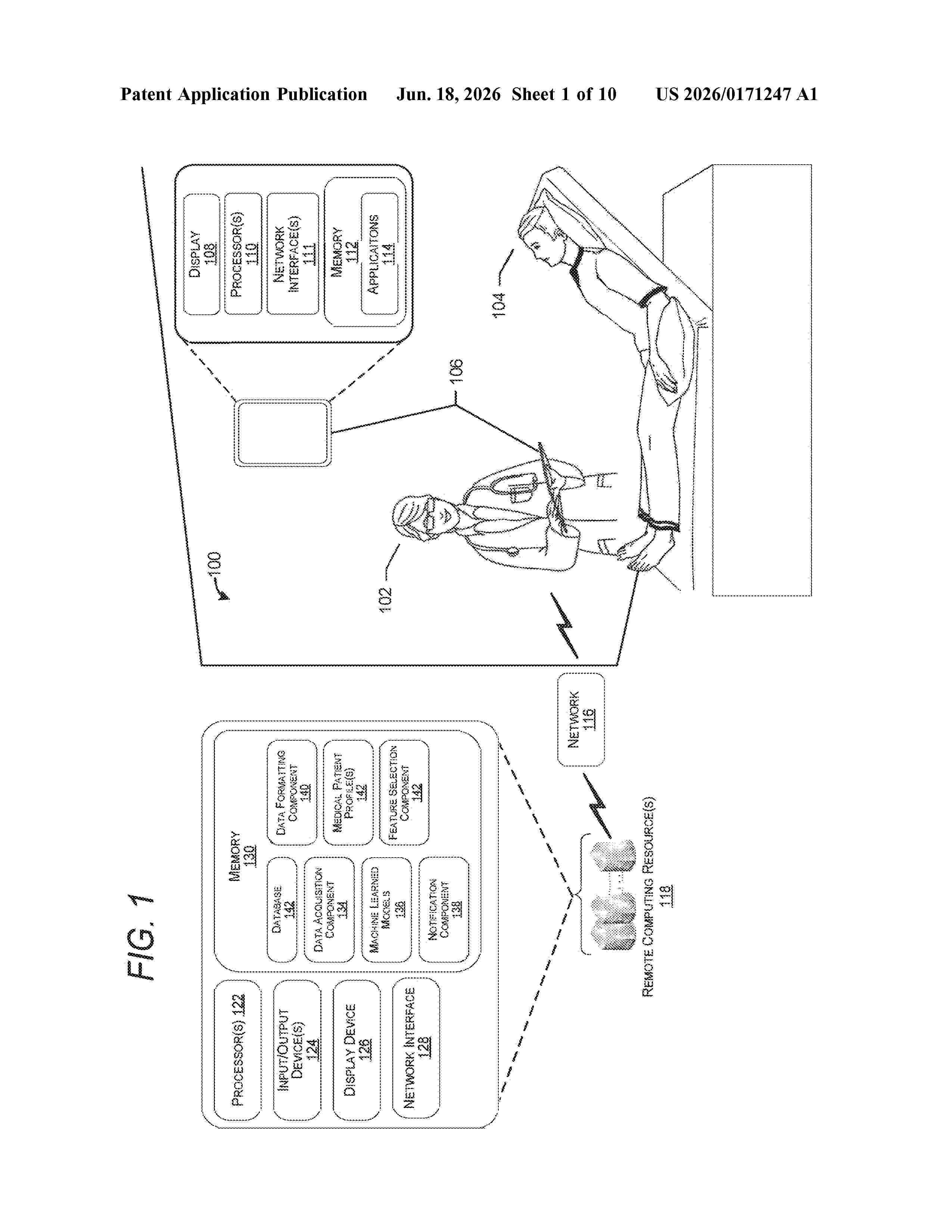
0000 The present disclosure describes methods and systems for machine learning models utilized for identifying issues with medications and gaps in care. The present disclosure also describes methods and systems for machine learning models utilized to provide recommended actions for addressing the issues with medication and gaps in care. These methods and systems utilize machine learning models that are trained to identify issues with medications and gaps in care, as well as provide recommended actions for those medications issues and gaps in care. The models are trained with data from disparate sources that are aggregated and formatted to be utilized in these models.
Resumen de: US20260170870A1
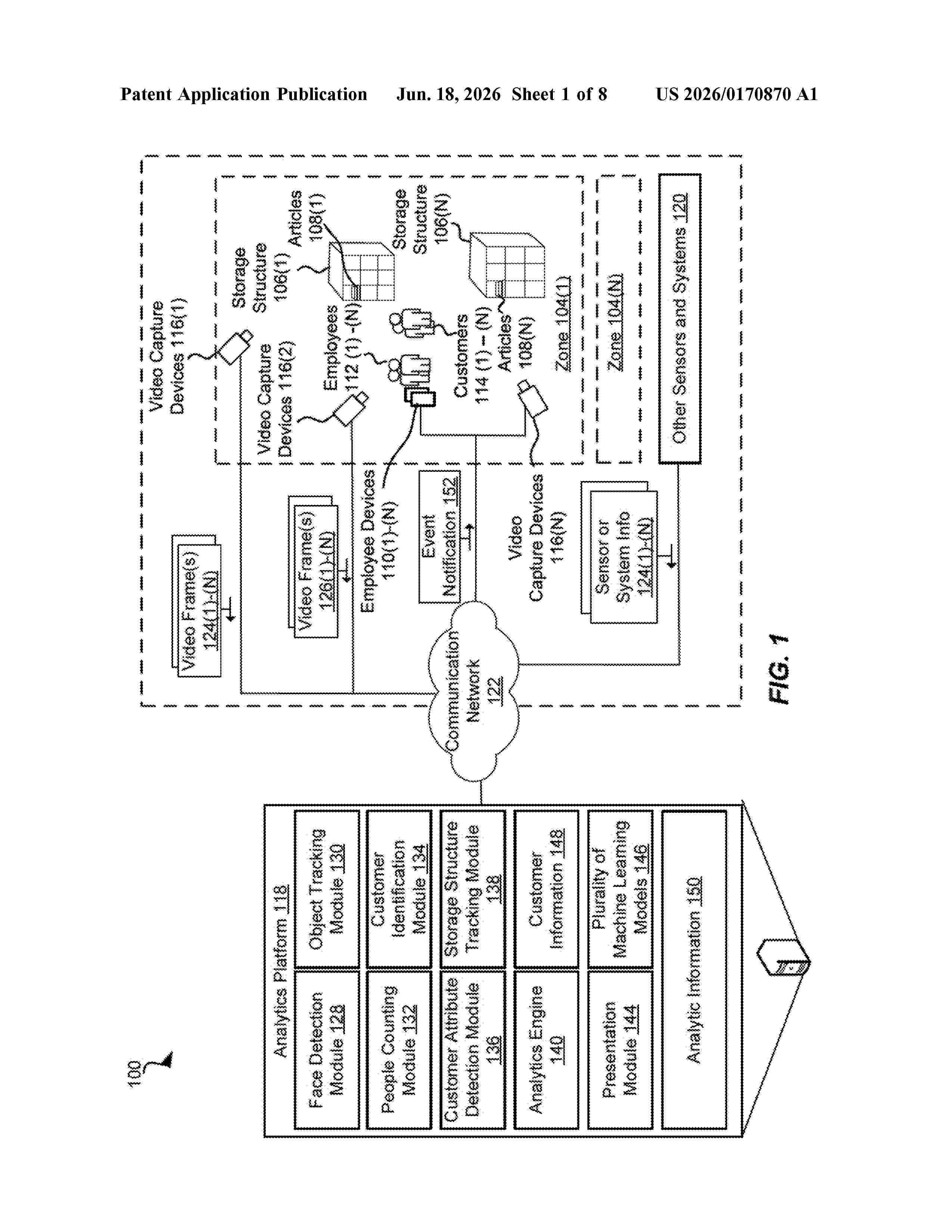
0000 A system may be configured to generate real-time analytics using machine learning and computer vision. In some aspects, the system may receive a first video frame from a first video capture device positioned to capture activity at a location within a monitored area, receive a second video frame from a second video capture device positioned to capture interaction activity of customers, determine a first inference based on the first video frame, determine a second inference based on the second video frame, and associate the first inference and the second inference based on determining that the first inference and the second inference correspond to a common time period and common location.
Resumen de: EP4761205A1
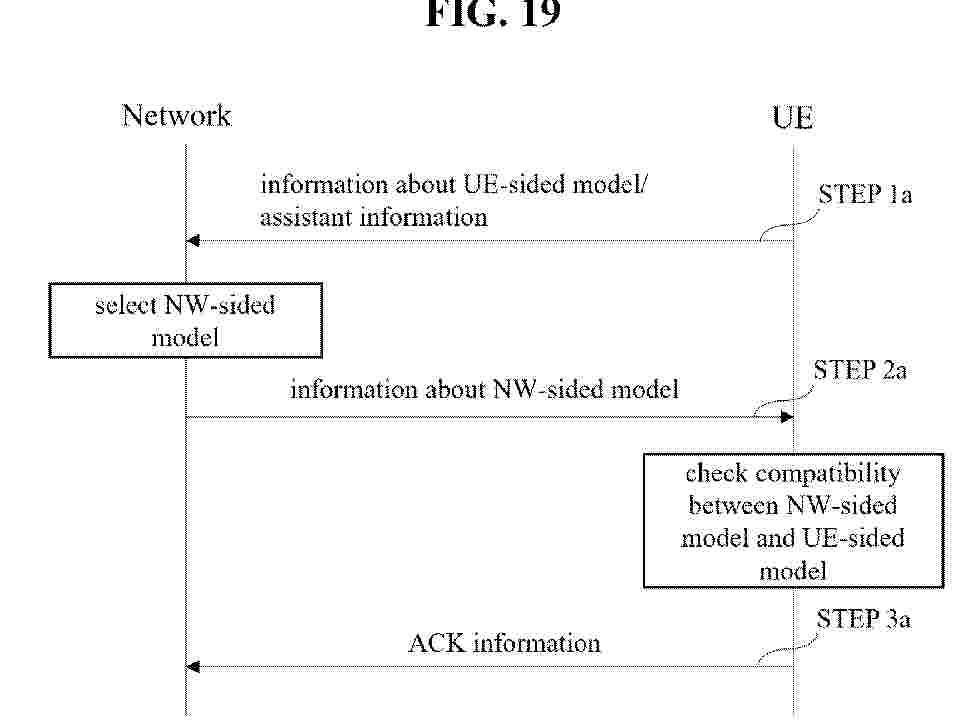
A method performed by a first apparatus in a wireless communication system according to at least one of the embodiments disclosed in the present specification may comprise the steps of: transmitting, to a second apparatus, a first signal including information about a first artificial intelligence/machine learning (AI/ML) model configured in the first apparatus; and receiving a second signal, including information about a second AI/ML model configured in the second apparatus, from the second apparatus in response to the first signal, wherein the first AI/ML model configured in the first apparatus and the second AI/ML model configured in the second apparatus are linked to each other, and the second signal includes at least one of information about a reference AI/ML model used in the second apparatus in order to evaluate the performance of the first AML model or information about conditions under which the second AI/ML model is applied.
Resumen de: WO2025034318A1
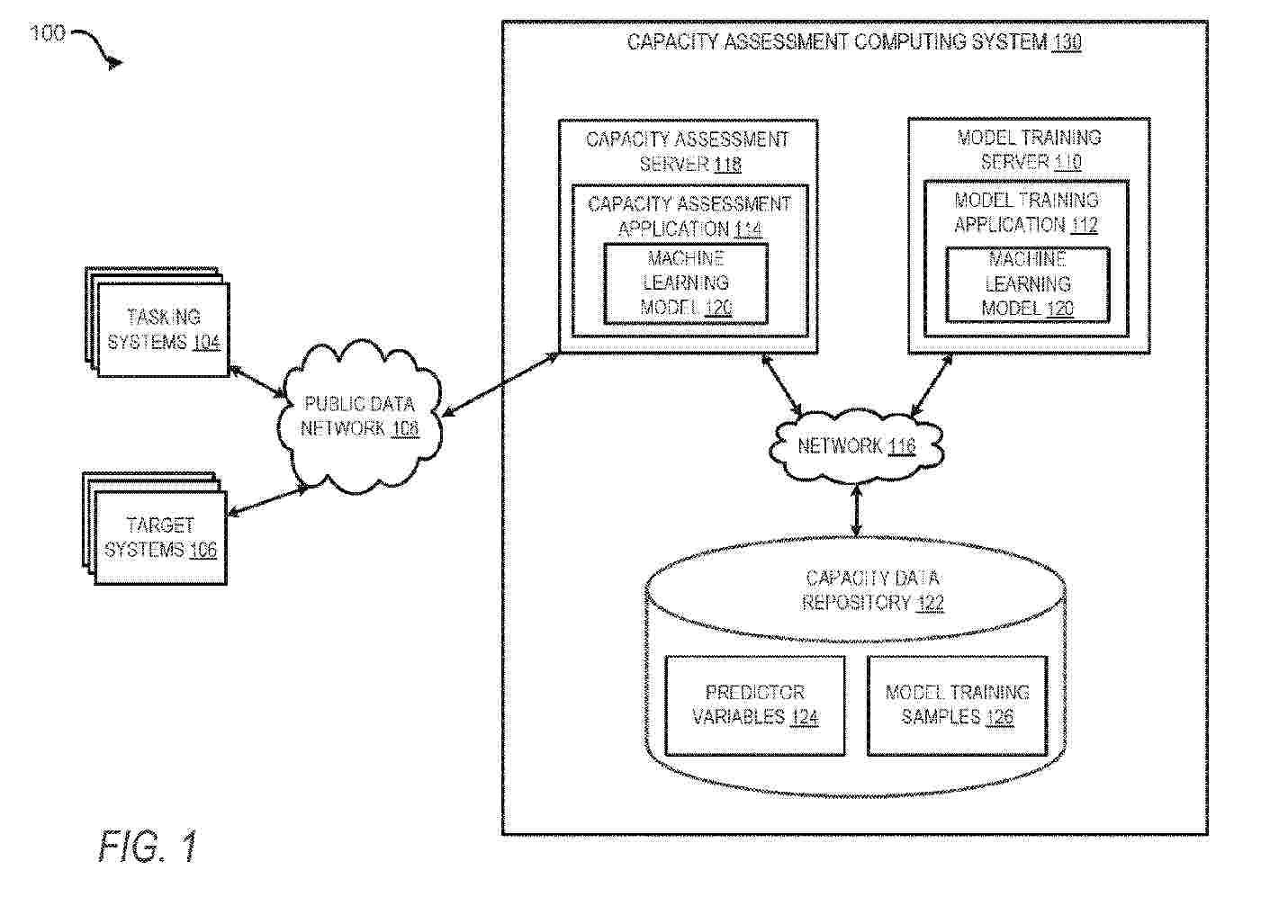
In some aspects, a computing system can generate and optimize a machine learning model to estimate an unobservable capacity of a target system or entity. The computing system can access training vectors which include training predictor variables, training performance indicators, and task quantities. A training performance indicator indicating performance outcome corresponding to the predictor variables and a task quantity associated with a task assigned to the target entity that leads to the training performance indicator. The machine learning model can be trained by performing adjustments of parameters of the machine learning model to minimize a loss function defined based on the training vectors. The trained machine learning model can be used to estimate the capacity of the target system or entity for handling tasks and be used in assigning tasks to the target entity according to the determined capacity.
Resumen de: EP4760672A1
The present disclosure relates to systems and methods for identifying commercial domiciles. An example of one such method includes operating at least one processor to: receive telematics data originating from a plurality of telematics devices installed in a plurality of vehicles; identify, using the telematics data, a vehicle stop zone, each vehicle stop zone comprising a vehicle stop cluster; and identify the vehicle stop zone as a commercial domicile by applying to the vehicle stop cluster of the vehicle stop zone at least one machine learning model trained to classify vehicle stop zones based on one or more vehicle stop features thereof.
Resumen de: US20260157349A1
0000 The present disclosure relates to systems, methods, and program applications for identifying separation-related problems in a pet. The methods, for example, can include identifying the presence or absence of multiple behavioral signs exhibited by a pet where each of the multiple behavioral signs are given a sign score based on binary annotations representing either the presence or the absence of each of the behavioral signs, and grouping subsets of the multiple behavioral signs into one of multiple principal component behavioral groupings using the binary annotations to generate principal component scores for each of the multiple principal component behavioral groupings. Methods can also include using one or more machine-learning algorithms under the control of at least one processor for accessing and correlating the principal component scores for each of the multiple principal component behavioral groupings with a population cluster associated with a type of separation-related problem.
Resumen de: US20260161980A1
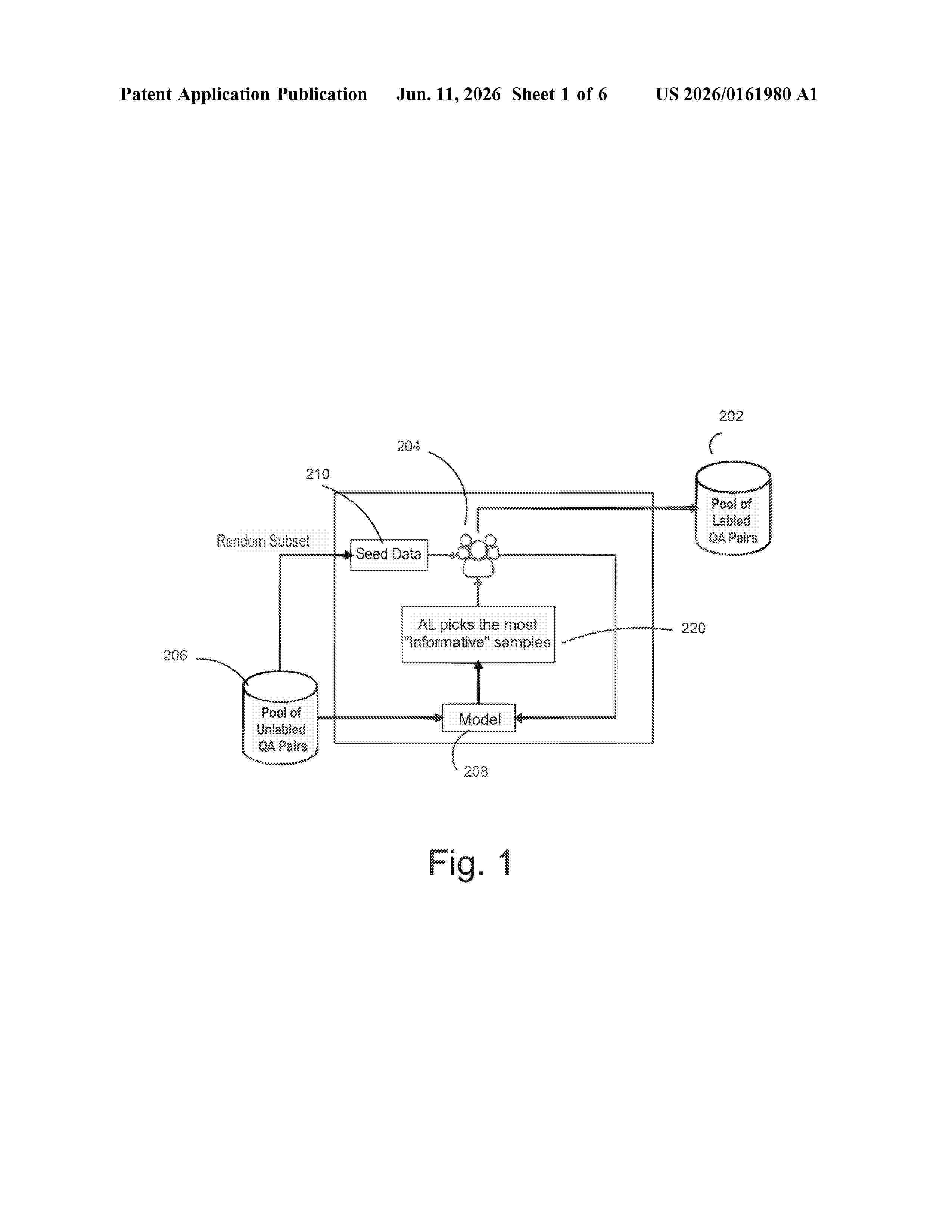
Computer systems and computer implemented methods for training a machine learning model are provided that includes: selecting seed data from an unlabeled dataset; labeling the seed data and storing the labeled seed data in a data store; training the machine learning model in an initial iteration using the labeled seed data, where the machine learning model is trained to select a next subset of the unlabeled dataset; selecting a next subset of the unlabeled dataset; computing difficulty scores for at least the next subset of the unlabeled dataset; labeling the next subset of the unlabeled data; and training the machine learning model in a second iteration using the labeled next subset of the unlabeled dataset. The machine learning model is generally trained to select the next subset of the unlabeled dataset for a subsequent training iteration by presenting the labeled next subset of the unlabeled dataset in an order sorted based on the difficulty scores.
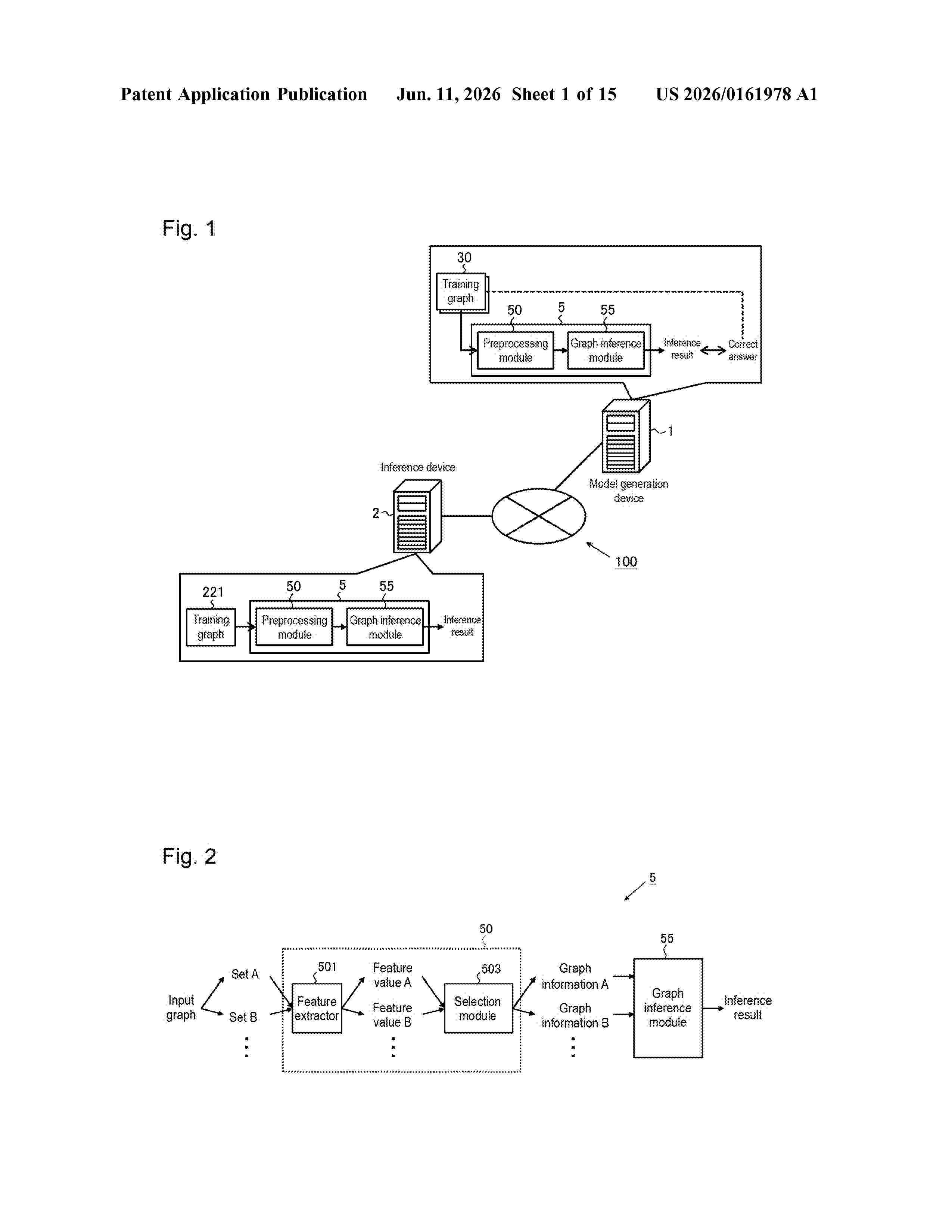
Resumen de: US20260161978A1
The model generation device performs machine learning for an inference model that includes a preprocessing module and a graph inference module. The preprocessing module includes a feature extractor and a selection module. The feature extractor calculates a feature value of each element belonging to one of a plurality of sets included in the input graph. The selection module selects one or more edges extending from each element as a starting point based on the calculated feature value of each element, and generates graph information, indicating the calculated feature value of each element and an edge selection result for each set. The graph inference module is configured to be differentiable and infers a solution to a task for the input graph from the generated graph information for each set.
Resumen de: US20260161860A1
0000 A method for rapidly evaluating flood drainage effect based on machine learning and ensemble prediction is provided, including the following steps: S1, collecting and organizing feature data for predicting and evaluating the flood drainage effect; S2, constructing a flood hydrodynamic numerical model based on a physical mechanism; S3, constructing a data set, and pre-processing the data set; S4, determining a target hyperparameter combination of each of multiple machine learning regression models by using a Bayesian optimizer; S5, training multiple machine learning regression models based on multiple machine learning methods and hyperparameter optimization; S6, performing ensemble prediction on each machine learning regression model to construct a prediction and evaluation model of the flood drainage effect; and S7, using the prediction and evaluation model of the step S6 to rapidly evaluate and predict the flood drainage effect. The method improves a response speed of urban flood emergency management.
Resumen de: AU2024393489A1
A method for processing a sparsely populated data source, method for generating a training set for training a model to predict mitral regurgitation from echocardiograph data, and method of predicting heart failure from echocardiograph data including the steps of: retrieving echocardiograph measurement data from a plurality of patient records comprising echocardiography reports; analysing the echocardiograph data to determine unpopulated data fields; populating the unpopulated data fields with imputed echocardiograph data determined by a machine learning model; calculating a probability output from a trained model; analysing echocardiograph measurement data of individual patient records from the echocardiograph data to determine a prediction of the presence of a disease state in the patient on the basis of the calculated probability output; and associating the presence of the disease state to a prediction of heart failure in the patient.
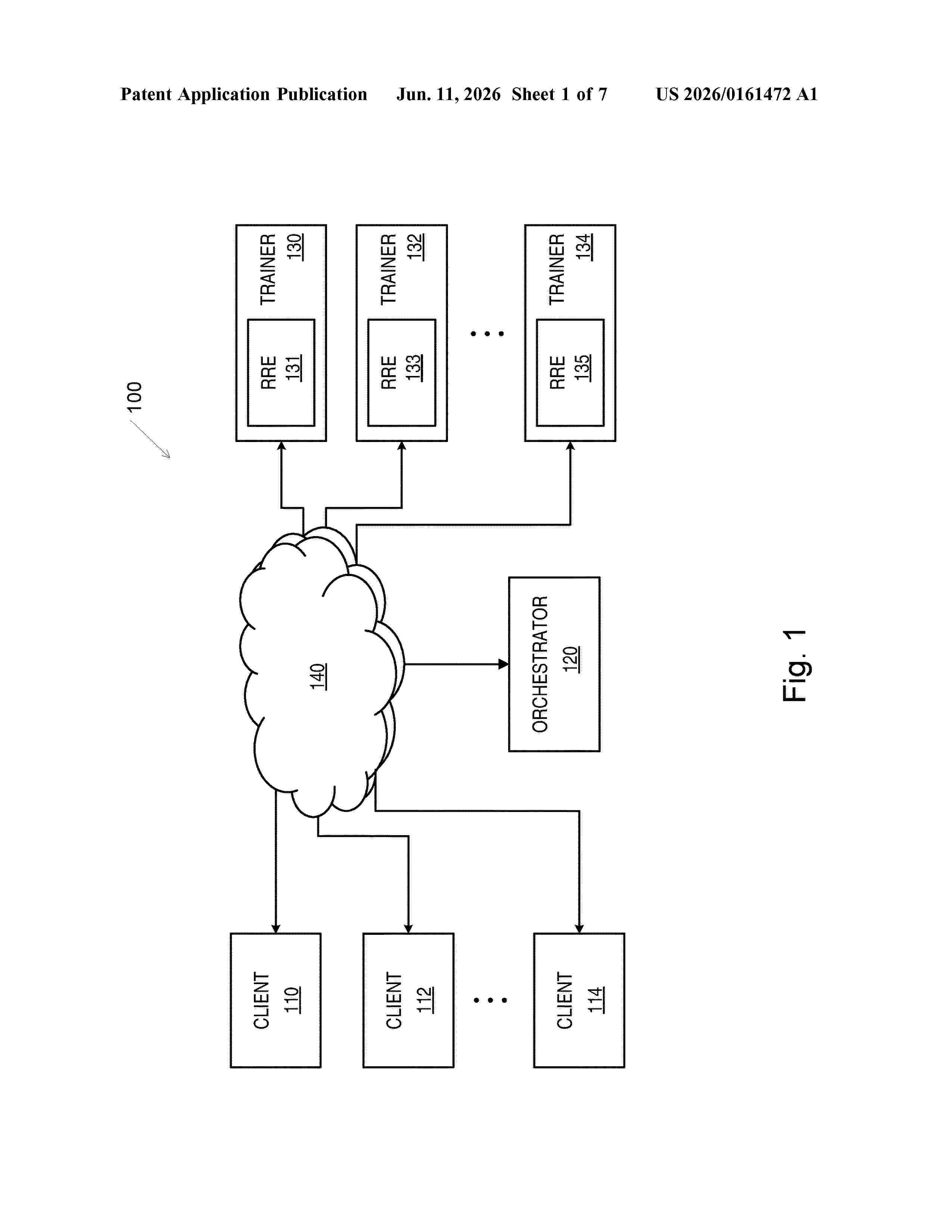
Resumen de: US20260161472A1
0000 A computer based system and method for providing decentralized computing resources including translating a task of training of or inference with a machine learning model into a code in a programming language that is executable by a ready made runtime environment (RRE) that enables interface with an Internet; finding, among a plurality of computing devices, at least one computing devices that has available computing power; transferring a portion of the translated task to the at least one computing devices; and obtaining results of execution of the portions of the translated task from the at least one computing devices. The RRE may be configured to limit interaction between execution of the portions of the translated task and processes running on each of the at least one computing and/or to limit interaction between execution of the portions of the translated task and resources of each of the at least one computing devices.
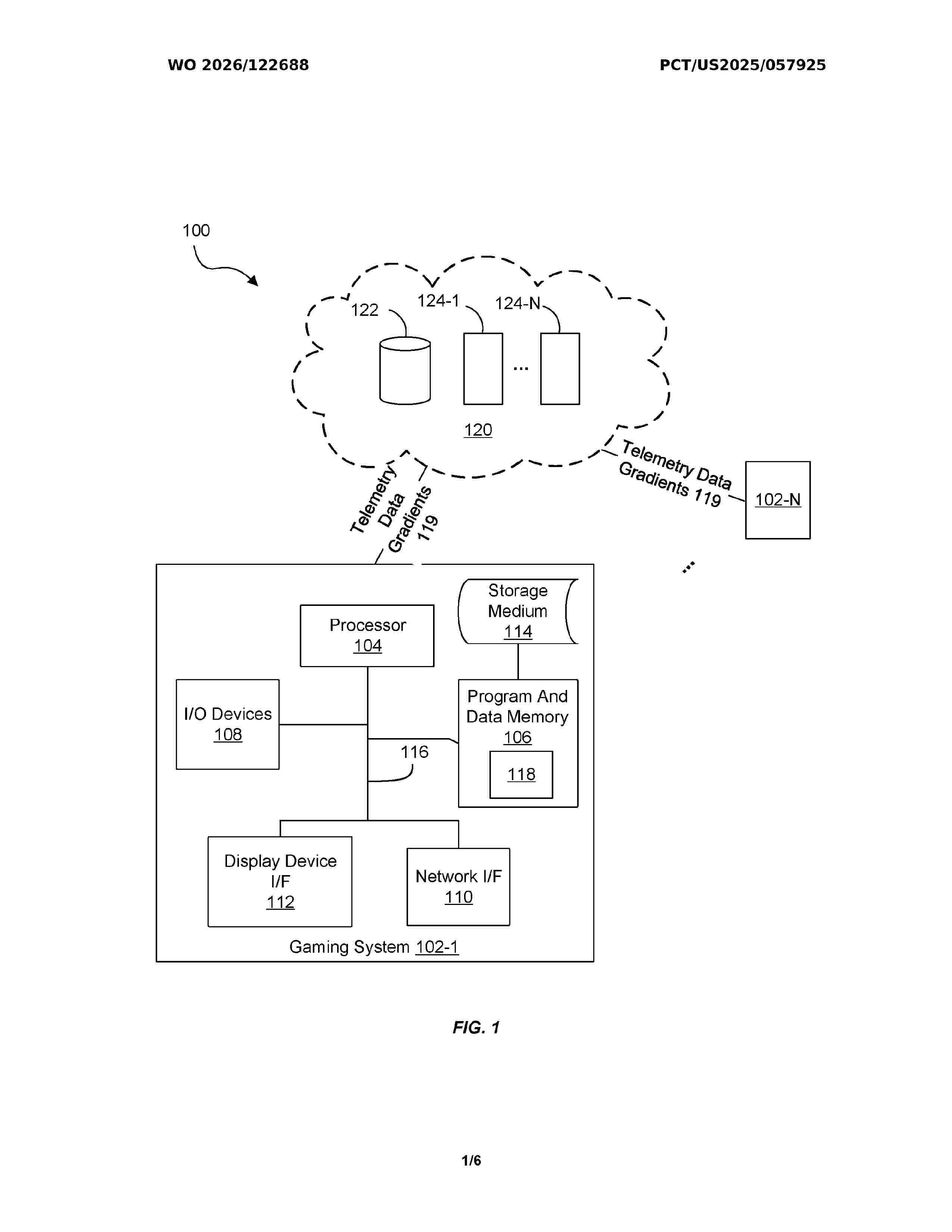
Resumen de: WO2026122688A1
A server-based system and method are provided for predicting video-gaming attributes such as game performance and session duration across a distributed population of gaming systems. The system executes a global machine-learning model trained to predict gaming attributes of a video game when executed on a client gaming system. The global model is distributed as a local instantiation to multiple client gaming systems, where each local model ascertains hardware and software characteristics of the respective client, generates predictions of gaming performance and expected session duration, and updates local parameters based on telemetry data collected during gameplay. Gradients based on the updated local parameters are transmitted to the server, which aggregates the data to refine the global model. The refined model is redistributed to client systems to improve prediction accuracy across heterogeneous gaming environments while preserving user privacy and enabling continuous, adaptive learning.
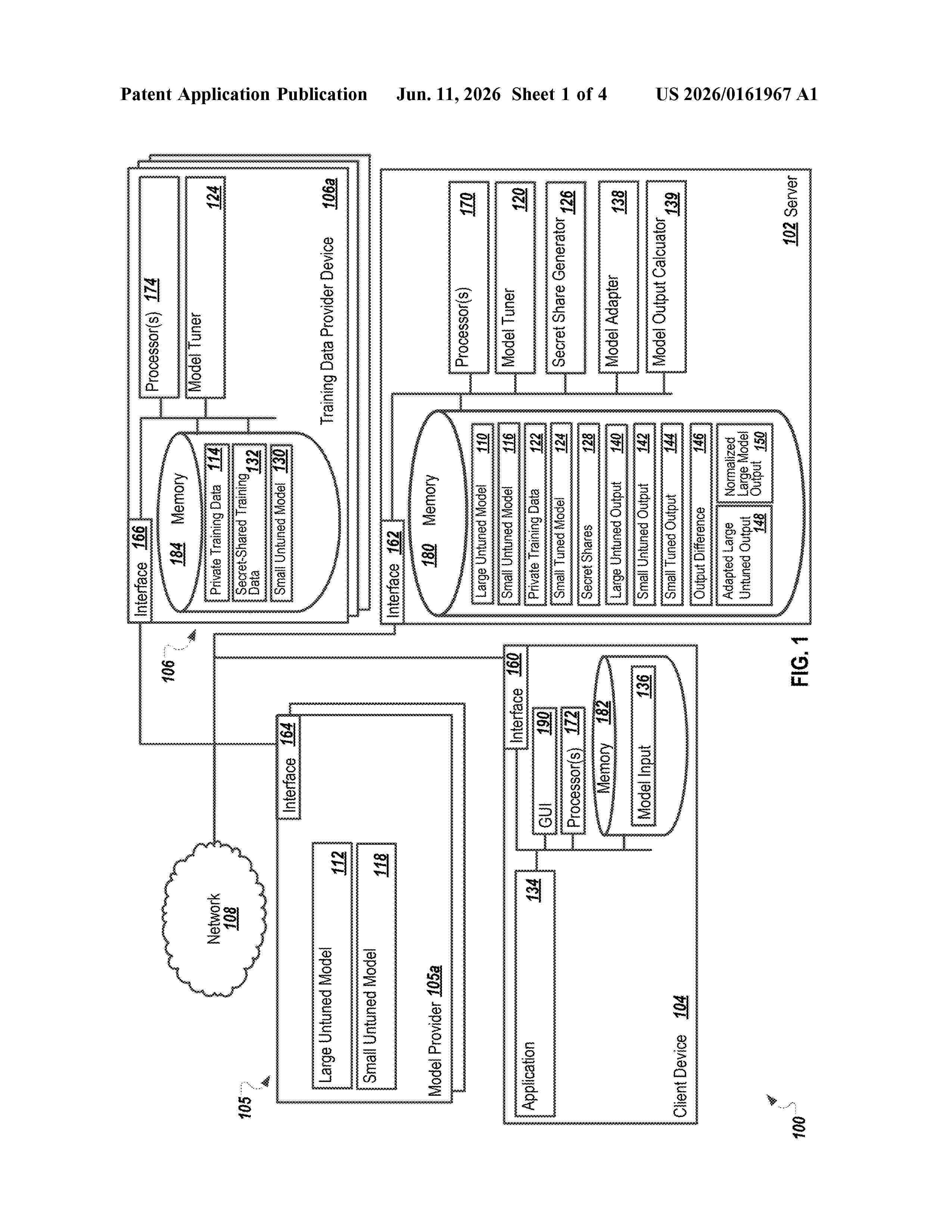
Resumen de: US20260161967A1
The present disclosure involves systems, software, and computer implemented methods for secure and private proxy fine tuning. One example method includes receiving an inference input for a first machine learning model. The input is provided to the first model, a second machine learning model that has an output structure that is consistent with a corresponding portion of the first model and a smaller overall size than the first model, and a tuned second machine learning model that is a tuned version of the second machine learning model. Output data is identified for the first model, the second model, and tuned second model. An output difference is determined based on the output data for the second model and the tuned second model. The output difference is applied to the output data for the first model to generate adapted output data that is used to generate a normalized output.
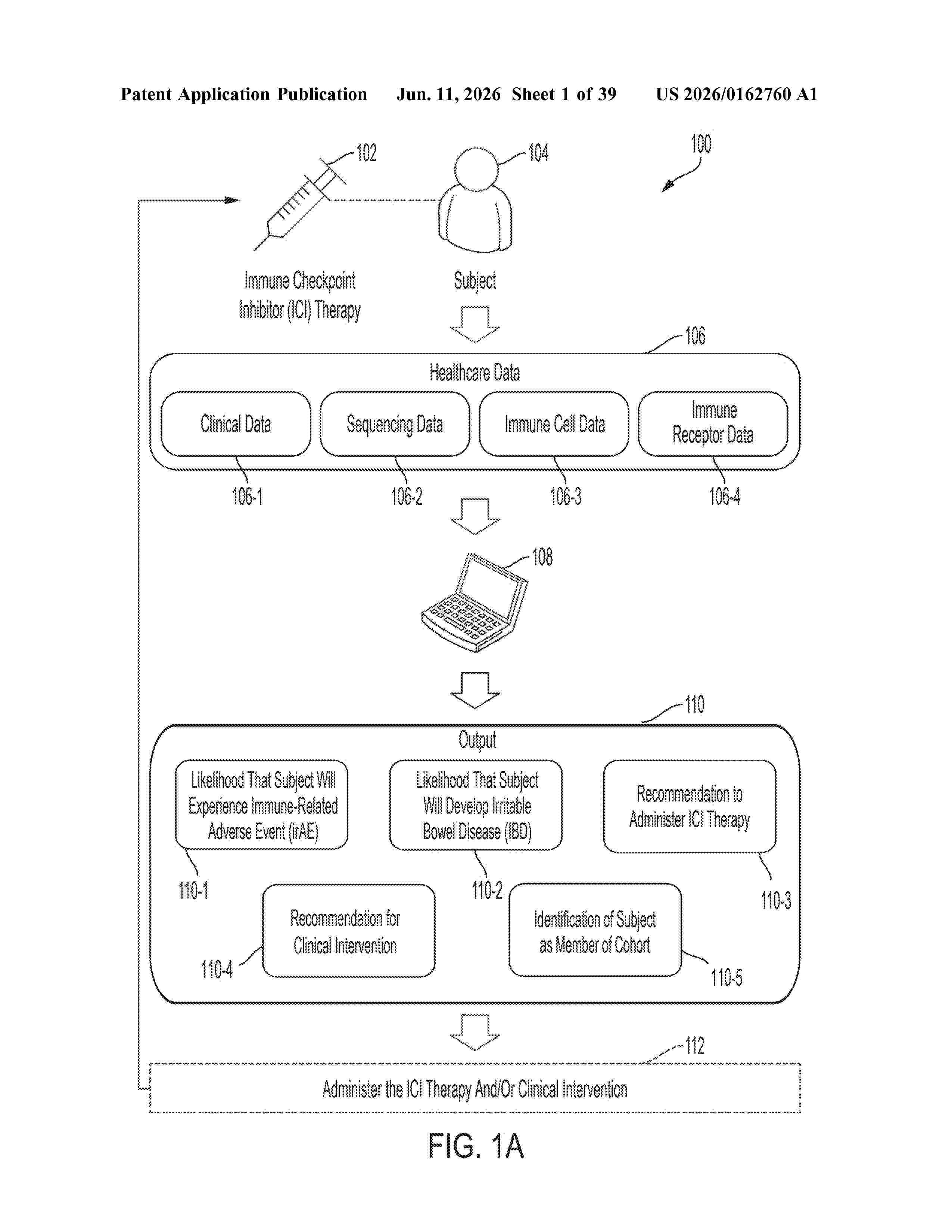
Resumen de: US20260162760A1
Described herein are techniques for predicting whether a subject will experience an immune-related adverse event (irAE) in response to administration of an immune checkpoint inhibitor (ICI) therapy. In some embodiments, the techniques include: determining a likelihood that the subject will experience the irAE in response to administration of the ICI therapy, the determining comprising: performing: (a) processing clinical data using a first machine learning (ML) model to output a first likelihood that the subject will experience the irAE, (b) processing RNA sequencing data using a second ML model to output a second likelihood that the subject will experience the irAE, and/or (c) processing immune receptor data using a third ML model to output a third likelihood that the subject will experience the irAE; and processing the first, second, and/or third likelihoods using a fourth ML model trained to predict the likelihood that the subject will experience the irAE.
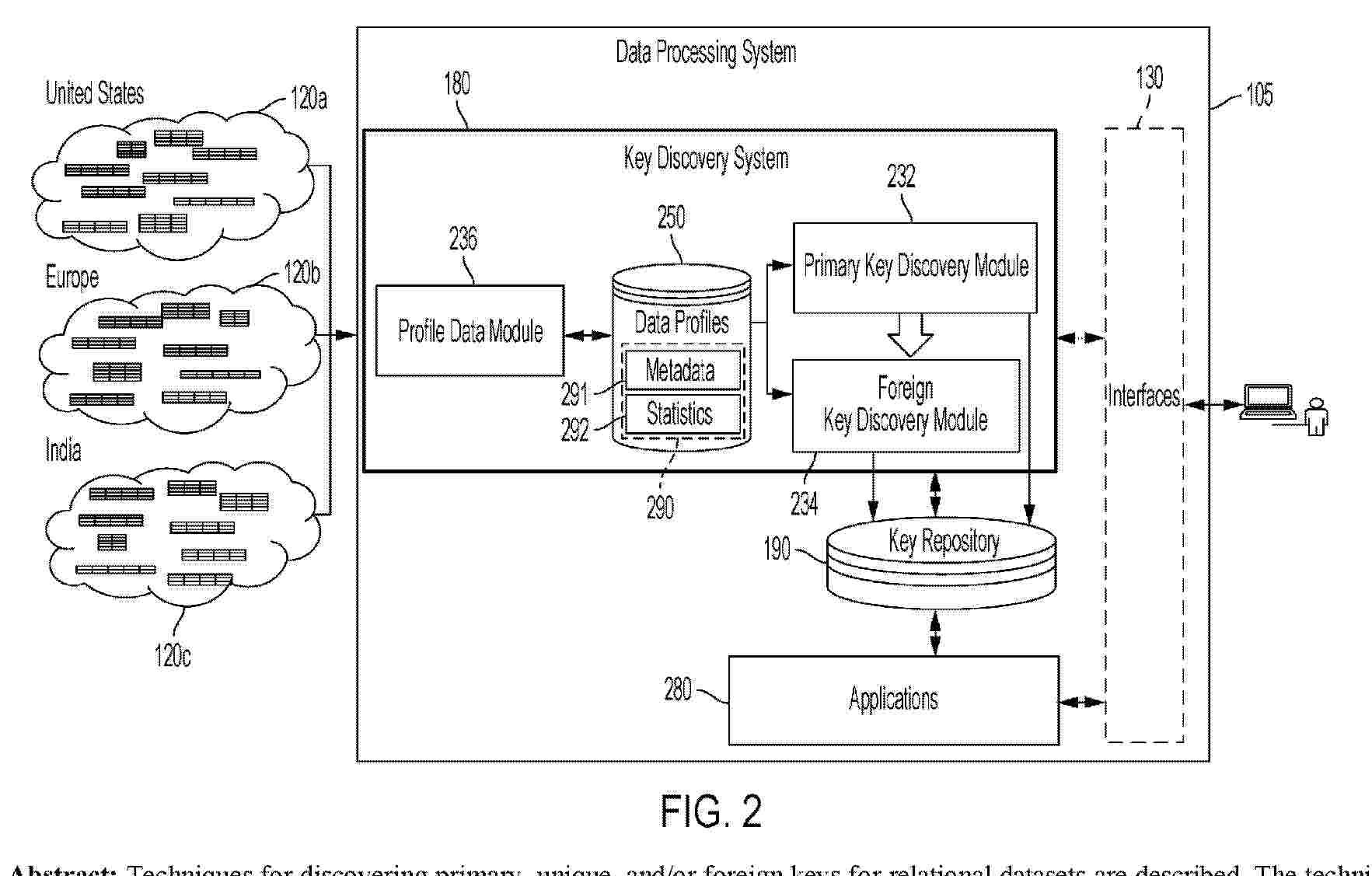
Resumen de: WO2025029579A1
Techniques for discovering primary, unique, and/or foreign keys for relational datasets are described. The techniques include profiling the relational datasets to obtain respective data profiles; identifying one or more primary key candidates for a first relational dataset using a first data profile of the first relational dataset and a first trained machine learning model; identifying one or more foreign key proposals for a second relational dataset using the one or more primary key candidates by performing a subset analysis of the second relational dataset with respect to the first relational dataset; identifying one or more foreign key candidates for the second relational dataset using the first data profile, a second data profile of the second relational dataset, and a second trained machine learning model different from the first trained machine learning model; and outputting the at primary key candidate(s) and the foreign key candidate(s).
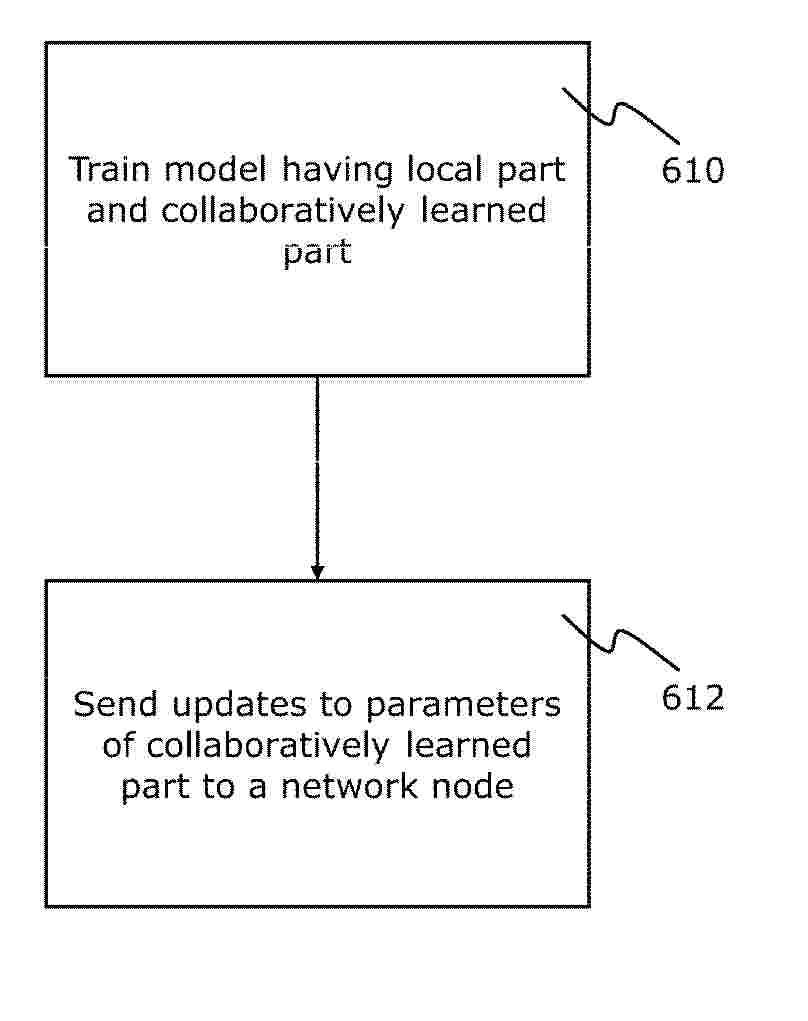
Resumen de: EP4756676A1
0001 A method, apparatus, and computer program are described comprising: receiving an input; and determining a classification of the input using a machine learning model, the machine learning model comprising a local part and a collaboratively learned part, the determining comprising: determining extracted features of the input using a feature extractor of the collaboratively learned part, the feature extractor being caused to extract features of the input; determining a set of similarity scores using a prototype layer of the local part of the model, the prototype layer being caused to determine similarities between extracted features of the input and a set of trained prototypes of the prototype layer; and determining a classification of the input using a prototypical classifier of the local part of the model, the prototypical classifier being caused determine the classification based on the similarity scores.
Resumen de: EP4756640A2
0001 A system for querying a federated data store includes a metadata knowledge graph describing the contents and relationships among one or more underlying data stores, an interactive user interface receiving requests from a data consumer, a predefined constrainable query ('nodegroup') store containing predefined constrainable queries that define data subsets of interest across one or more of the underlying data repositories, a knowledge-driven querying layer generating and executing queries against the federated data store and merging responsive results, a scalable analytic execution layer receiving the search results from the federated data store and applying machine learning/artificial intelligence techniques to analyze the results, and a user interface presenting visualizations of raw or analyzed results to the consumer. A method and a non-transitory computer-readable medium are also disclosed.
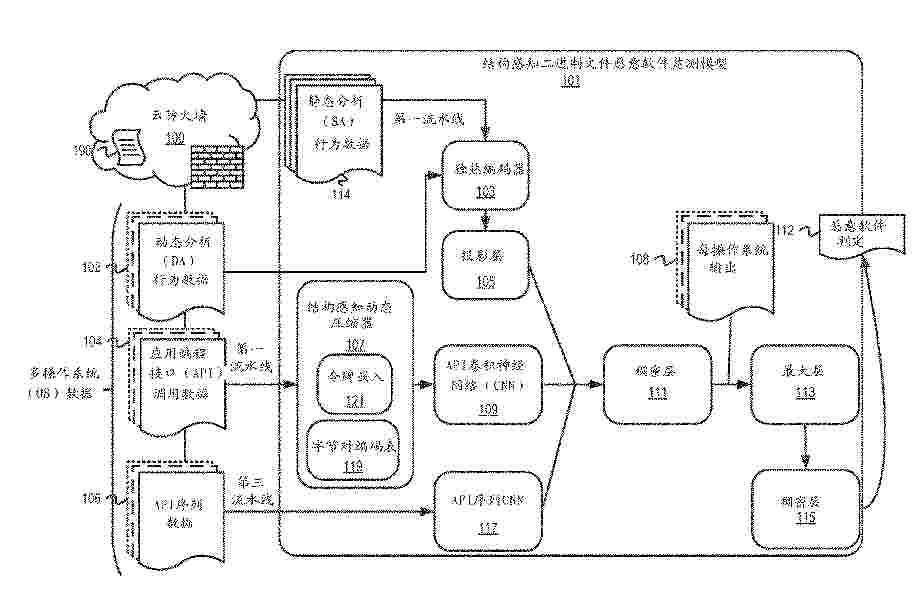
Resumen de: CN121569294A
Machine learning integrally receives input data from static analysis and dynamic analysis of the binary file to output a maliciousness/goodness determination of the binary file. The machine learning entirety includes structure-aware dynamic compressors ("compressors"). A compressor receives, as input, tree data structures generated based on application programming interface calls of binary files in various sandbox environments. A compressor performs various compression, tokenization, embedding, and shaping operations on the tree data structure to generate a compression tensor that holds a structure context from the tree data structure. Machine learning wholly uses compression tensors to generate malicious/good decisions for binary files.
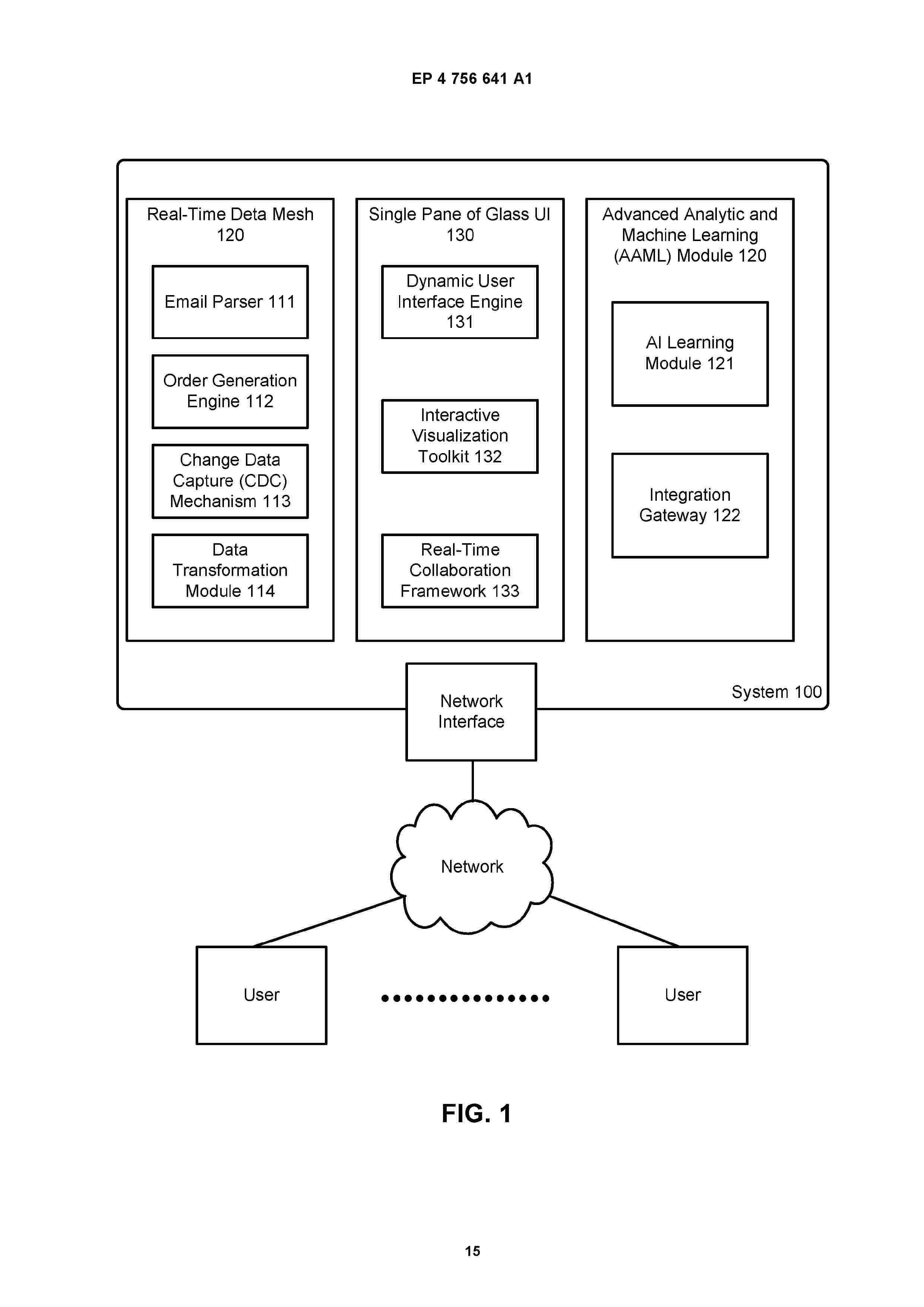
Resumen de: EP4756641A1
0001 Systems and methods provide for automating the conversion of email orders into structured order entries using generative AI, leveraging an integrated architecture comprising a Real-Time Data Mesh (RTDM), Advanced Analytic and Machine Learning (AAML) Module, and Single Pane of Glass (SPoG) User Interface. The system includes an Email Parser that extracts order information from emails, an Order Generation Engine that converts this information into structured entries, and an Integration Gateway that synchronizes the entries with external systems. The RTDM manages data flow and transformation, while the AAML provides predictive analytics and process automation. The SPoG UI performs real-time data visualization and user interaction. The system enhances order processing efficiency, accuracy, and scalability, enabling businesses to process email orders with minimal manual effort and greater precision.
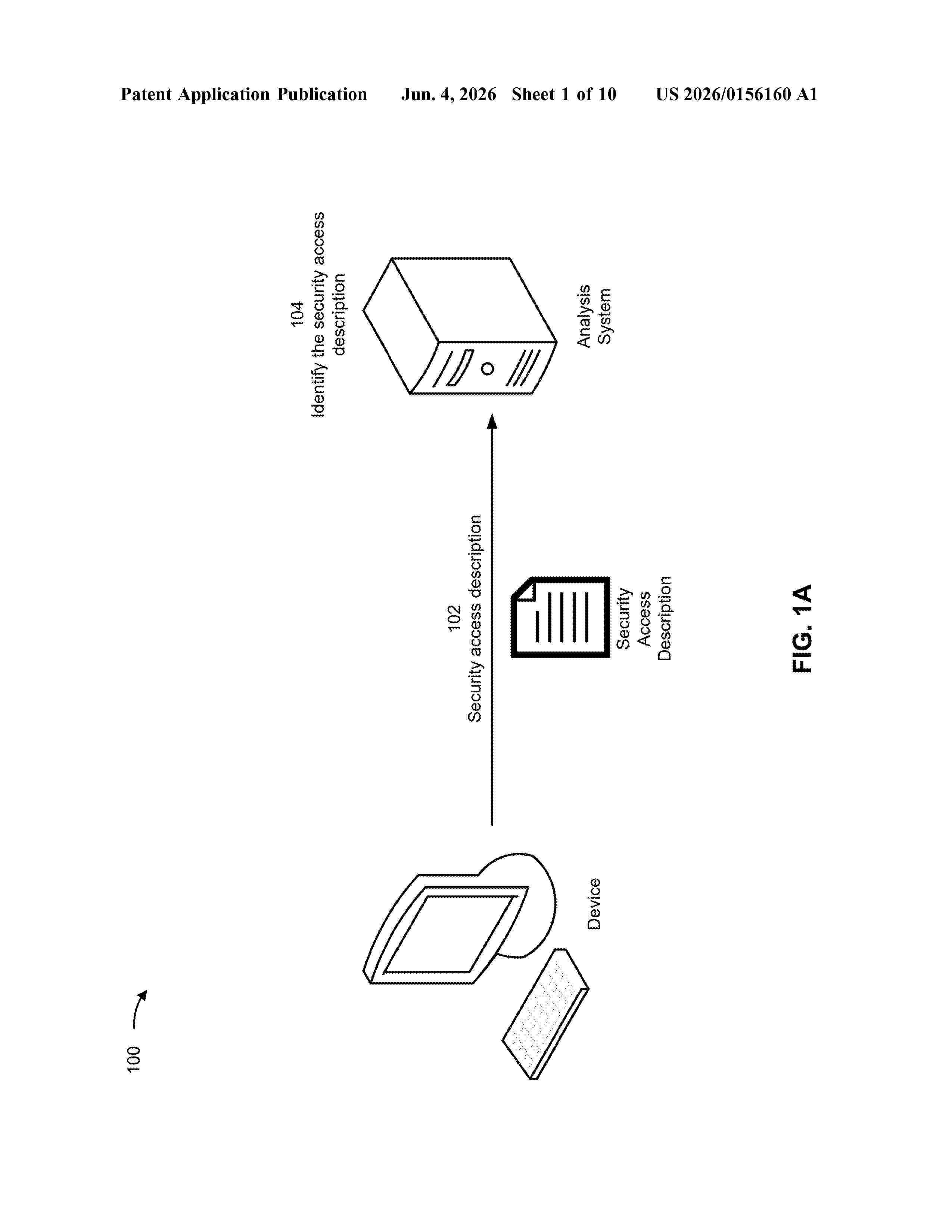
Resumen de: US20260156160A1
Some implementations described herein relate to a system for artificial intelligence analysis of security access descriptions. The system identifies a security access description. The system determines metadata information associated with the security access description. The system determines, by processing the security access description using a first set of one or more machine learning models, a descriptive quality label associated with the security access description. The system determines, by processing the security access description using a second set of one or more machine learning models, one or more descriptive components associated with the security access description and one or more descriptive component labels that correspond to the one or more descriptive components. The system provides the metadata information, the descriptive quality label, the one or more descriptive components, and/or the one or more descriptive component labels.
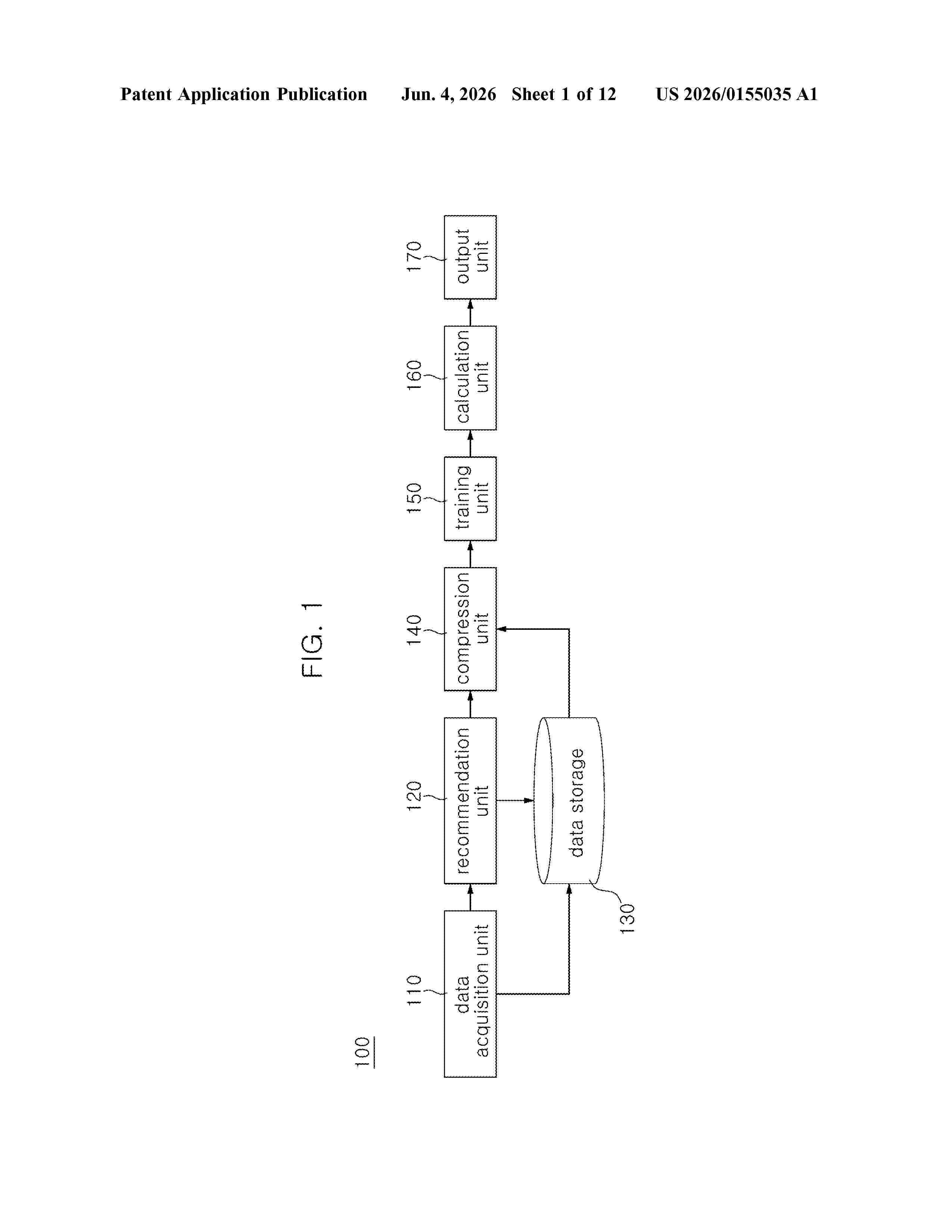
Resumen de: US20260155035A1
A system capable of optimizing early alarm operation by introducing an alarm filtering technology so as not to cause false alarm to an abnormal signal due to signal noise is disclosed. The system comprises: a data acquisition unit for selectively acquiring historical data according to the operation of a electric power facility by selecting a preset multivariate input tag; a recommendation unit for generating learning data, which is a multivariate signal for machine learning, based on a preset similarity from the historical data; a compression unit for generating re-sampling data by compressing the learning data; a learning unit for performing real-time monitoring by using the re-sampling data as input data of a pre-designed early warning learning model; and a calculation unit for generating a final warning when a predetermined condition predefined through the real-time monitoring is satisfied.
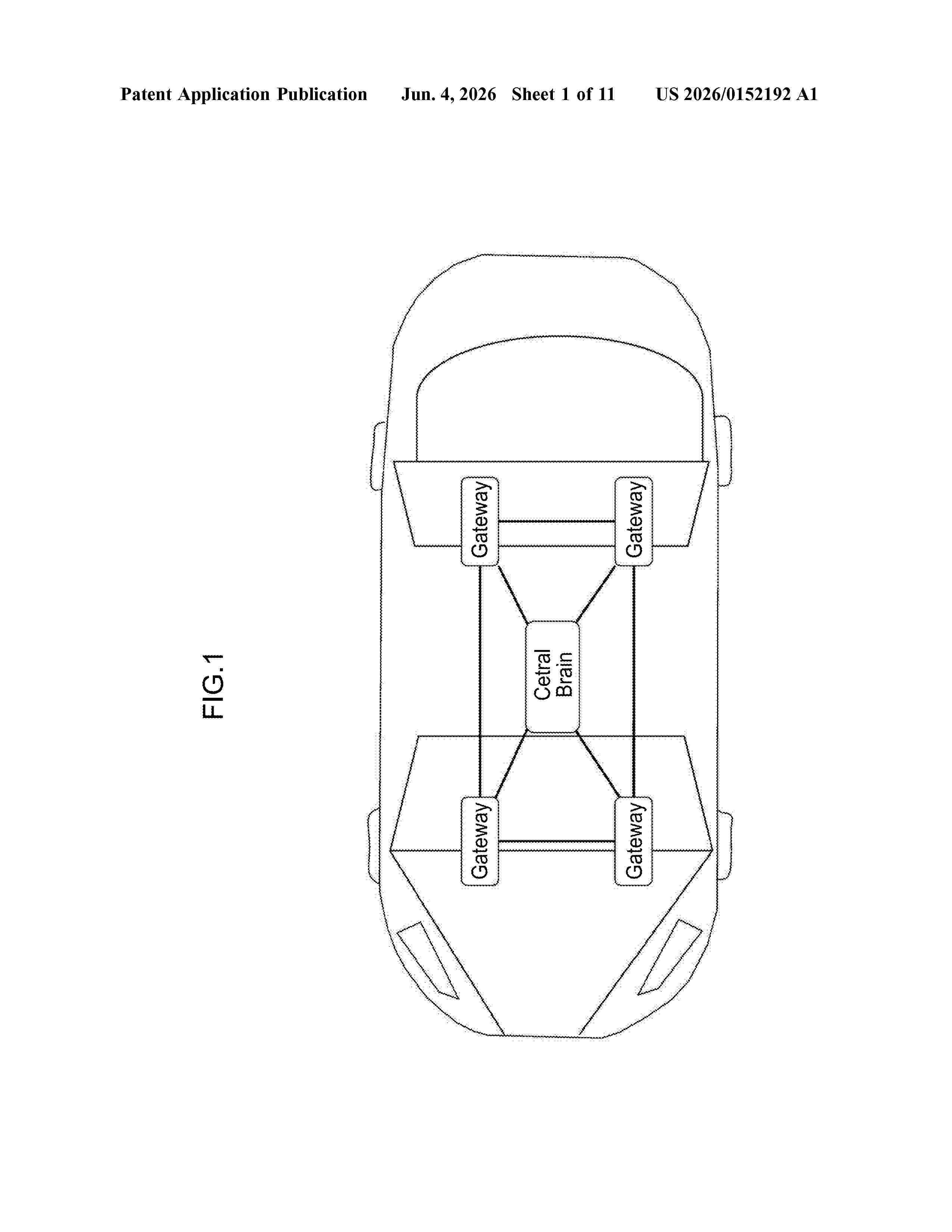
Resumen de: US20260152192A1
0000 An information processing device of the disclosure includes an information acquisition unit capable of acquiring plural pieces of information related to a vehicle, an inference unit that uses deep learning to infer plural index values from the plural pieces of information acquired by the information acquisition unit, and a driving control unit that executes driving control of the vehicle on the basis of the plural index values.
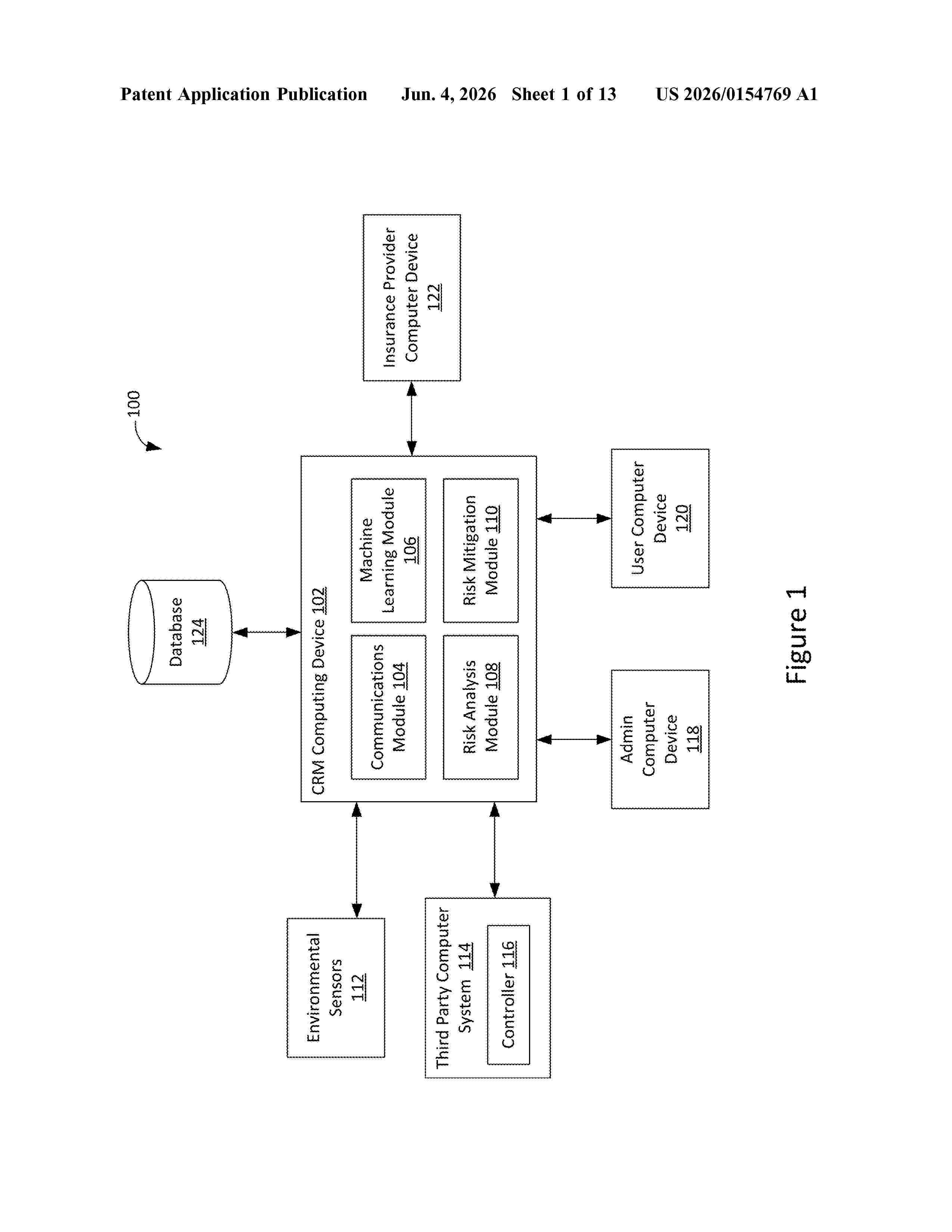
Resumen de: US20260154769A1
0000 A computer system for analyzing and mitigating risks associated with a building is provided. The computer system is configured to: (i) receive environment data from the at least one sensor; (ii) receive building data from the at least one database; (iii) utilize a trained machine learning model to determine at least one potential risk associated with the building based upon the environment data and the building data; (iv) generate a building risk profile that includes the at least one potential risk associated with the building; and/or (v) generate a risk mitigation output based upon at least one of the building risk profile and the at least one potential risk, wherein the risk mitigation output includes at least one of a risk alert, a risk mitigation recommendation, and risk mitigation instructions. Computer systems for analyzing and mitigation risks associated with a city, a user, and an event are also provided.
Nº publicación: US20260154575A1 04/06/2026
Solicitante:
NCR ATLEOS CORP [US]
NCR Atleos Corporation
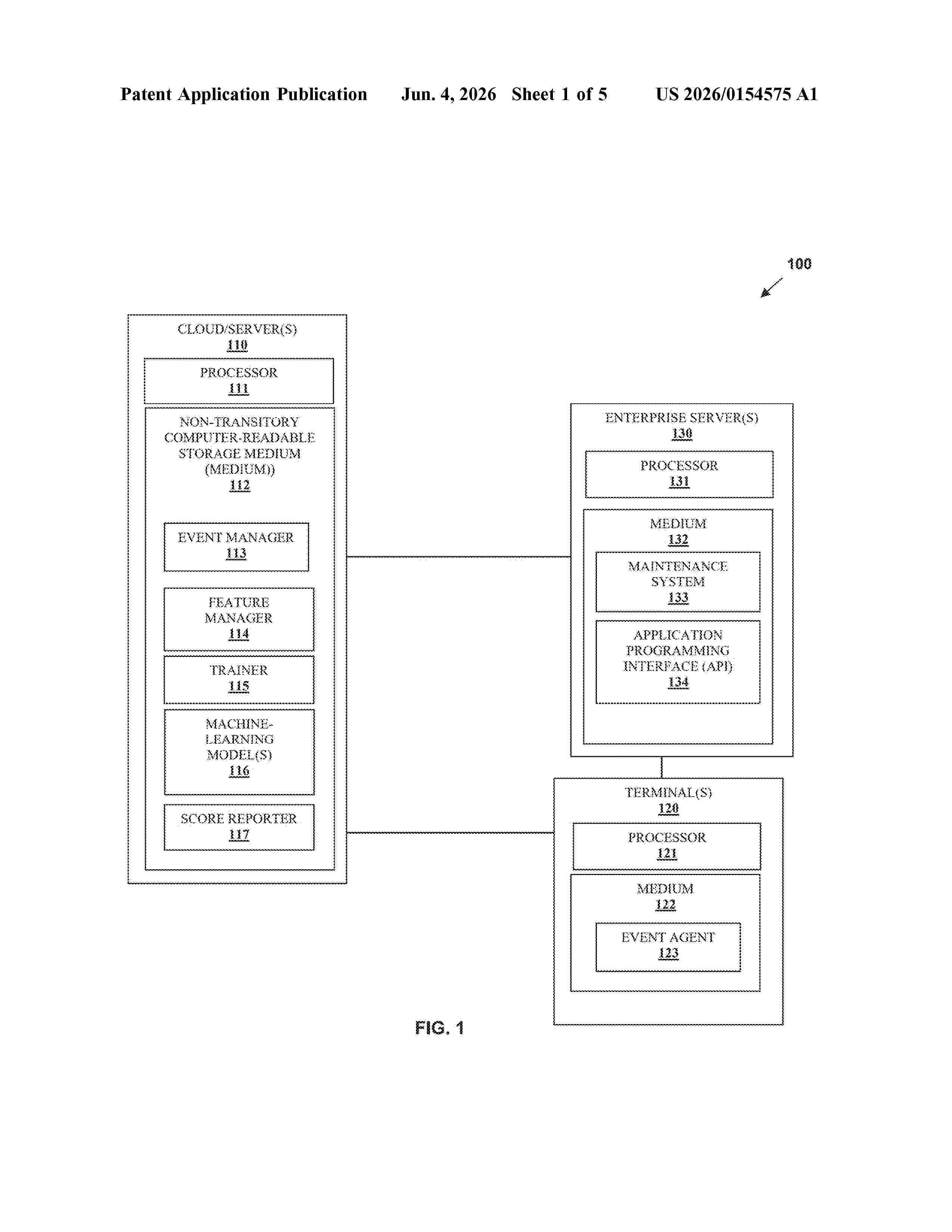
Resumen de: US20260154575A1
Event streams of terminals for a given interval of time are preprocessed to label event types and label predefined time-based or sequence-based patterns associated with terminal power supply unit (PSU) failures. The labeled event streams are provided as input to a trained machine-learning model (MLM), which outputs a score for each terminal representing a likelihood that the corresponding terminal is or is not going to experience a PSU failure. In an embodiment, each score is compared against one or more threshold values and each terminal is classified as low risk, medium risk, or high risk of a PSU failure. In an embodiment, the scores and/or the classifications for the terminals are reported to an enterprise associated with the terminals at predefined intervals of time.
 BOPI
BOPI
 Sede Electrónica
Sede Electrónica