Si deseas distinguir tus productos, servicios o ambos de los de otra empresa, es posible que necesites una marca o nombre comercial. Descubre qué son, en qué consiste su procedimiento de registro y qué implica.

Información sobre los plazos de presentación de solicitudes de transformación de marcas de la Unión Europea en marca nacional española. Más información


Si tienes un nuevo dispositivo, producto o procedimiento que resuelva un problema técnico o tenga una ventaja práctica, existen distintas formas de protegerlo en España y en otros países. Descubre cómo hacerlo.

¿Tu innovación reside en la estética, la ornamentación o la apariencia de tu producto? Protégela mediante un diseño industrial. Descubre qué derechos confiere el registro y cómo realizar la tramitación.

Las indicaciones geográficas protegen el nombre de un producto originario de una zona geográfica, a la cual le debe una determinada calidad, reputación u otra característica. Descubre qué son, en qué consiste su procedimiento de registro y qué beneficios conceden.

Las patentes publicadas en todo el mundo son una valiosa fuente de información científica, técnica y comercial.

Si eres emprendedor/a o una empresa y quieres potenciar y mejorar la rentabilidad de tu negocio protegiendo de forma adecuada los activos intangibles de tu organización, en este espacio encontrarás lo necesario.



 104
resultados
104
resultados
 Última actualización
27/06/2026 [07:03:00]
Última actualización
27/06/2026 [07:03:00]


 Resultados 50 a 75 de 104
Resultados 50 a 75 de 104

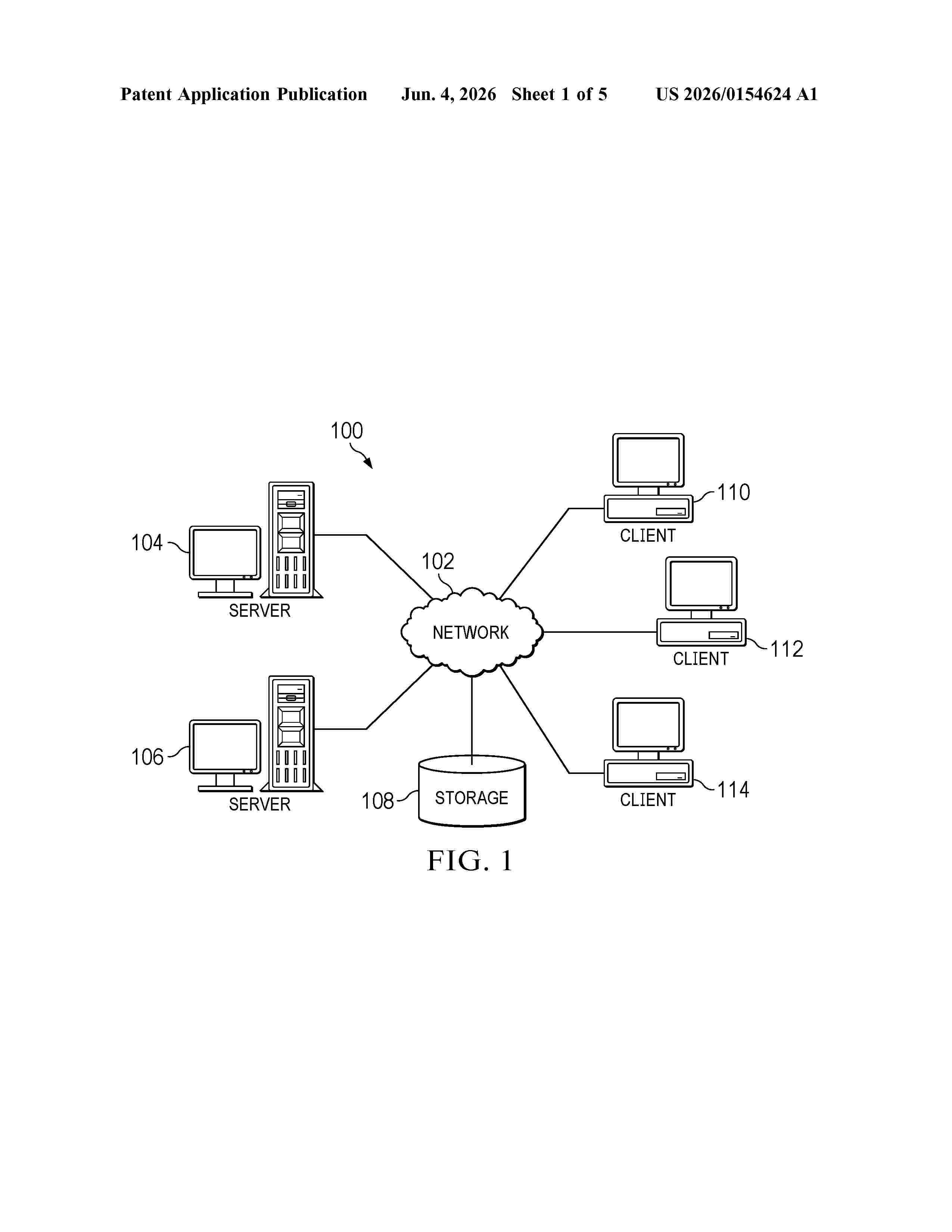
Resumen de: US20260154624A1
Intelligent data ingestion is provided. A determined column header name of a selected column in an imported data file is mapped to a predicted corresponding column header name of a particular column in a database corresponding to a human capital management application using a plurality of machine learning models. It is determined whether the predicted corresponding column header name output by each respective machine learning model of the plurality of machine learning models matches. In response to determining that the predicted corresponding column header name output by each respective machine learning model of the plurality of machine learning models does match, the predicted corresponding column header name of the particular column in the database is utilized as a target column name for the determined column header name of the selected column in the imported data file.

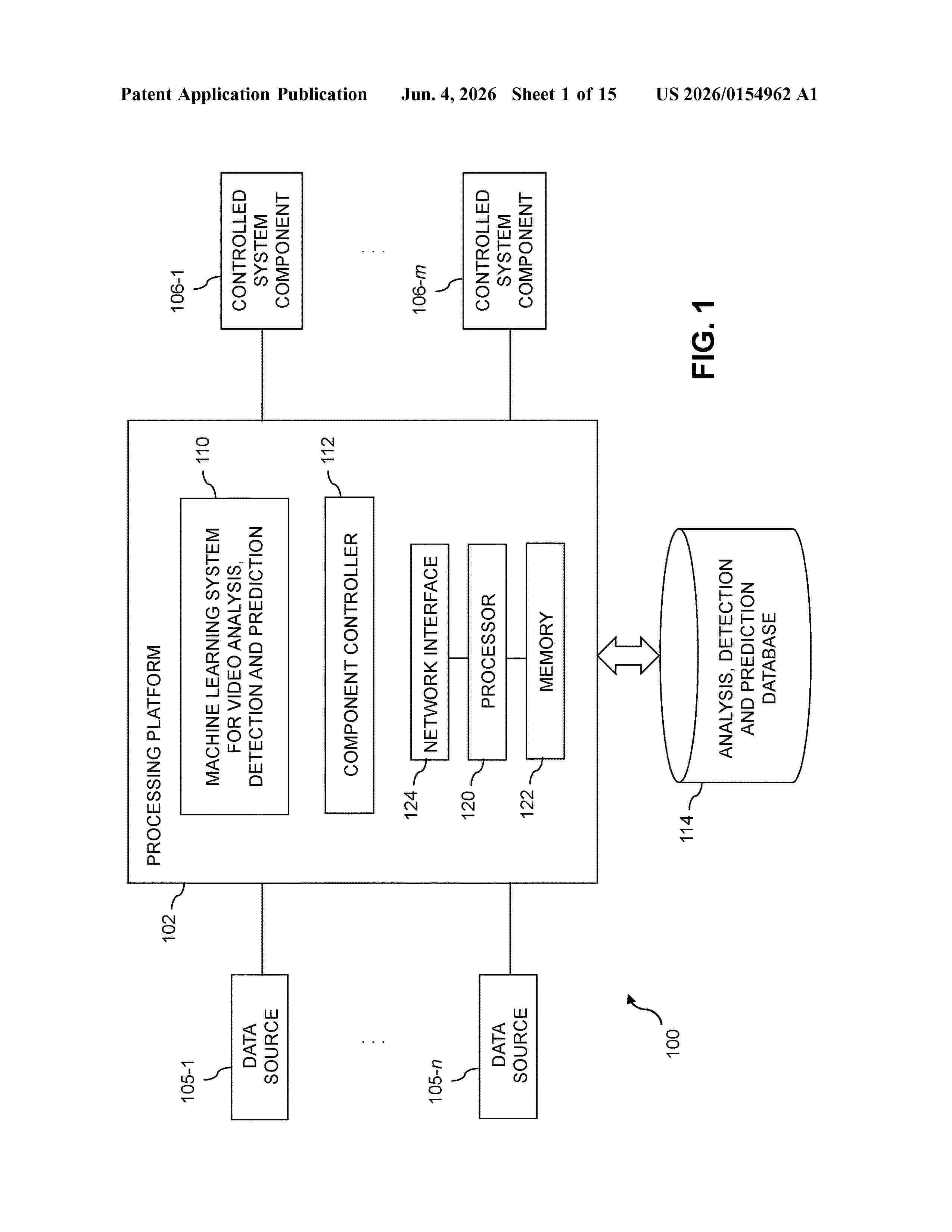
Resumen de: US20260154962A1
A method comprises obtaining video data from one or more data sources, and processing the obtained video data in a machine learning system comprising an inference stage and an anticipation stage. The inference stage is configured to assign one or more labels to at least one of a group activity and an individual activity detected in the obtained video data. The anticipation stage is configured to predict one or more future actions relating to at least one of the group activity and the individual activity based at least in part on the one or more labels assigned in the inference stage. The method further comprises generating at least one control signal based at least in part on the predicted one or more future actions. The method is illustratively configured to implement role inference and action anticipation in team sports, although it is applicable to a wide variety of other contexts.
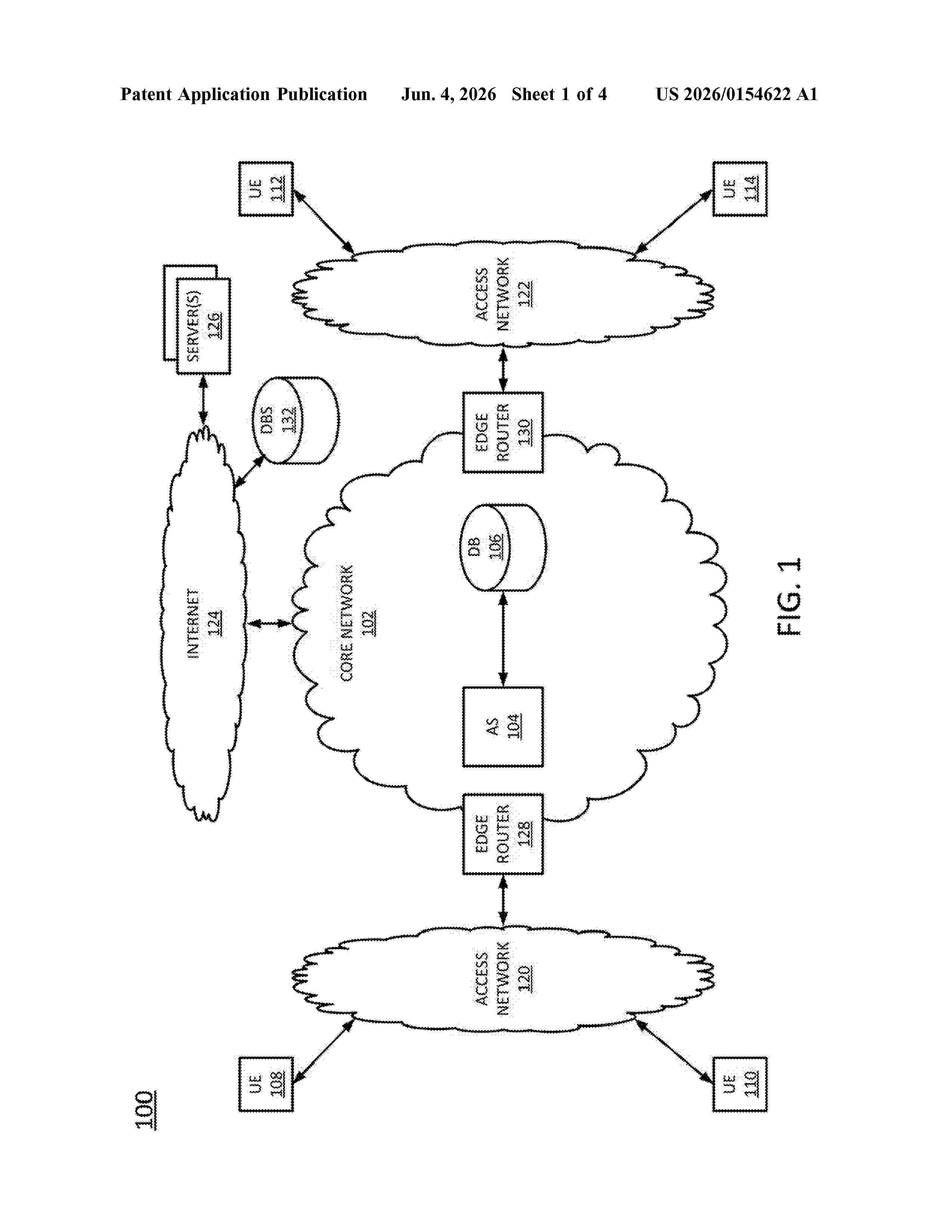
Resumen de: US20260154622A1
0000 A method includes obtaining descriptive information for a first machine learning project, identifying, based on the descriptive information, a plurality of past machine learning projects which are similar to the first machine learning project, retrieving digital documents that describe the bias evaluation pipelines that were used to evaluate the plurality of past machine learning projects, detecting a common bias evaluation pipeline step among at least a subset of the digital documents, extracting, from the subset, a snippet of machine-executable code that corresponds to the common bias evaluation pipeline step, modifying the snippet of machine-executable code with use case data that is specific to the first machine learning project to generate modified machine-executable code, and generating a proposed bias evaluation pipeline for evaluating the first machine learning project, wherein the proposed bias evaluation pipeline includes the modified machine-executable code.
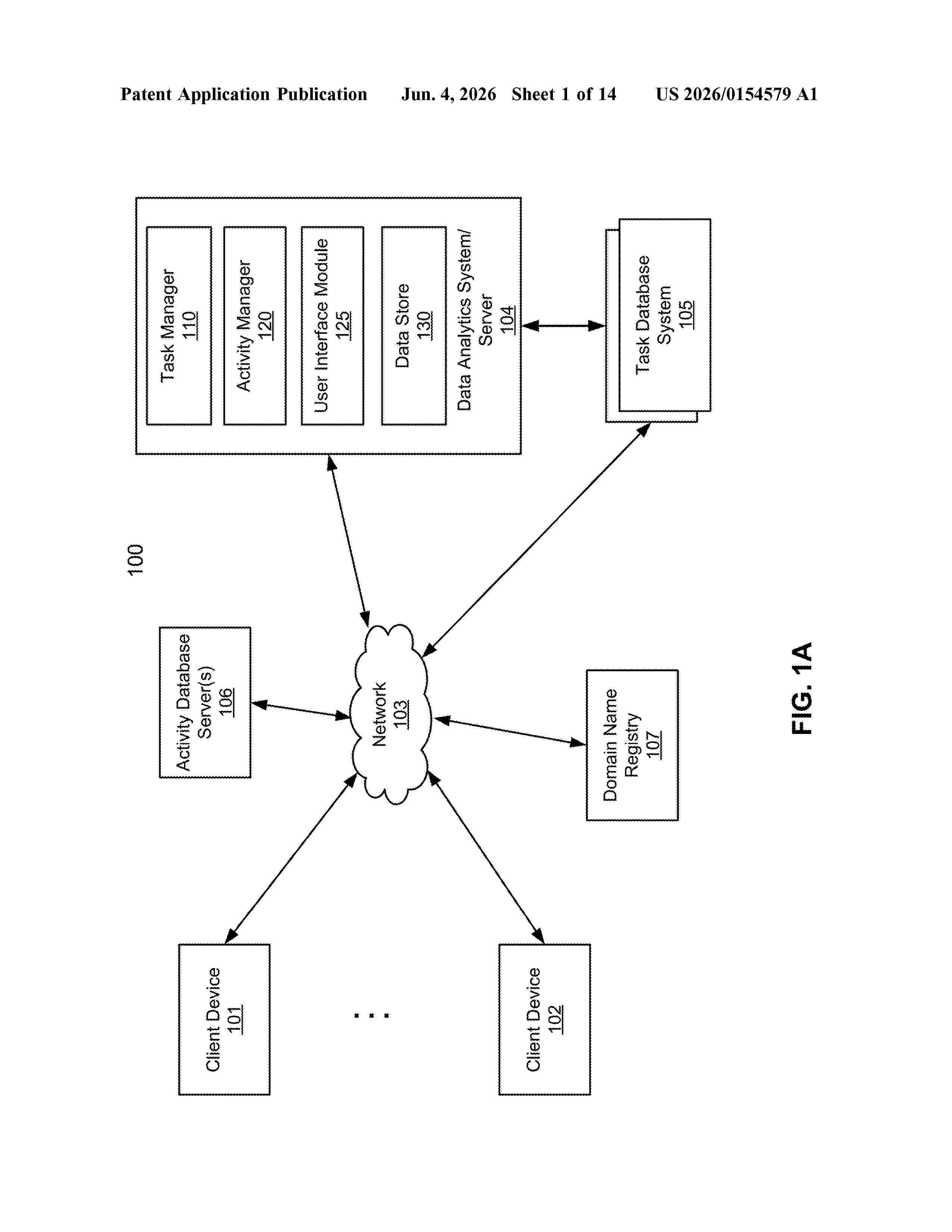
Resumen de: US20260154579A1
0000 The disclosure describes a method of generating a target profile including the target's sequence of events (SOE) for a task. Such target profile sequence of events is derived from several source group's transactions, where any source group's transactions cannot be shared with other source groups but the derived target group's profile is the only information that is shared. Source-side information is periodically extracted for a plurality of sources that each interact with a plurality of targets. The information includes source stages, resources, and stage transition events for a task with a target. Source information is used to generate a set of normalized stages, and a set of normalized events for transitioning between the stages of the set of normalized stages. An artificial intelligence (AI) model is trained using the source information. The AI model can generate a target profile with target process information inferred using the trained model. The target process information can include the target's identifiers for each stage, an estimated duration of the stage, deliverables for the stage, and one or more stage transition events for the stage.
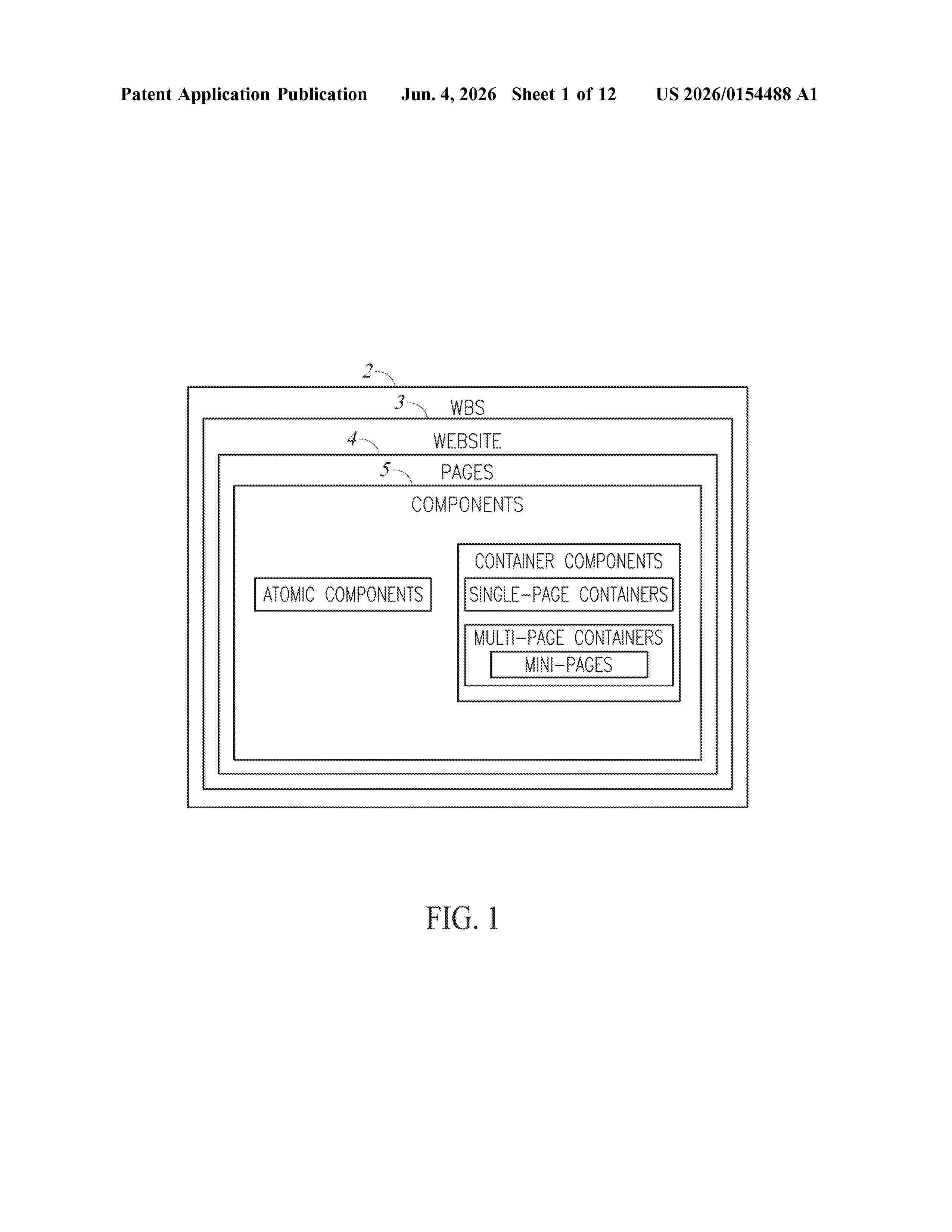
Resumen de: US20260154488A1
A website building system (WBS) includes at least one hardware processor and a site evaluator running on the at least one hardware processor to evaluate at least one application area of a website according to at least one user category of the WBS. The site evaluator includes at least one evaluation engine to evaluate the at least one application area according to rules and at least one of: scripts and machine learning (ML) models, a site modifier to implement at least one of automatic and manual modifications to the website according to recommendations from the at least one evaluation engine and an evaluation engine handler to enable user creation and editing of the at least one evaluation engine.
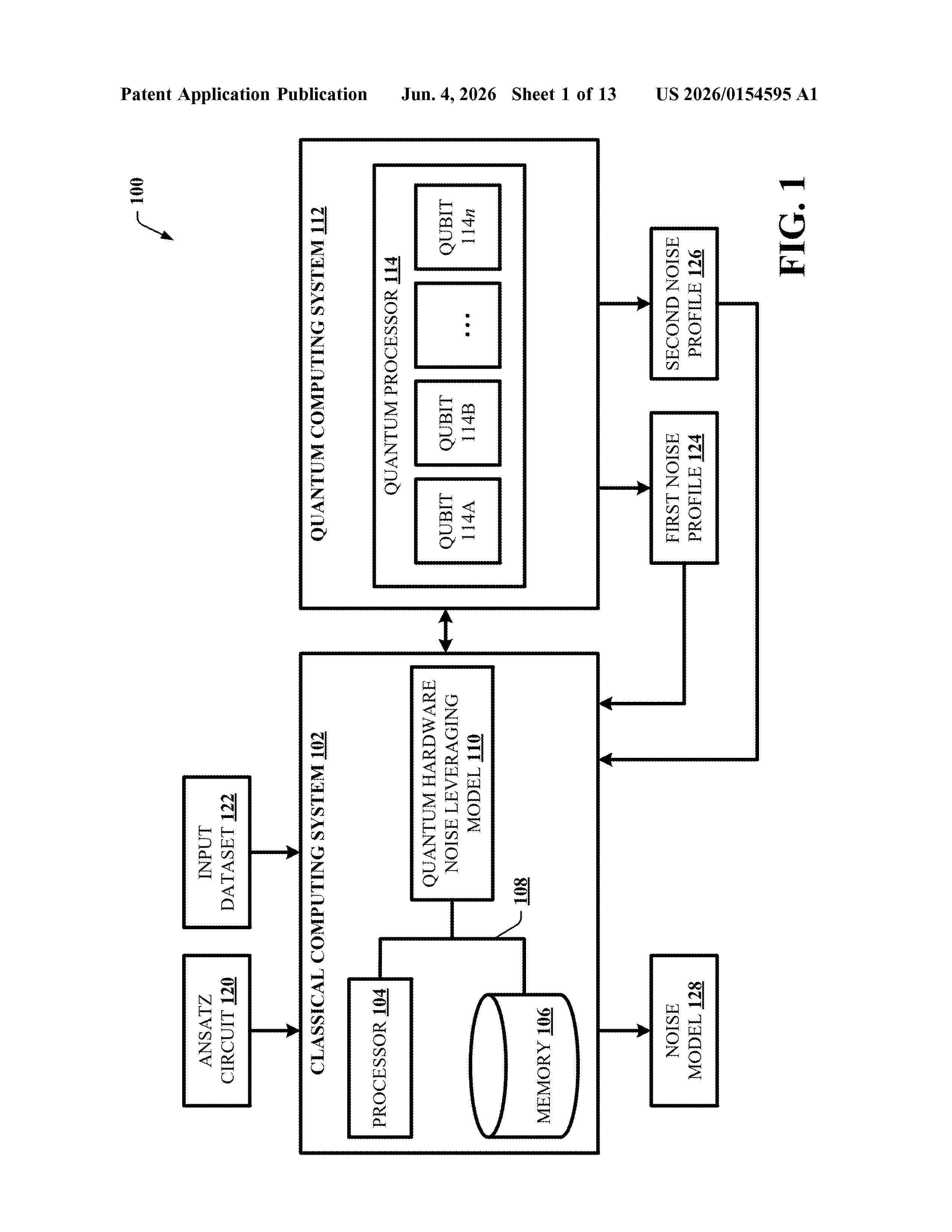
Resumen de: US20260154595A1
One or more systems, devices, computer program products and/or computer-implemented methods of use provided herein relate to learning and leveraging quantum hardware noise for quantum machine learning (QML). For example, according to an embodiment, a system is provided. The system can comprise a memory that can store computer-executable components. The system can further comprise a processor that can execute the computer-executable components stored in the memory, where the computer-executable components can comprise a noise learning component that can learn, based on an ansatz circuit and an input dataset, quantum hardware noise. The computer-executable components can further comprise a QML component that can employ the quantum hardware noise in an adaptive QML process.
Resumen de: US20260154727A1
An online system uses a trained machine-learning model for dynamically modifying an authorization buffer amount to cover additional expenses occurring during fulfillment of an online order. Upon receiving a signal indicating that a user entered an online checkout stage of the order, the online system applies the machine-learning model to generate a set of values of a metric for a set of authorization buffer amounts, each value of the metric resulting from charging the user a respective authorization buffer amount over an expected value of the order if a value of the order at delivery is greater than the expected value. The online system selects an authorization buffer amount resulting in the largest value of the metric, and generates an authorization signal that authorizes charging the user the authorization buffer amount over the expected value if the value of the order is greater than the expected value.
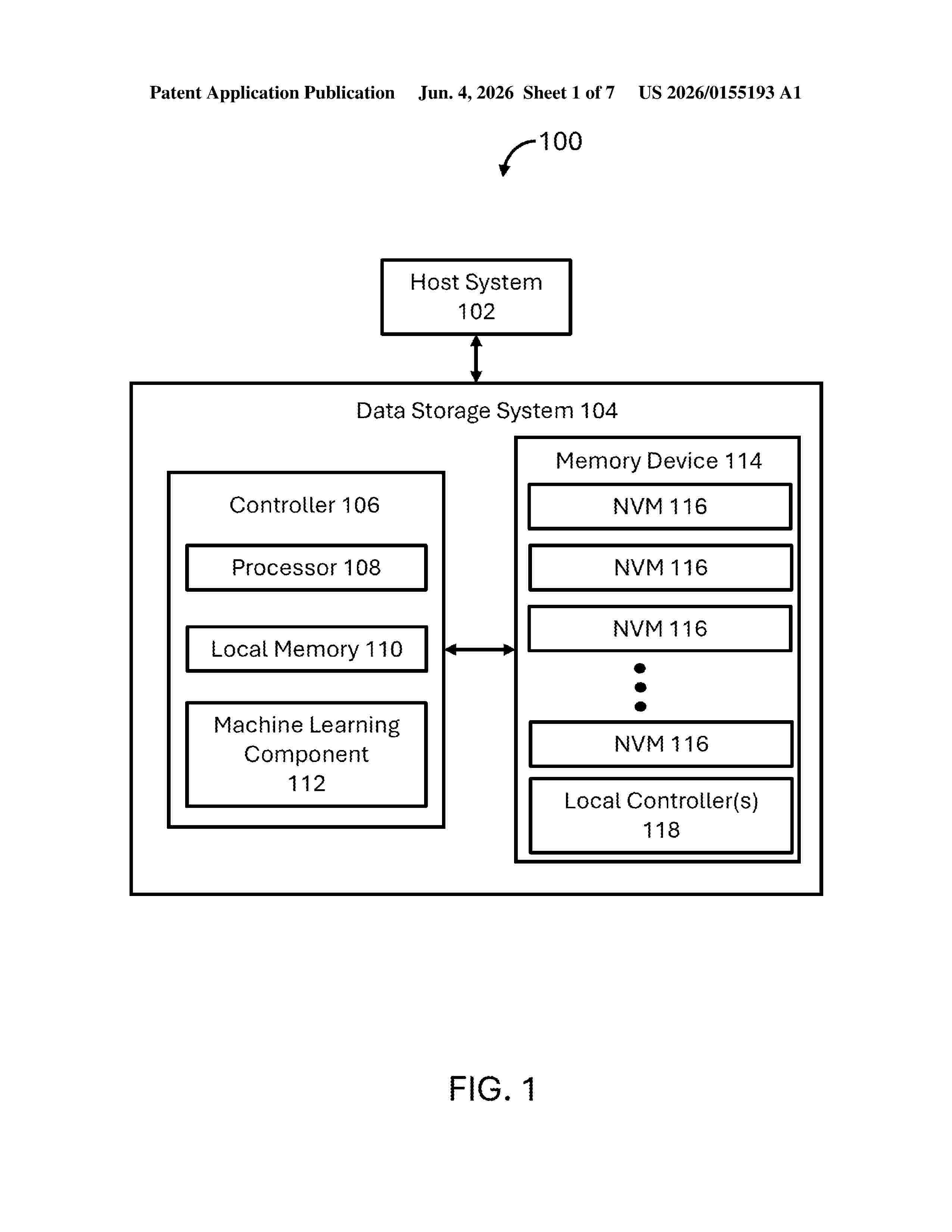
Resumen de: US20260155193A1
A data storage system includes a memory device (e.g., a solid state drive) including a wordline (WL), a memory (e.g., a random access memory) including instructions stored thereon, and at least one processor. The memory includes instructions stored thereon that, when executed by the at least one processor, cause the at least one processor to: select a machine learning (ML) model based at least in part on error values for the WL; determine, by the ML model, a read voltage threshold; and read data from the WL using the read voltage threshold.
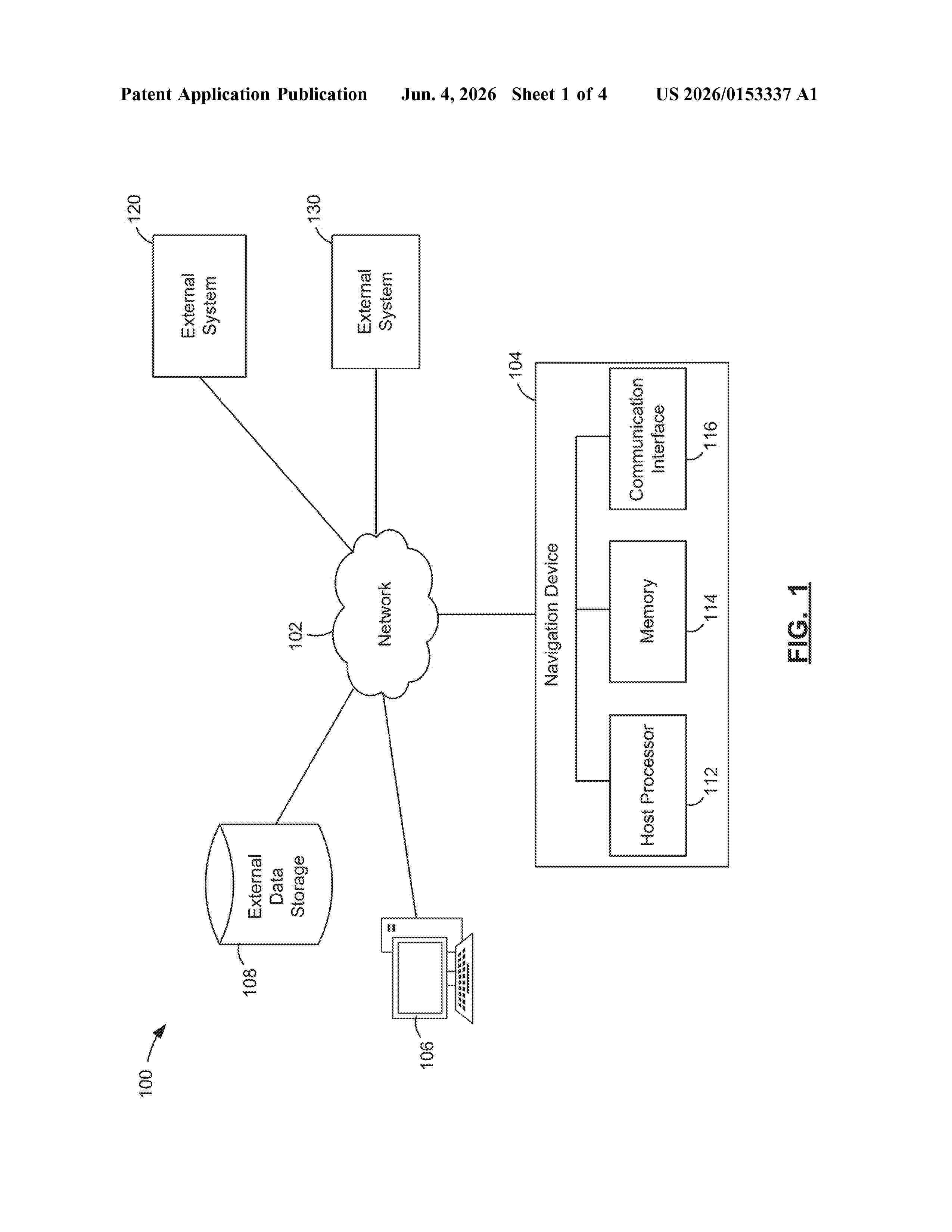
Resumen de: US20260153337A1
Provided are methods, systems, and devices for indoor tracking and navigation. The method includes receiving a plurality of sensor signals and a navigational repository; integrating, by a fusion algorithm, the plurality of sensor signals and the navigational repository to generate a tempospatial guidance dataset; training a machine learning module on the tempospatial guidance dataset, wherein the machine learning model is configured to learn spatial patterns by analyzing relationships between the plurality of data signals and the navigational repository; and determining, by the machine learning module, a navigation signal for guiding a user, wherein the navigation signal is generated by analyzing a user location and predicted movement patterns.
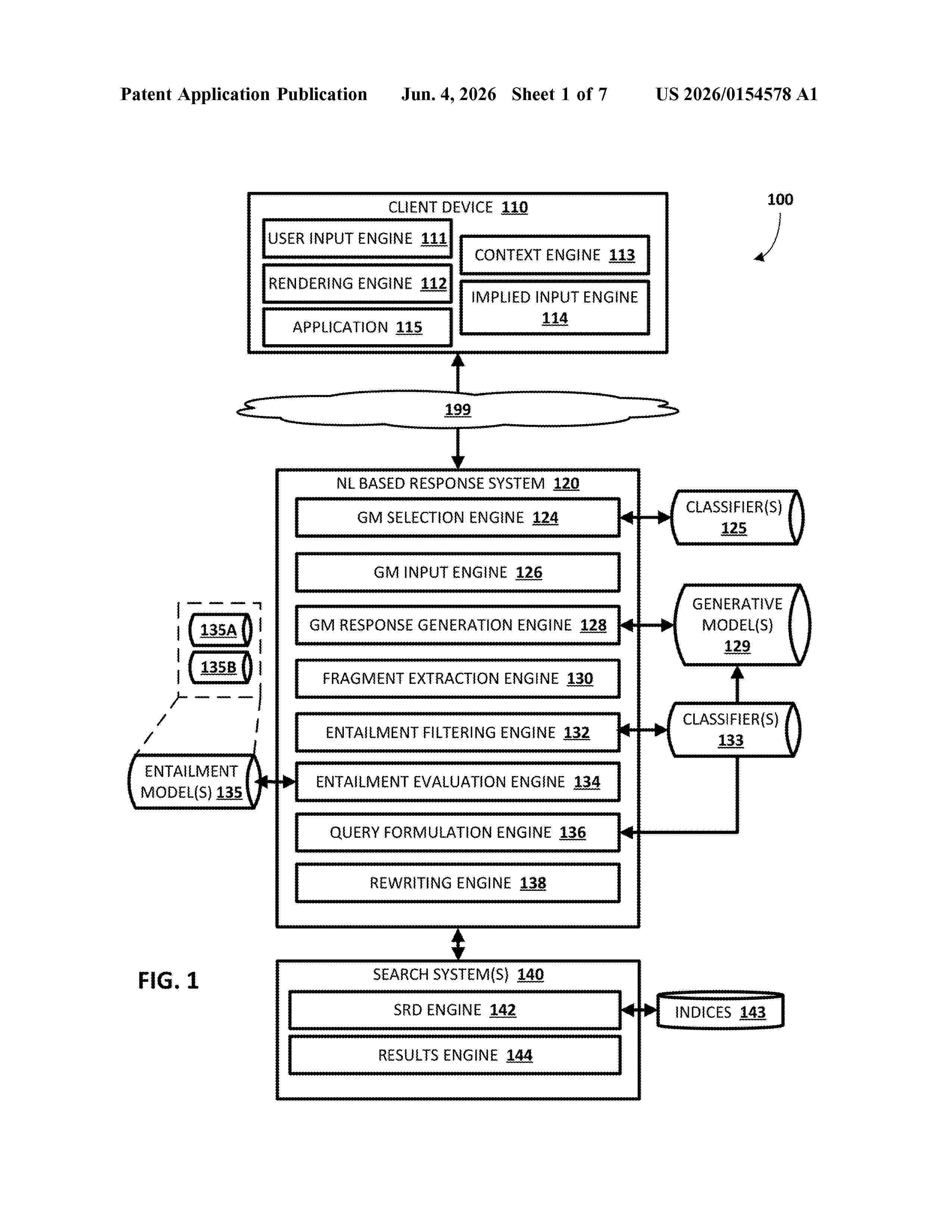
Resumen de: US20260154578A1
Implementations are described herein for automatically identifying and correcting potentially false information in generative model output by performing entailment evaluation of generative model output. In various implementations, data indicative of a query may be processed to generate generative model output. Textual fragments may be extracted from the generative model output, and a subset of the textual fragments may be classified as being suitable for textual entailment analysis. Textual entailment analysis may be performed on each textual fragment of the subset, including formulating a search query based on the textual fragment, retrieving document(s) responsive to the search query, and processing the textual fragment and the document(s) using entailment machine learning model(s) to generate prediction(s) of whether the at least one document corroborates or contradicts the textual fragment. Based on the textual entailment analysis, at least a portion of the generative model output which is to be rewritten is determined.
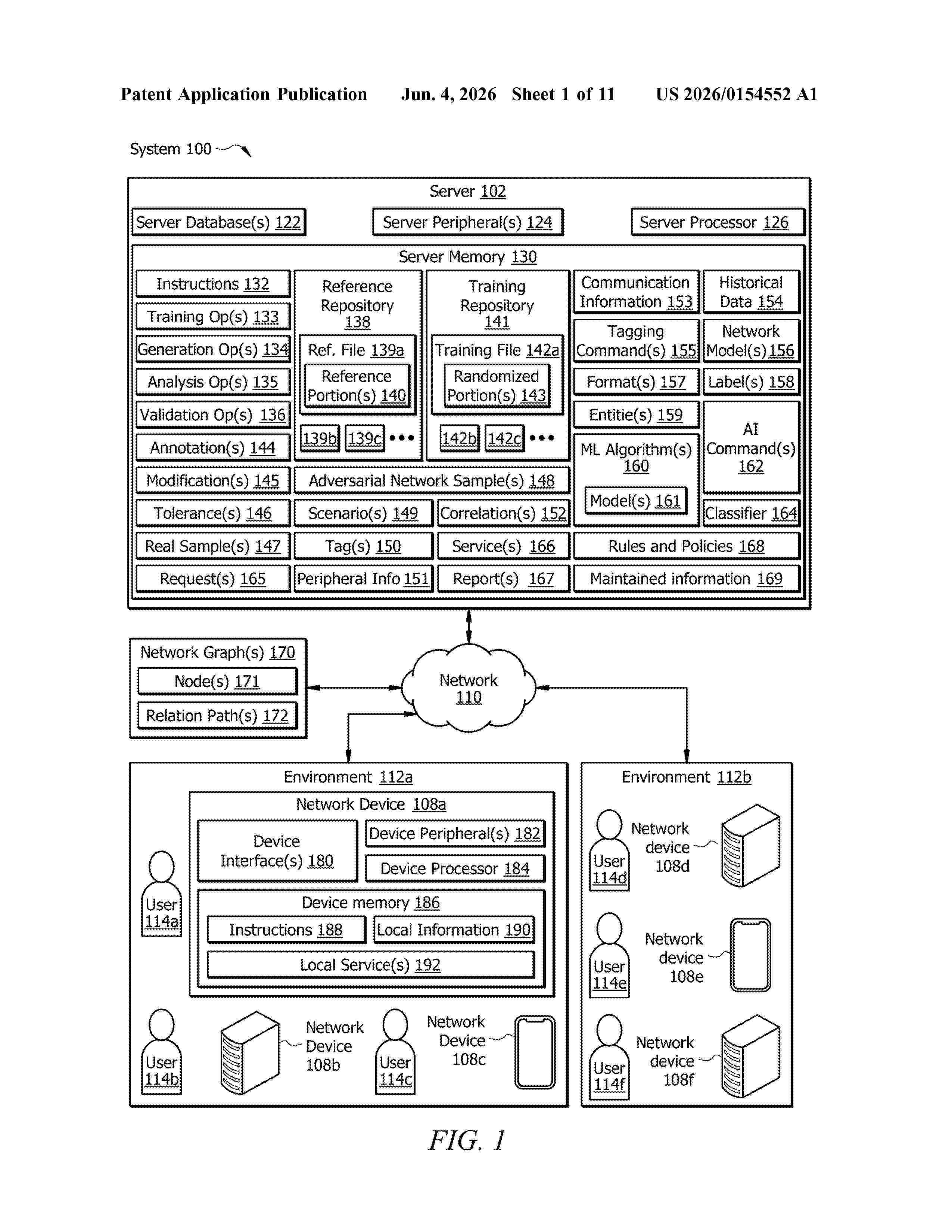
Resumen de: US20260154552A1
0000 An apparatus comprises a memory communicatively coupled to a processor. The processor is configured to receive reference information from a reference repository, determine an annotation for the reference information, generate a communication information based on the reference information and the annotation. The annotation comprises a tolerated change to the reference information. The communication information preserves an amount of information that matches the reference information. Further, the processor is configured to generate a label referencing the amount of information in the communication information and execute the machine learning algorithm to determine whether the amount of information referenced by the label is within an accuracy tolerance. The processor is configured to, in response to determining that the amount of information is within the accuracy tolerance, train the one or more machine learning models using the reference information, the communication information, and the label.
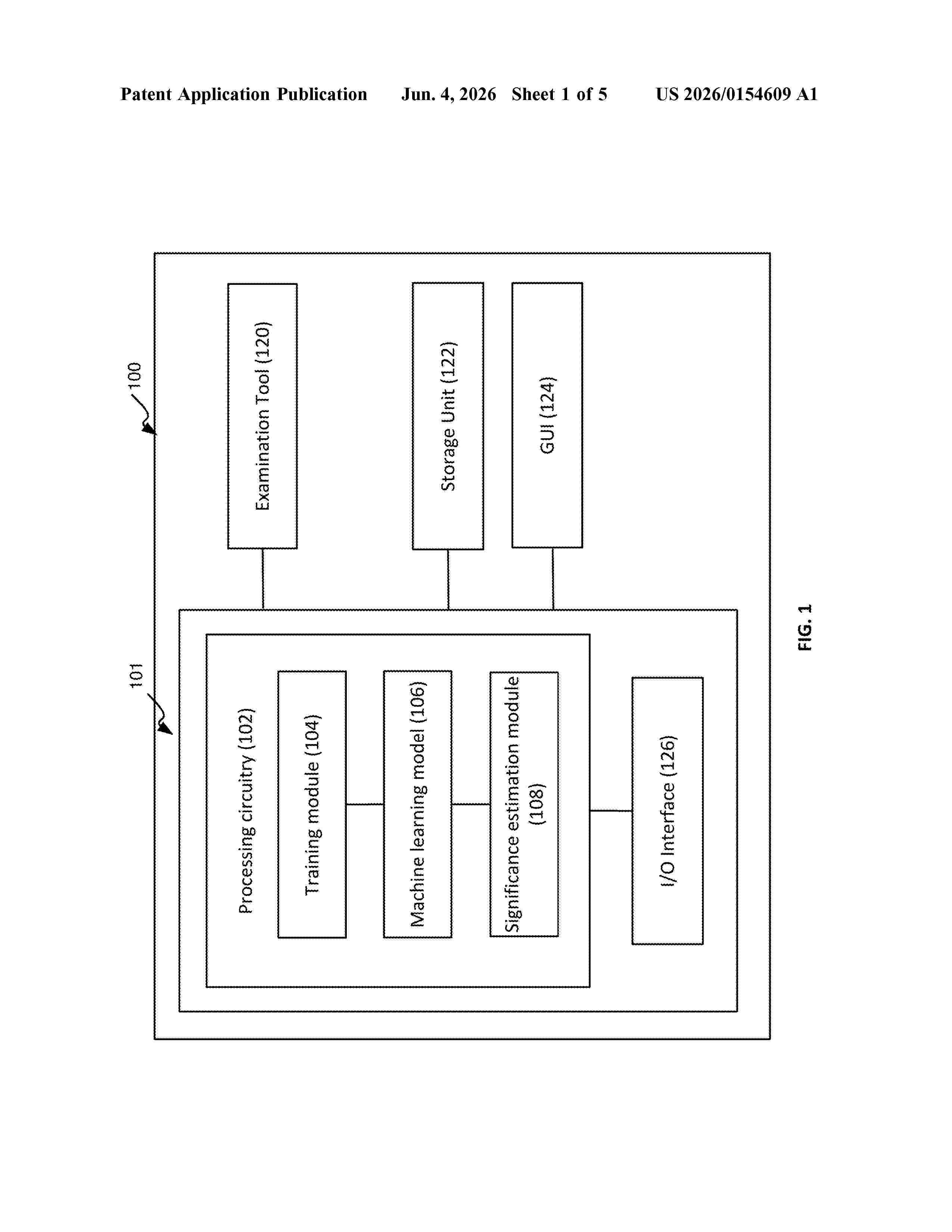
Resumen de: US20260154609A1
0000 There is provided a system and method of attribute selection. The method includes obtaining a first dataset comprising defect candidates, each characterized by a set of attributes and associated with a ground truth label thereof; training a machine learning (ML) model using the first dataset, and estimating, for each attribute, a first significance value based on the trained ML model; generating one or more second datasets based on the first dataset, each second dataset comprising the defect candidates each associated with a synthetic label; retraining the ML model respectively using the one or more second datasets, and estimating, for each attribute, one or more second significance values based on one or more respectively retrained ML models; calculating a normalized significance value for each attribute based on the first significance value and the second significance values; and selecting a subset of attributes based on their normalized significance values.
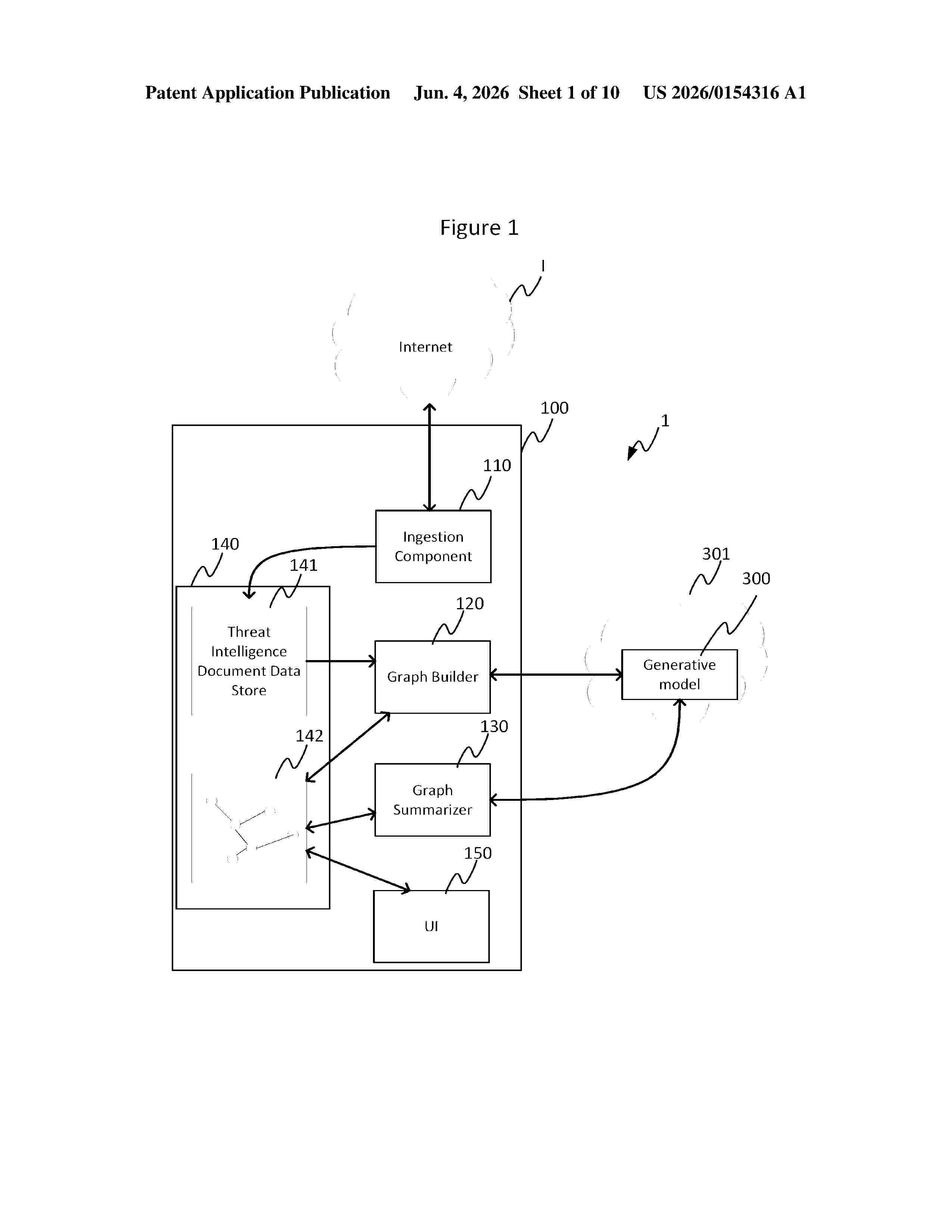
Resumen de: US20260154316A1
A computer-implemented method includes storing threat intelligence documents and a graph data store. The graph data store includes entity nodes and a plurality of edges between the nodes extracted from the plurality of threat intelligence documents. Data is also stored linking the entity nodes and edges to the threat intelligence documents from which they were extracted. A generative machine learning model is employed to generate a summary text of threat intelligence for a first entity node, based on the first entity node, second entity nodes connected to the first entity node and the threat intelligence documents from which they were extracted. The summary text is inserted as a summary node into the graph comprising the generated summary text.
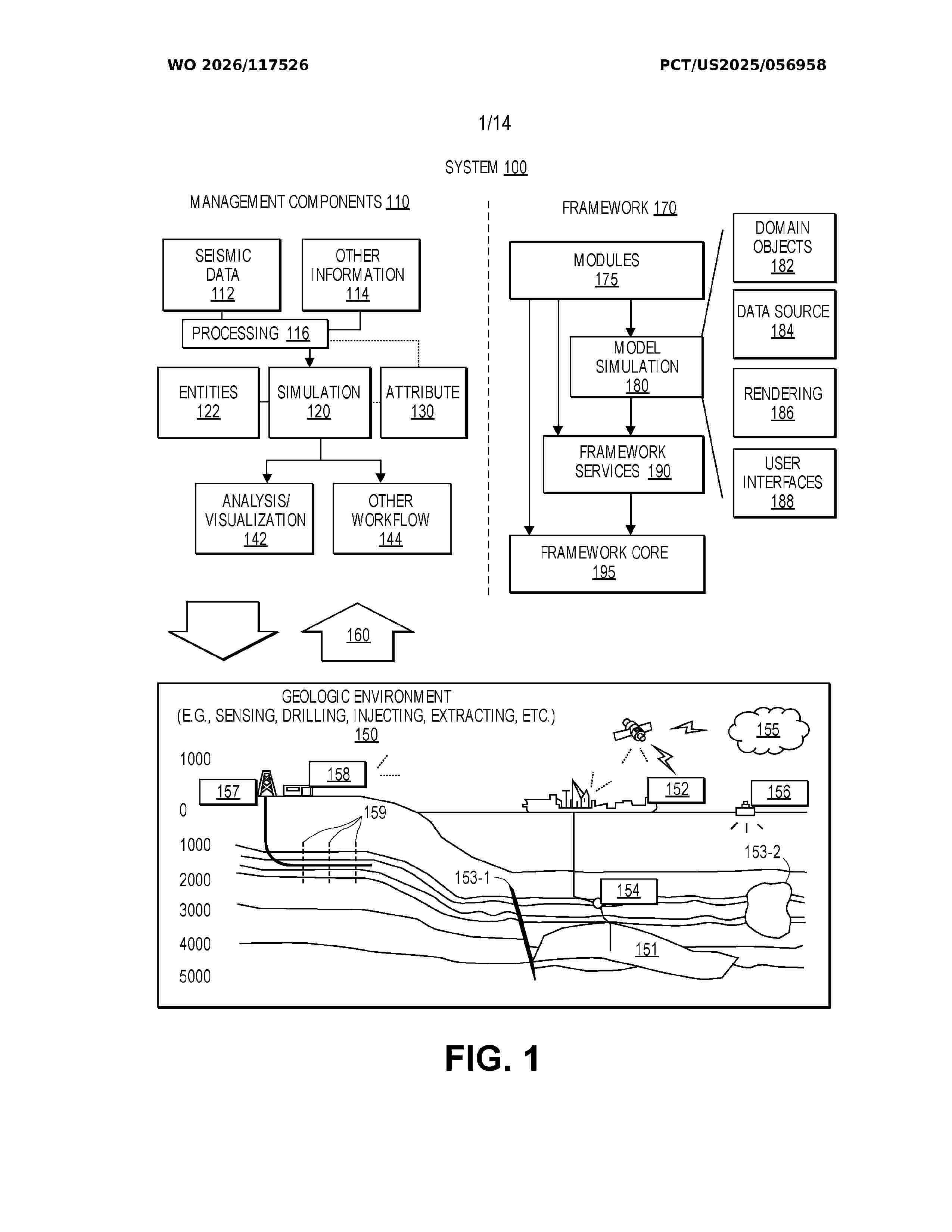
Resumen de: WO2026117526A1
A method for generating a closed layer model of a subsurface includes receiving input data including a 3D seismic volume having a plurality of horizons. The method also includes identifying labeled areas of the plurality of horizons based to produce identified labeled areas for the plurality of horizons. The method further includes determining lateral extents of the identified labeled areas based on the input data, and sorting the plurality of horizons based on the lateral extents to produce a plurality of sorted horizons. The method also includes identifying boundary points of the plurality of horizons based on the lateral extents, and creating truncation maps for the plurality of horizons based on the boundary points of the plurality of sorted horizons. The method also includes generating the closed layer model based on the plurality of horizons and the truncation maps thereof.
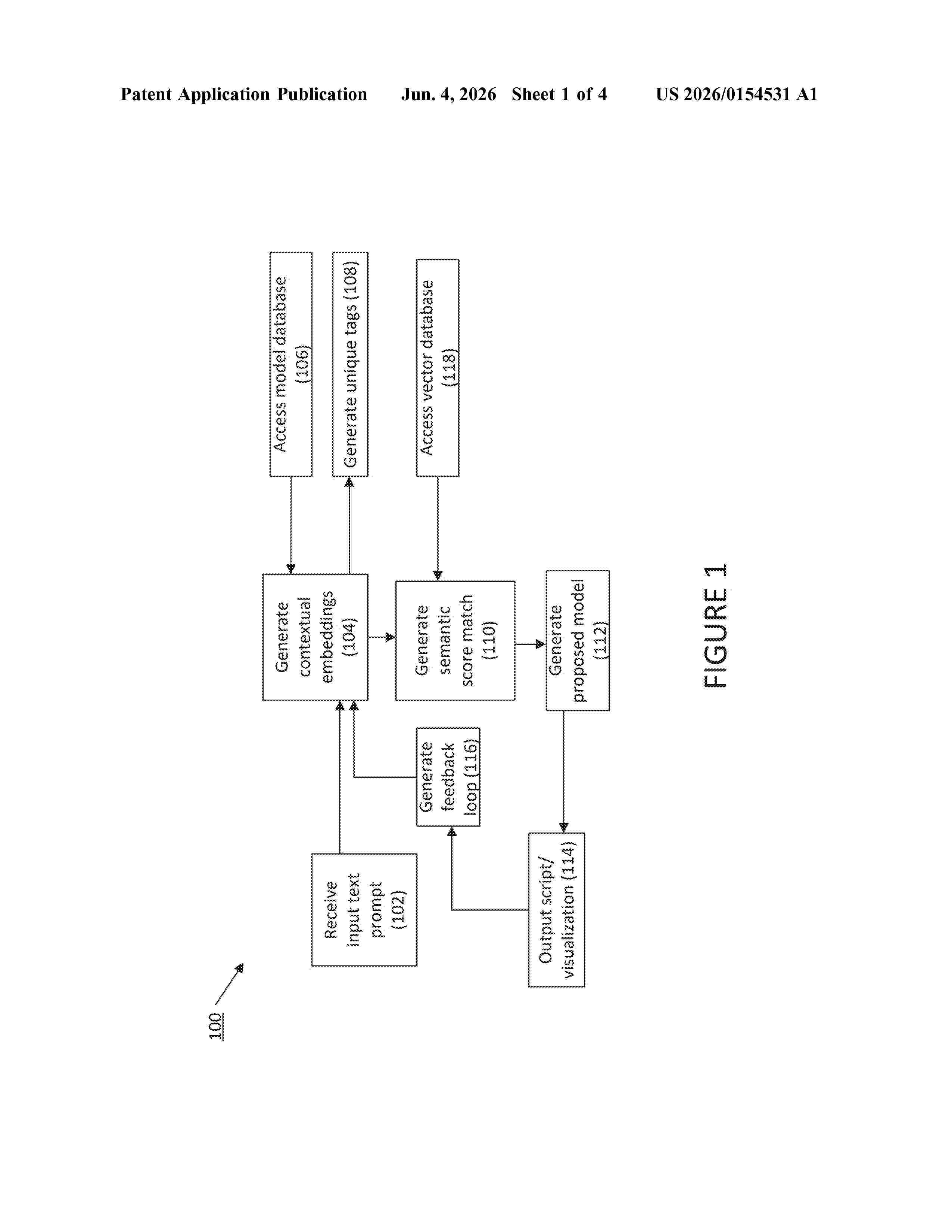
Resumen de: US20260154531A1
In some aspects, the techniques described herein relate to a method including: receiving an input text prompt at a machine learning model, the input text prompt including a type of application and a data; mapping, by a text encoder, the input text prompt to a representation space; generating, by a small language model, contextual embeddings for the type of application and the data specified in the input text prompt, wherein a character of each word of the input text prompt encoded with a numerical value; storing, by a computer program, the contextual embeddings in a model repository; assigning, by the computer program, one or more unique tags to the contextual embeddings; generating, by the computer program, a semantic score match based on a data model; generating a visualization of the data model; and generating a script to be executed on a target system for the data model.
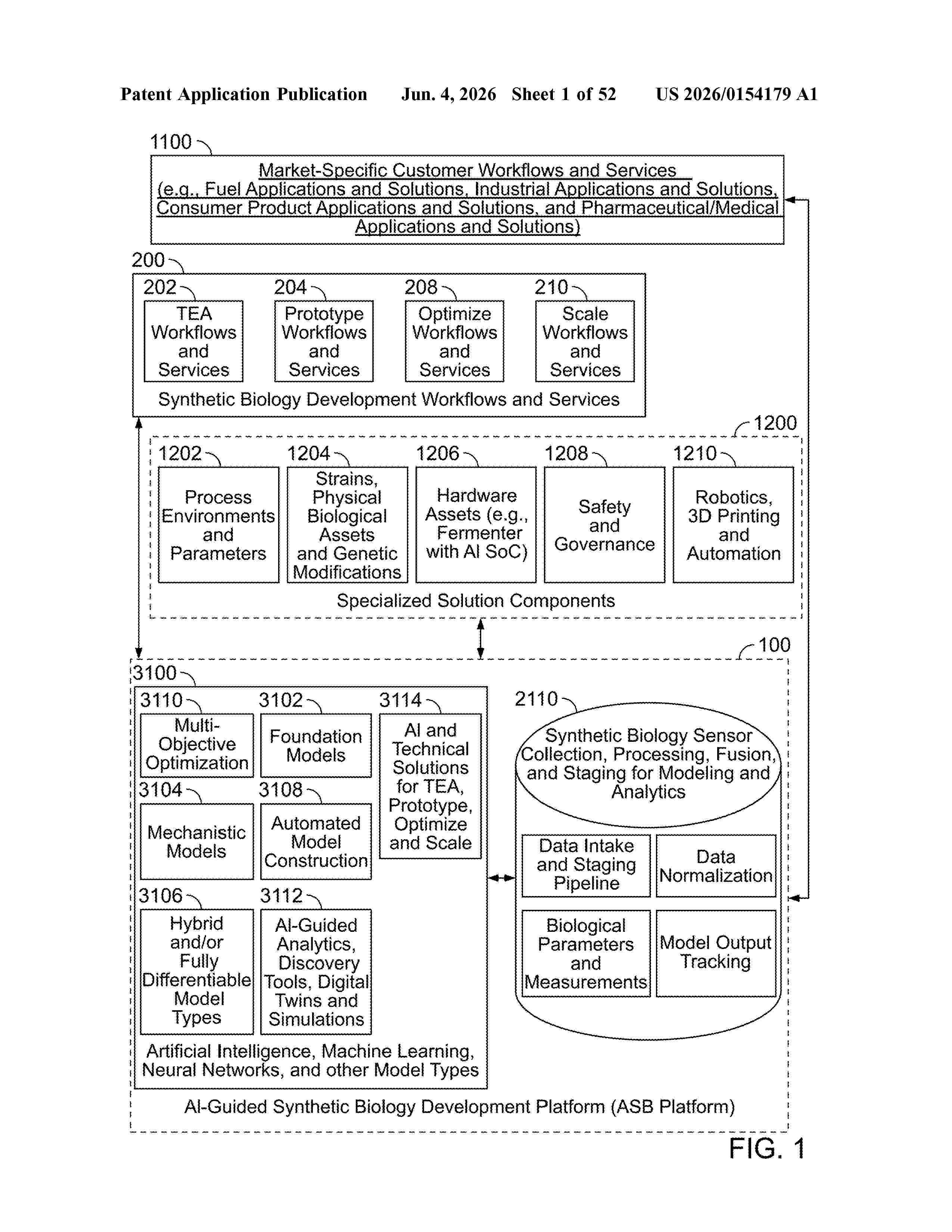
Resumen de: US20260154179A1
0000 A system may include one or more processors and memory storing instructions that, when executed by the one or more processors, cause a platform to: identify an appropriate analytic method based on an assessment of a data characteristic, implement a data preparation procedure specific to a particular application, apply a machine learning model to analyze data and generate a prediction, perform a model validation procedure to ensure analytical reliability, create an audit trail documenting an analytic procedure and result; and generate technical documentation and visualization of an analytic finding.
Resumen de: US20260154623A1
0000 Method and apparatus for training multimodal large model and method and apparatus for image question answering are disclosed, which relates to artificial intelligence technologies such as large models, deep learning, natural language processing, and computer vision. The method for training multimodal large model includes: obtaining an initial sample image, a sample object in the initial sample image, and a location information of the sample object; obtaining a target sample image including a sample visual marker based on the initial sample image and a target image region corresponding to the initial sample image; obtaining a sample question corresponding to the target sample image based on the sample visual marker, and obtaining a sample answer corresponding to the sample question; training an initial multimodal large model based on a target training sample constituted by the target sample image, the sample question and the sample answer to obtain a target multimodal large model. The method for image question answering includes: obtaining a target image including a target visual marker and a target question; inputting the target image and the target question into the target multimodal large model to obtain a target answer. The present disclosure enables the target multimodal large model to effectively understand the target visual marker in the target image, thereby improving the accuracy of the target answer.
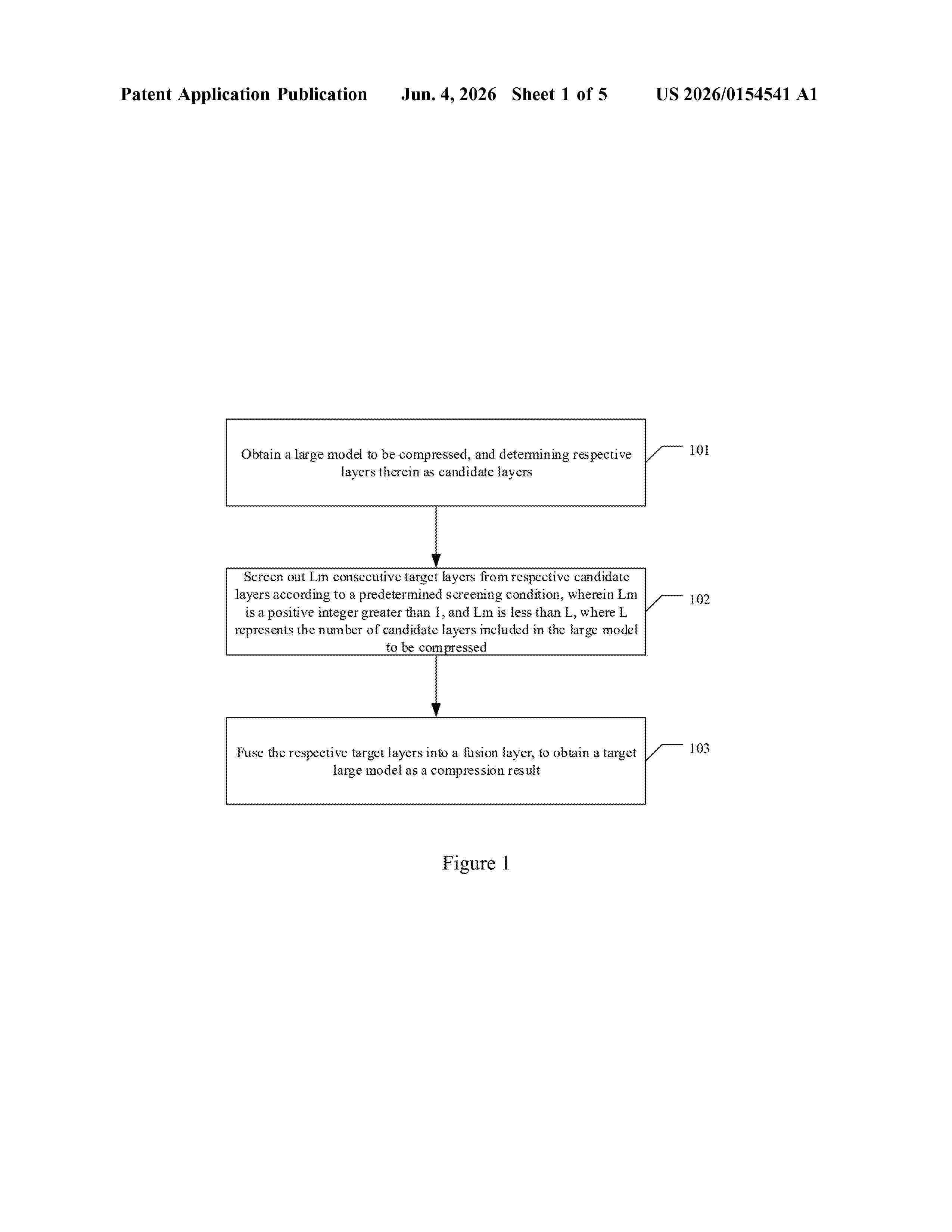
Resumen de: US20260154541A1
0000 Method and apparatus for text processing based on large model, and method and apparatus for large model compression are disclosed, which relate to the technical field of artificial intelligence field such as deep learning, large model, and natural language processing. The method for text processing based on large model includes: obtaining a token sequence corresponding to an input text; performing the following processing respectively for respective tokens in the token sequence: in response to determining that a fusion layer in a target large model needs to be used to process a token, generating a target processing result corresponding to the token by executing inference computation in the fusion layer at least twice, wherein the target large model is obtained by performing a model compression on a large model to be compressed, the model compression includes fusing Lm consecutive layers in the large model to be compressed into the fusion layer, Lm is a positive integer greater than 1, and Lm is less than L, where L represents the number of layers included in the large model to be compressed.
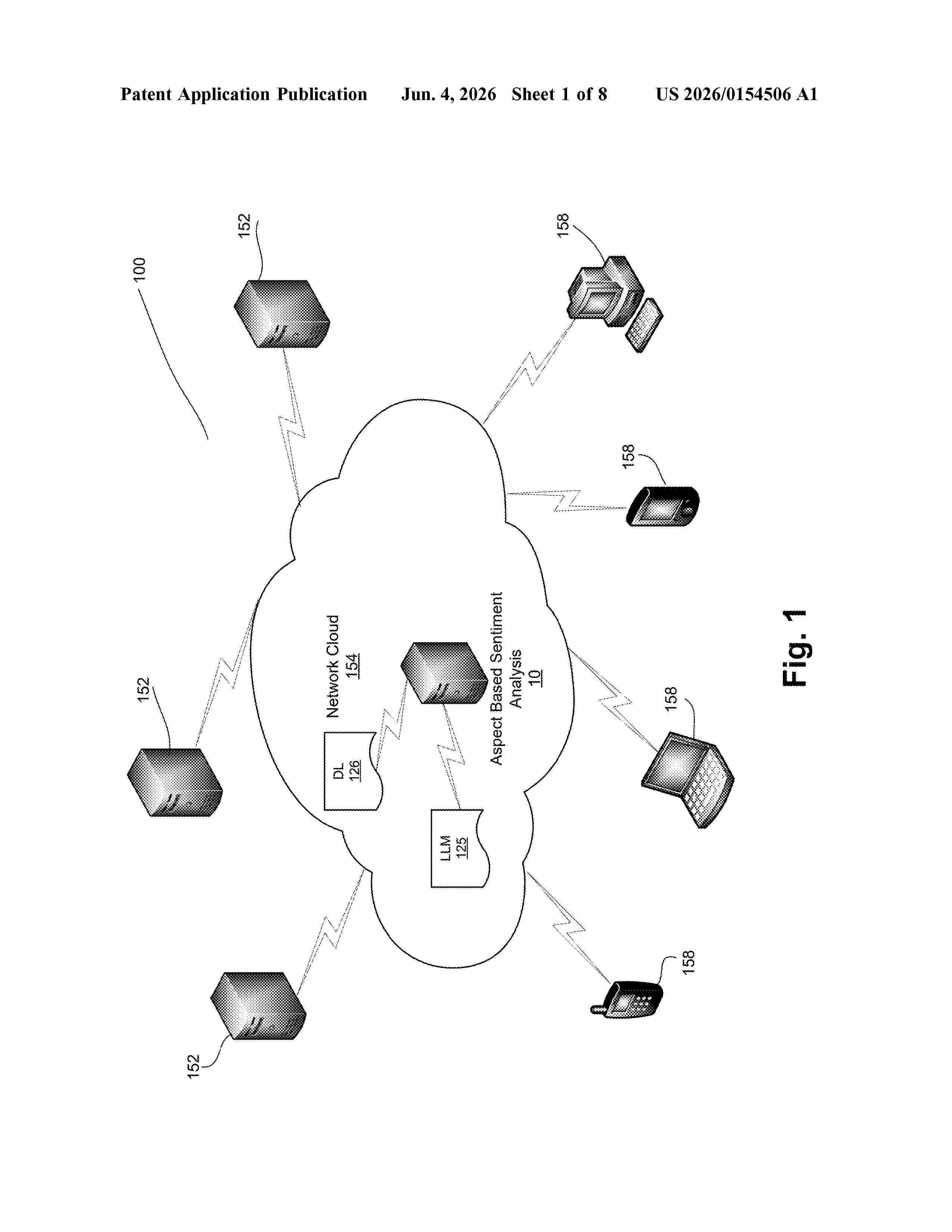
Resumen de: US20260154506A1
0000 Embodiments evaluate performance by receiving a plurality of training performance reviews. Embodiments extract from the training performance reviews, using a first machine learning model, a plurality of features comprising a training aspect, a training sentiment, and a corresponding training evidence. Embodiments use the extracted plurality of features to train a second machine learning model. Embodiments receive a first performance review and extract from the first performance review one or more first aspects, one or more corresponding first evidences, and one or more corresponding first sentiments. Embodiments, using the trained second machine learning model, predict first sentiment scores for each of the first aspects.
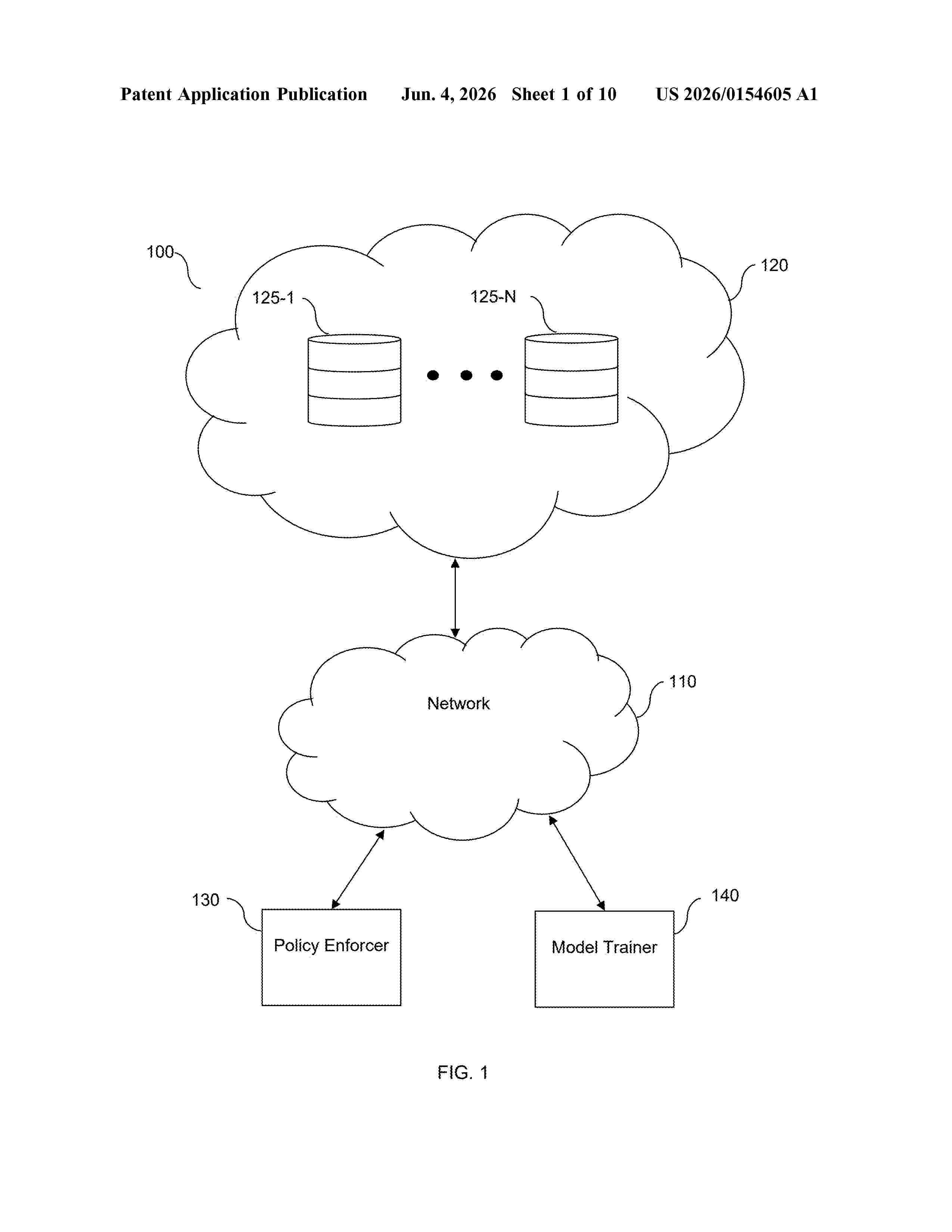
Resumen de: US20260154605A1
0000 Techniques for training and using machine learning models for sensitivity detection. A method for sensitivity detection training includes fine-tuning a language model by iteratively applying the language model to prompts and adjusting weights of the language model. The prompts indicate classifications for a set of first resources and characteristics of an entity. The fine-tuned language model is queried with respect to classifications of a set of second resources. The fine-tuned language model is queried using prompts indicating the second classifications and data indicating characteristics of an entity, where outputs of the language model include a sensitivity for each of the second classifications. Training data including the second classifications is labeled based on the sensitivities output by the language model. A sensitivity detection machine learning model is trained using the labeled training data set such that the trained sensitivity detection machine learning model is configured to output sensitivities for resource classifications.
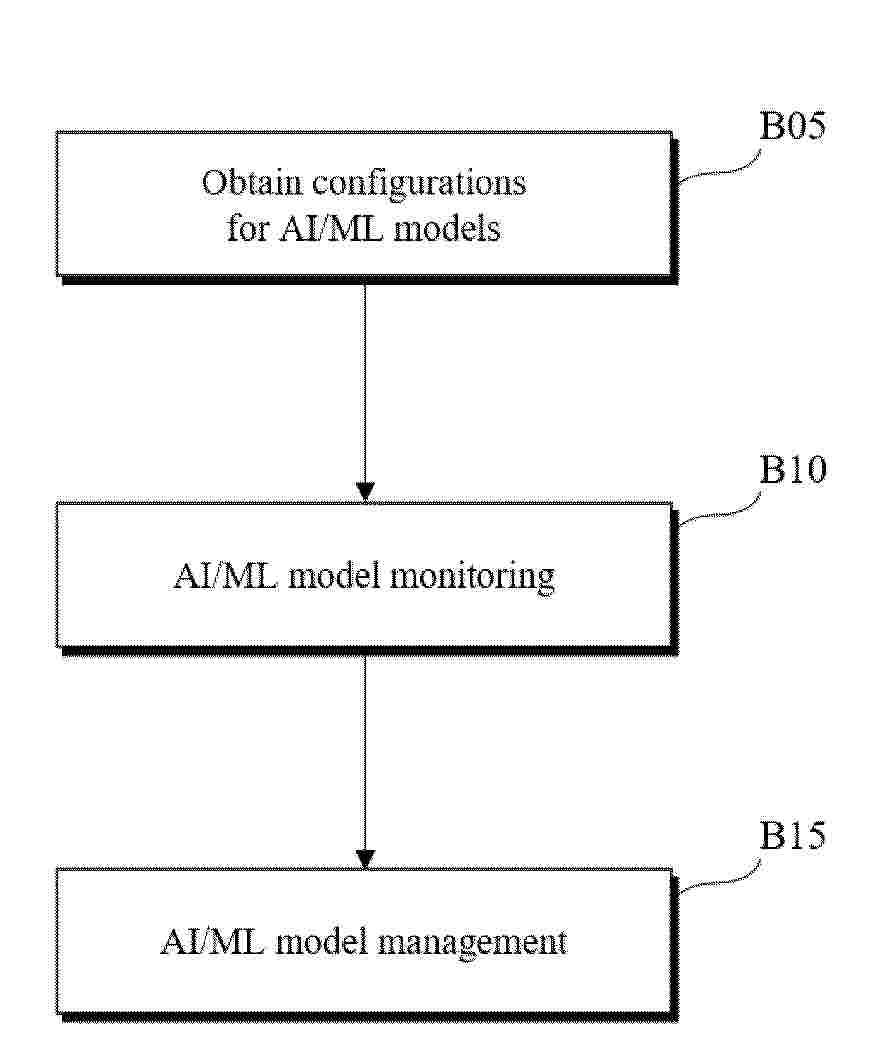
Resumen de: EP4753225A1
: A method performed by a terminal in a wireless communication system according to at least one of the embodiments disclosed in the present specification may comprise the steps of: acquiring configurations for artificial intelligence/machine learning (AI/ML) models on the basis of higher layer signaling; monitoring one or more of the AI/ML models; and, on the basis of the monitoring of the one or more AI/ML models, performing AI/ML model management for switching or updating. The monitoring of the one or more AI/ML models includes at least one of the monitoring of a first AI/ML model in an inactive state or the monitoring of a second AI/ML model in an active state. The monitoring of the first AI/ML model in the inactive state may occupy fewer terminal processing units or occupy the terminal processing units for a shorter period of time than the monitoring of the second AI/ML model in the active state.
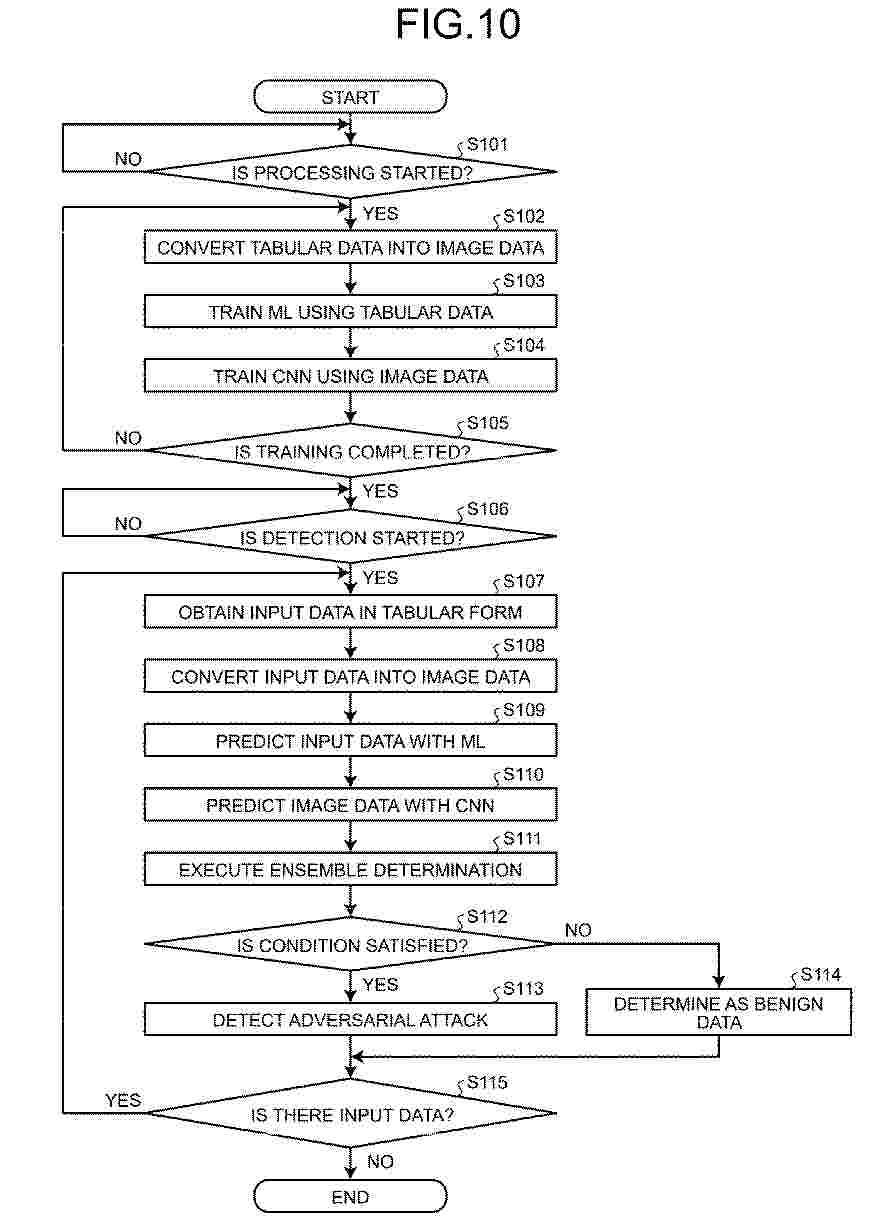
Resumen de: EP4752787A1
A detection program causes a computer to execute a process including converting input tabular data into image data, generating a first machine learning model by machine learning using the tabular data as training data, and generating a second machine learning model by machine learning using the image data as training data, and detecting presence of an adversarial attack on input data based on a first prediction result for the input data obtained using the first machine learning model and a second prediction result for the input data obtained using the second machine learning model.
Resumen de: US20260148114A1
0000 Various embodiments of the present invention address technical challenges associated with performing machine learning operations on timeseries/periodic data by introducing a machine learning framework that has a first periodic tier for determining predicted evaluation scores for those predictive entities that are associated with a single evaluation period (e.g., a single year of data) and a second periodic tier for determining predicted evaluation scores for those predictive entities that are associated with multiple evaluation periods. The noted framework addresses the existing shortcomings of machine learning frameworks that operate on timeseries/periodic data with respect to inadequacy of data associated with shorter periods to determine parameters needed to perform comprehensive predictive data analysis with respect to longer periods.
Resumen de: US20260148271A1
0000 A computing system may normalize messages by parsing, extracting attachments, masking data, and storing queued records. A non-transitory computer-readable medium may store instructions that normalize messages by parsing, masking, and queueing. A computer-implemented method may normalize messages by parsing content, extracting records, rewriting links, and masking data.
Nº publicación: WO2026107601A1 28/05/2026
Solicitante:
NEXADEEDS INC [CA]
NEXADEEDS INC.
Resumen de: WO2026107601A1
There is described herein systems and methods for modifying parameters of a deep learning algorithm to improve its carbon footprint and/or water footprint and novel methods of extracting features from code and datasets relating to the deep learning algorithm. The systems and methods described estimate the carbon footprint and/or water footprint and efficiency and performance of executing the deep learning algorithm by using surrogate machine learning models. Using the estimates, the system and methods determine at least one recommendation to modify one or more parameters of the deep learning algorithm to reduce the carbon footprint and/or water footprint of the deep leaning algorithm while increasing or maintaining the efficiency and performance of the deep learning algorithm. The system provides pre-execution estimation of environmental footprint and performance, enabling environmentally informed optimization not available in existing tools.
 BOPI
BOPI
 Sede Electrónica
Sede Electrónica