Si deseas distinguir tus productos, servicios o ambos de los de otra empresa, es posible que necesites una marca o nombre comercial. Descubre qué son, en qué consiste su procedimiento de registro y qué implica.

Información sobre los plazos de presentación de solicitudes de transformación de marcas de la Unión Europea en marca nacional española. Más información


Si tienes un nuevo dispositivo, producto o procedimiento que resuelva un problema técnico o tenga una ventaja práctica, existen distintas formas de protegerlo en España y en otros países. Descubre cómo hacerlo.

¿Tu innovación reside en la estética, la ornamentación o la apariencia de tu producto? Protégela mediante un diseño industrial. Descubre qué derechos confiere el registro y cómo realizar la tramitación.

Las indicaciones geográficas protegen el nombre de un producto originario de una zona geográfica, a la cual le debe una determinada calidad, reputación u otra característica. Descubre qué son, en qué consiste su procedimiento de registro y qué beneficios conceden.

Las patentes publicadas en todo el mundo son una valiosa fuente de información científica, técnica y comercial.

Si eres emprendedor/a o una empresa y quieres potenciar y mejorar la rentabilidad de tu negocio protegiendo de forma adecuada los activos intangibles de tu organización, en este espacio encontrarás lo necesario.



 104
resultados
104
resultados
 Última actualización
27/06/2026 [07:03:00]
Última actualización
27/06/2026 [07:03:00]


 Resultados 75 a 100 de 104
Resultados 75 a 100 de 104

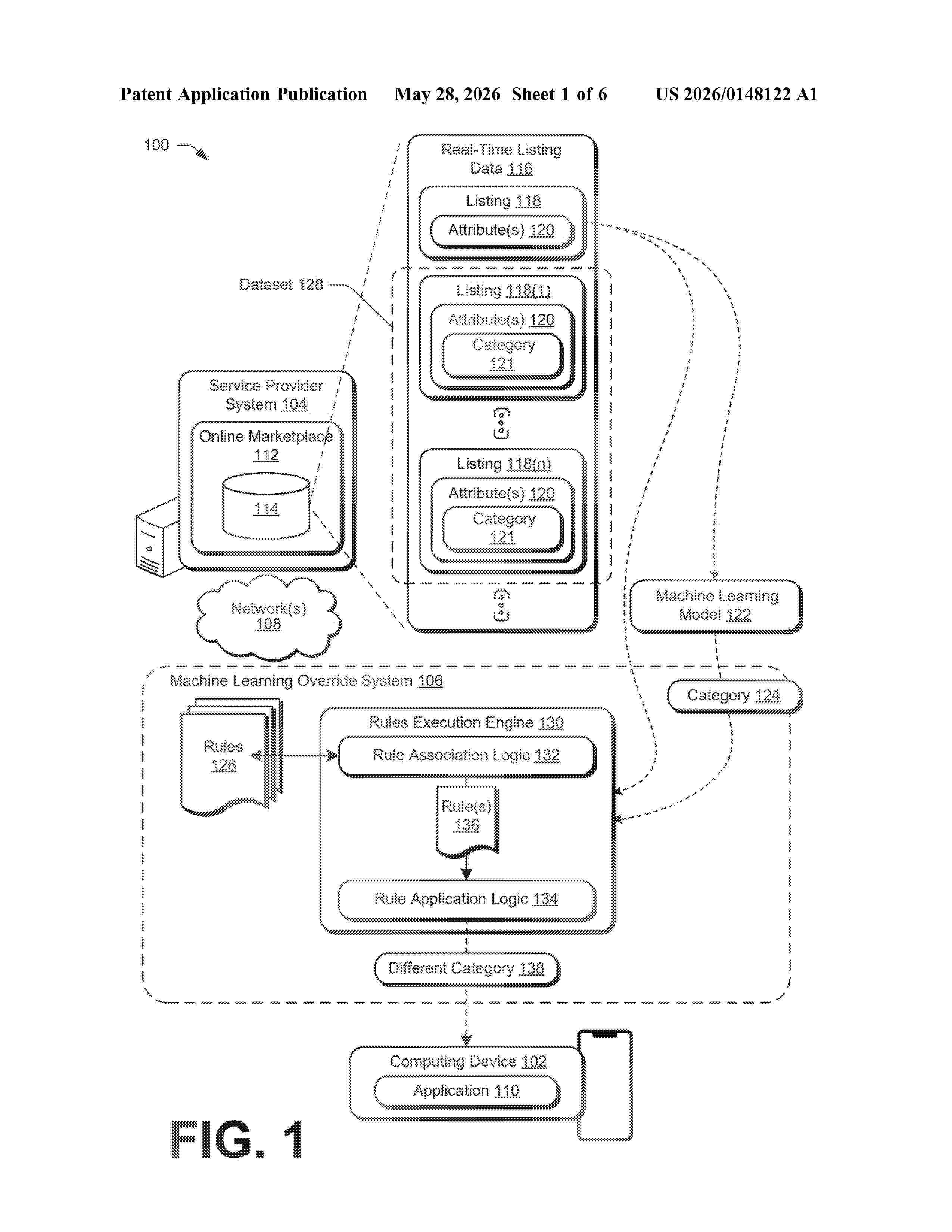
Resumen de: US20260148122A1
0000 Rules based override of machine learning output is described. In one or more implementations, the described architecture receives a listing for an item having one or more attributes describing the item. A category of the item, as output by a machine learning model based on the listing, is also received. The machine learning model is trained using a dataset of listings labeled with item categories. A set of deterministic rules is executed on the one or more attributes describing the item and the output of the machine learning model, including identifying the category of the item and applying one or more of the deterministic rules associated with the category. Based on the executing, a different category of the item is output and overrides the category of the item as output by the machine learning model.

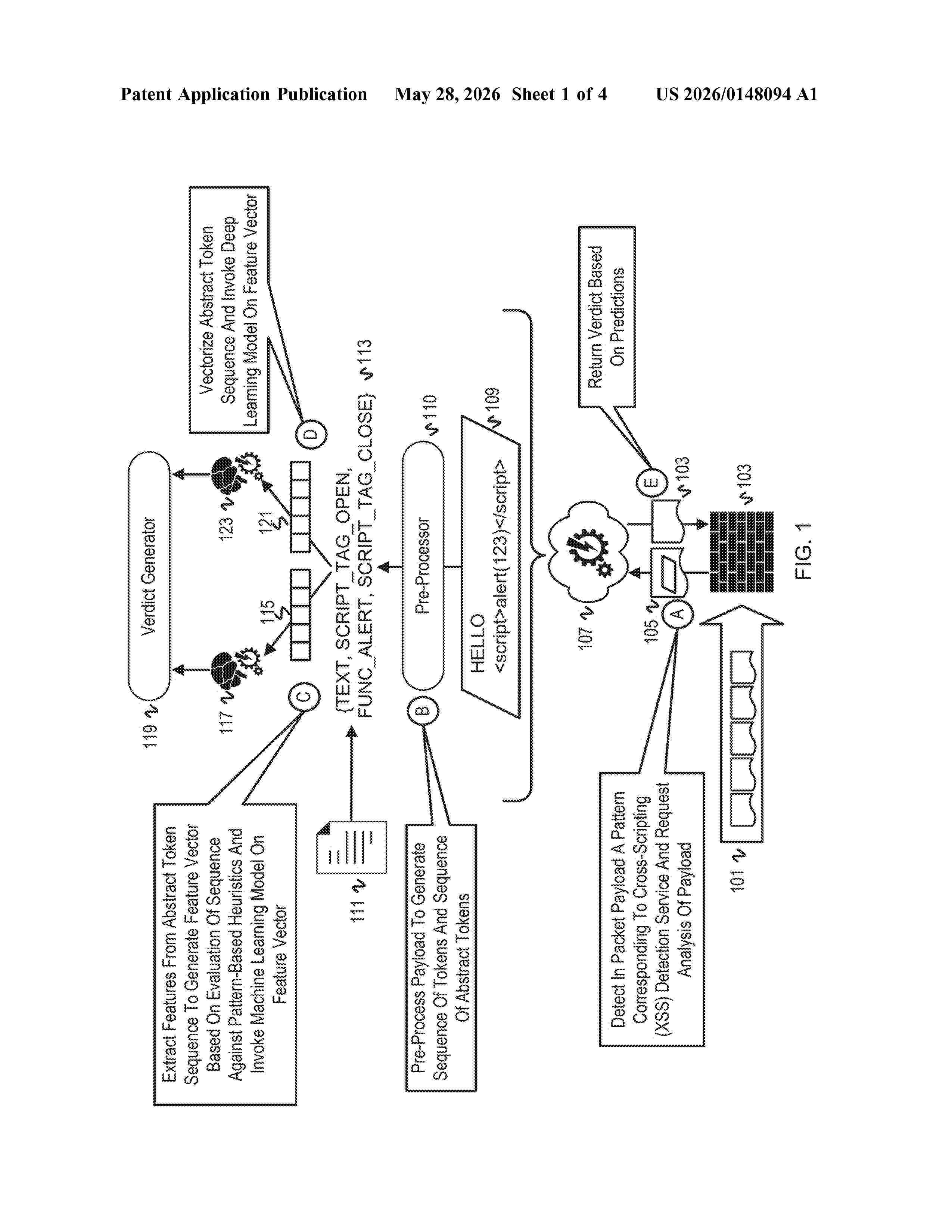
Resumen de: US20260148094A1
An artificial intelligence ensemble has been developed for XSS detection with high accuracy. The artificial intelligence ensemble is created with a deep learning model and a machine learning model, each trained on different perspectives of token sequences extracted from packet payloads. Pre-processing of the raw data (i.e., the packet payload) generates a sequence of tokens that represents the payload and then generates a sequence of abstract tokens from the sequence of tokens. The deep learning model is trained on abstract token sequences to detect XSS from the perspective of patterns of token sequences. The other model is trained on pattern-based features extracted from the sequence of tokens to detect XSS from the perspective of features corresponding to characteristics of tokens sequences corresponding to heuristics gleaned for XSS. After each model is trained, the models are combined and deployed for inline detection of XSS in payload traffic from the different perspectives.
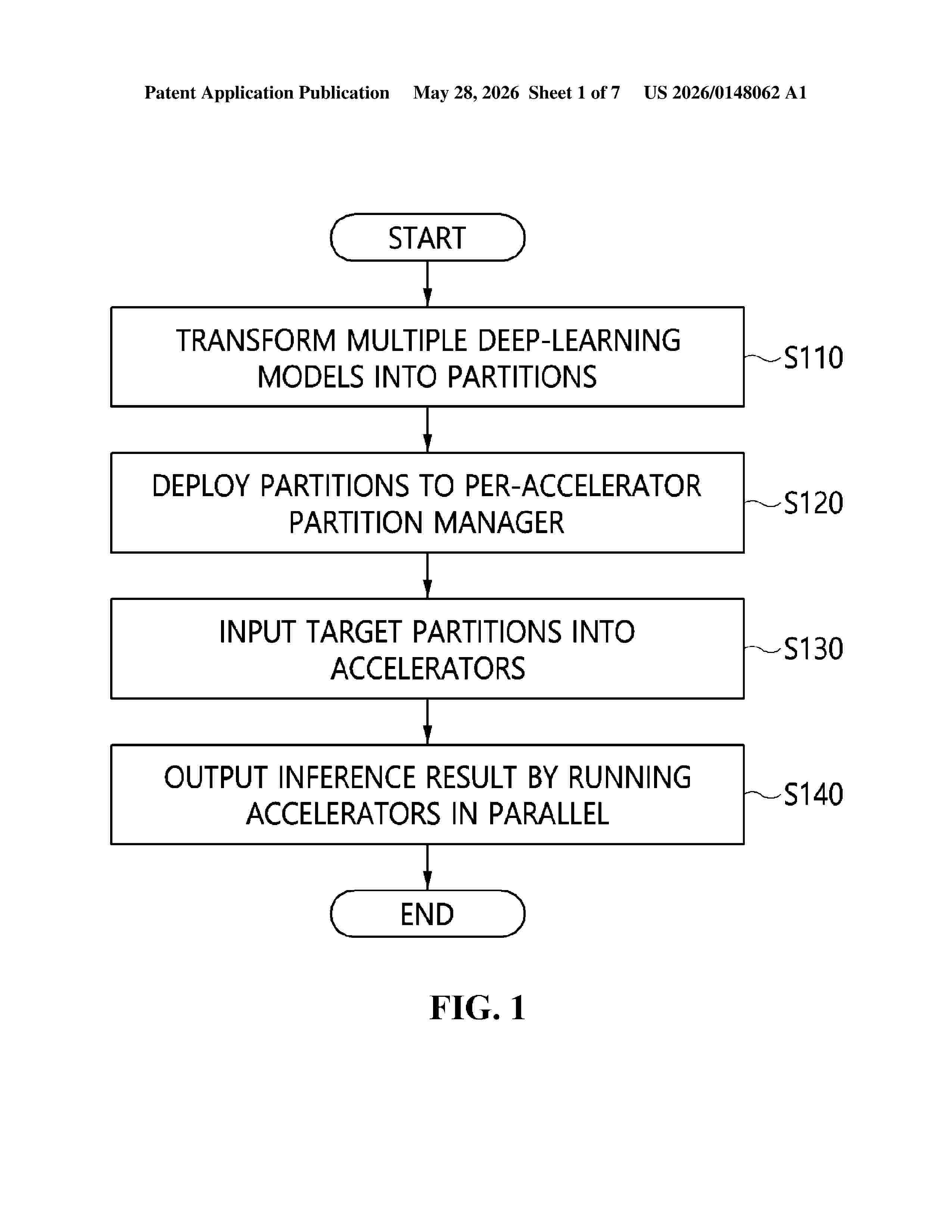
Resumen de: US20260148062A1
0000 Disclosed herein are a method for parallel inference for multiple deep-learning models and an apparatus for the same. The method performed by the apparatus includes transforming each of multiple deep-learning models into partitions executable on accelerators by partitioning the deep-learning model, deploying the partitions to per-accelerator partition managers based on a partition execution order determined in consideration of inter-partition dependencies, extracting target partitions associated with input data for each target model from the per-accelerator partition managers and inputting the target partitions into accelerators matched with the target partitions when the input data for each target model is provided according to an inference execution request, and outputting an inference result for each target model by running the accelerators, into which the target partitions are input, in parallel.
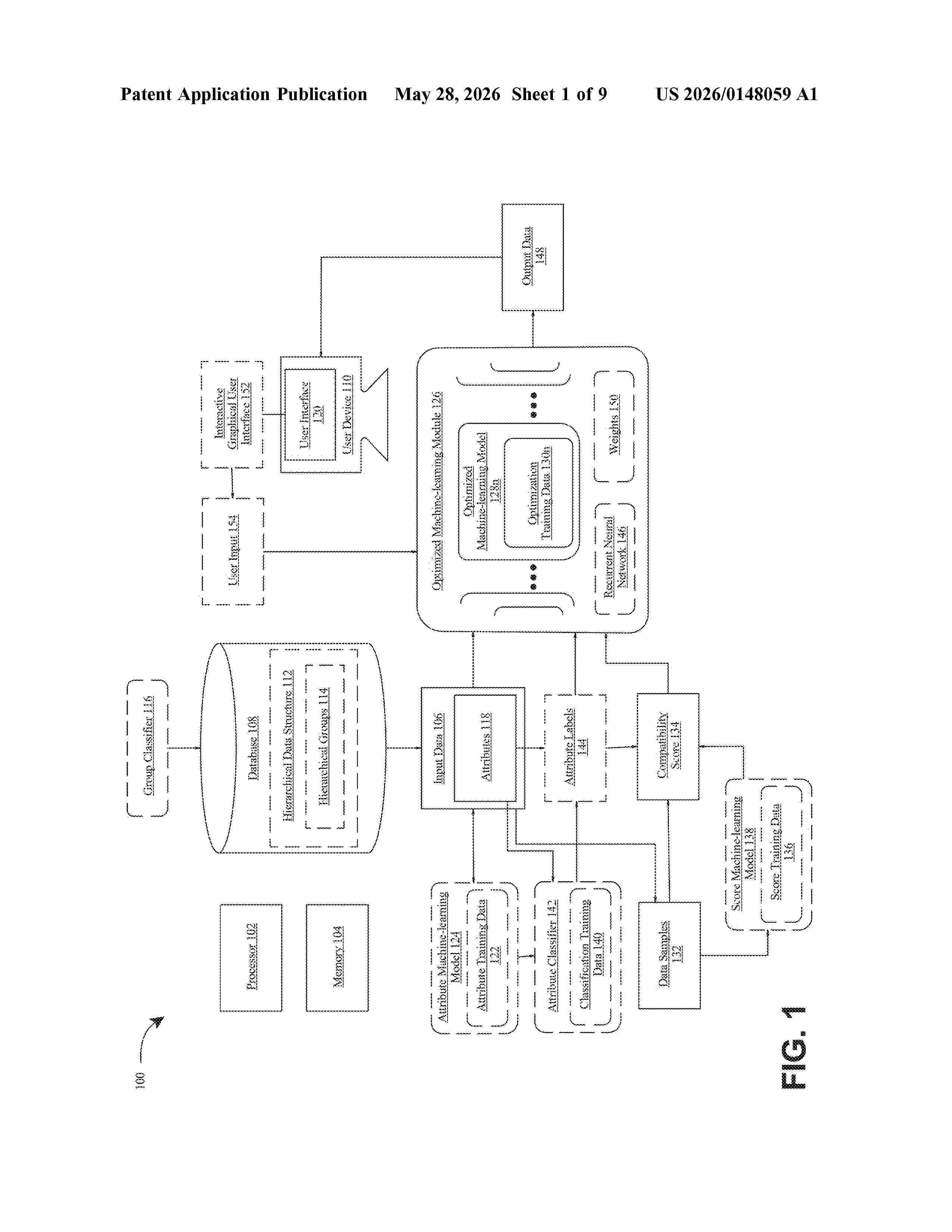
Resumen de: US20260148059A1
0000 An apparatus and method for machine-learning model optimization for data attributes are disclosed. The apparatus includes at least a processor and a memory communicatively connected to the at least a processor, wherein the memory contains instructions configuring the at least a processor to receive input data, extract a plurality of attributes from the input data, generate an optimized machine-learning module including a plurality of optimized machine-learning models, select at least one optimized machine-learning model from a plurality of trained optimized machine-learning models as a function of the plurality of attributes and generate output data as a function of the input data and the plurality of attributes using the selected optimized machine-learning model.
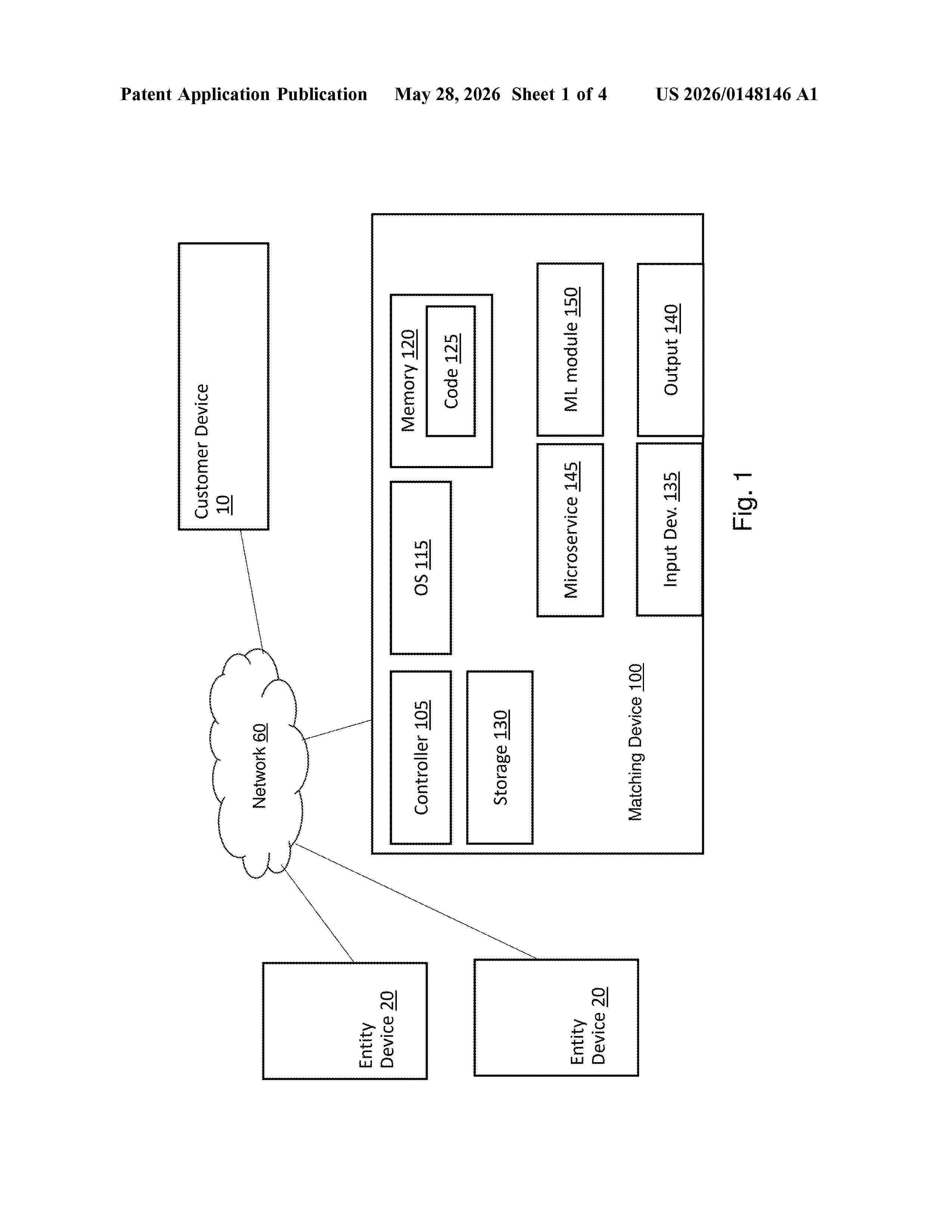
Resumen de: US20260148146A1
0000 A system and method may identify the best matching entities using artificial intelligence, by for example determining, from a set of features describing a number of entities, a subset of features which when input to a machine learning module allow the machine learning module to match a pair of entities based on the ability of the second entity in the pair to successfully take over responsibilities handled by the first entity in the pair; training a machine learning module using the determined features; and for a first entity described by the determined set of features, using the machine learning module to determine a list of entities matching the first entity, each entity in the list of entities associated with a matching score.
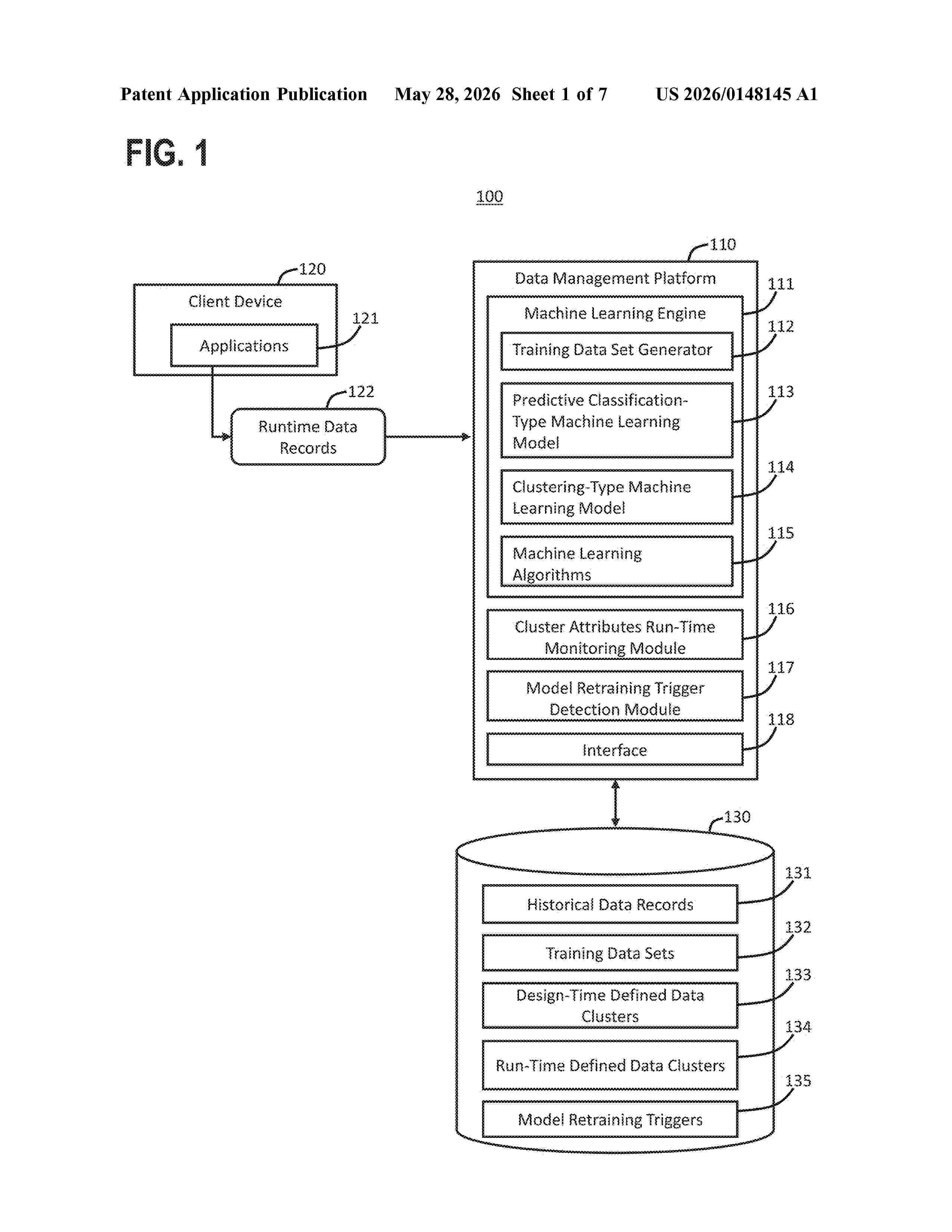
Resumen de: US20260148145A1
0000 Techniques for dynamically generating and updating clusters for categorizing data by using a hybrid implementation of supervised and unsupervised machine learning models are disclosed. A system trains a supervised prediction-type machine learning model to categorize data into a design-time defined set of data clusters. The system trains the prediction-type model using a training data set to generate predictions for assigning data to design-time defined data clusters. If the prediction-type model predicts that a data record does not correspond to any of the design-time defined data clusters, the system applies an unsupervised clustering-type machine learning model to the data record. The clustering-type model predicts a data cluster for the record. If the system detects a retraining trigger, the system retrains the classification-type model to include a new classification based on a runtime defined data cluster generated by the clustering-type model.
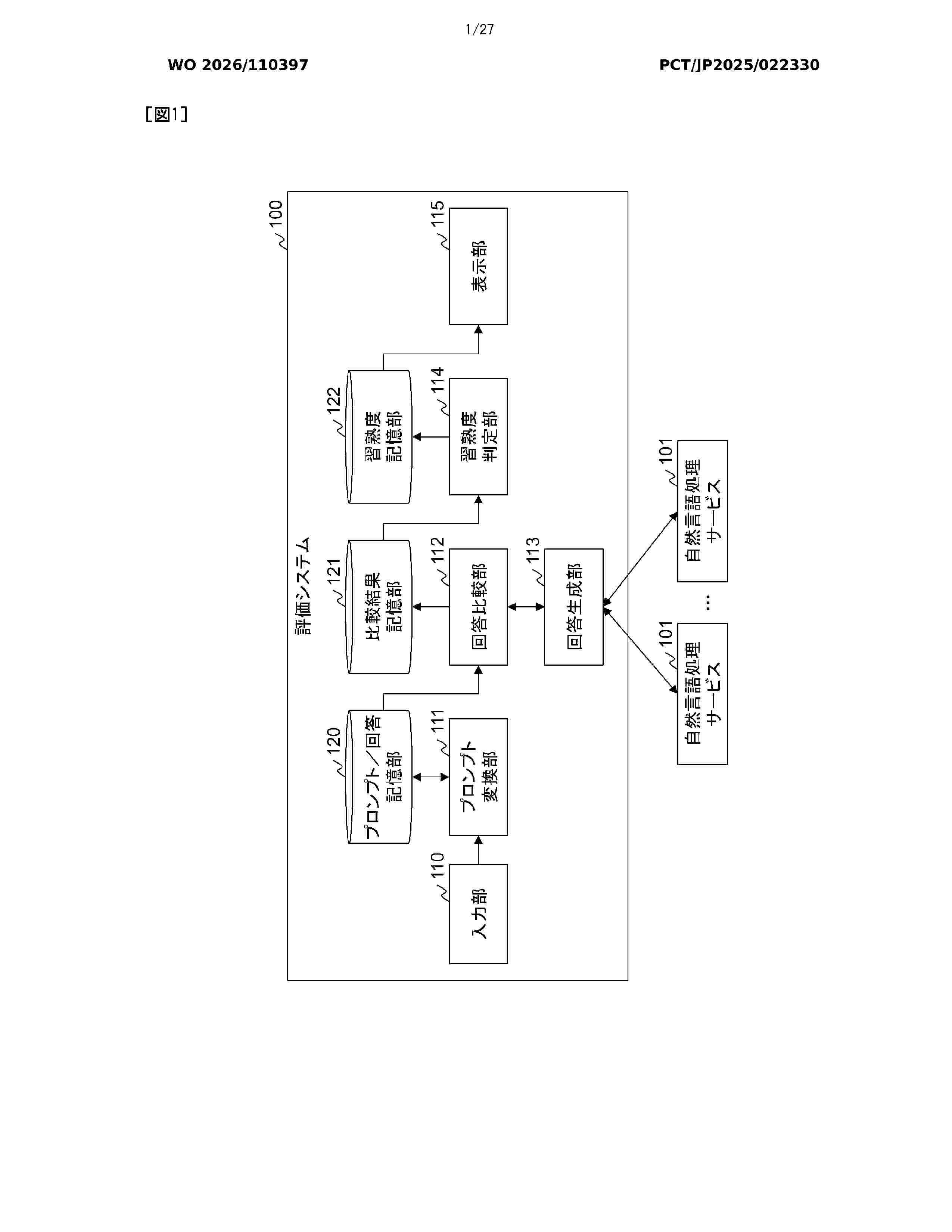
Resumen de: WO2026110397A1
This computer system is communicably connected to a machine learning model, receives an evaluation instruction including information designating a use case of the machine learning model, an input prompt, and an expected answer, generates a plurality of conversion prompts by changing an expression pattern of the input prompt, inputs the input prompt and each of the plurality of conversion prompts to the machine learning model to acquire a plurality of generated answers, compares the expected answer and the generated answer for each of the plurality of generated answers, calculates a similarity score indicating a similarity between the expected answer and the generated answer, and executes statistical processing using the similarity score of the plurality of generated answers, to thereby calculate an index for evaluating the answer accuracy of the machine learning model in the use case.
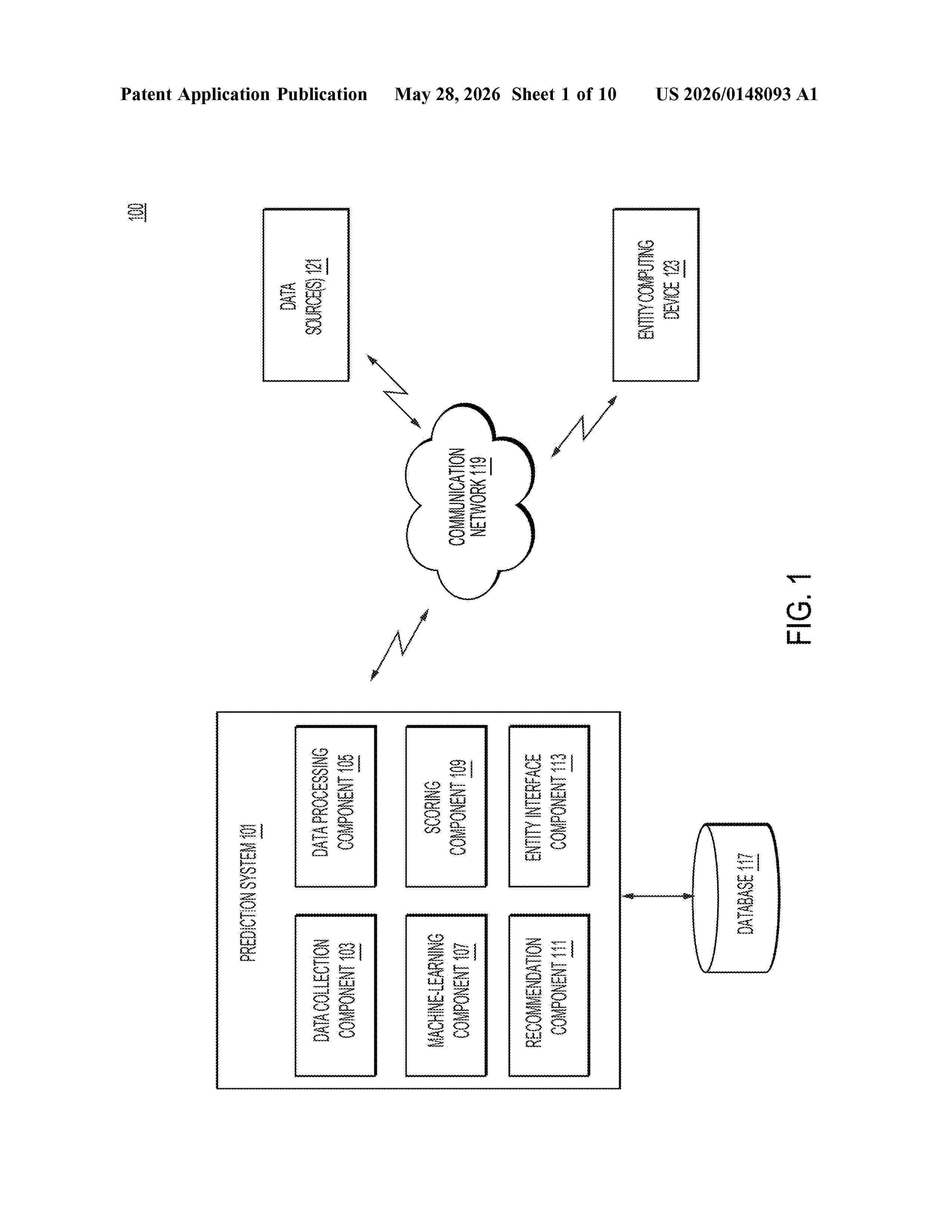
Resumen de: US20260148093A1
0000 Systems and methods are disclosed for processing multidimensional data using machine-learning models to classify an entity, predict metrics, and/or generate transcripts. The method includes receiving multi-dimensional data that include a first value of a first dimension indicating a comparison of an entity with a group of entities, and a second value of a second dimension indicating an attribute of the entity irrespective of the group of entities; inputting the multi-dimensional data to a first machine-learning model to output a prediction value determined based on applying first and second weights to the first and second values, respectively; and upon determining the prediction value satisfies first threshold associated with an adverse event: filtering historical text data associated with the entity to exclude data that satisfies second threshold associated with acceptable operations; and generating, by inputting the filtered historical text data into a second machine-learning model, a transcript of recommended actions.
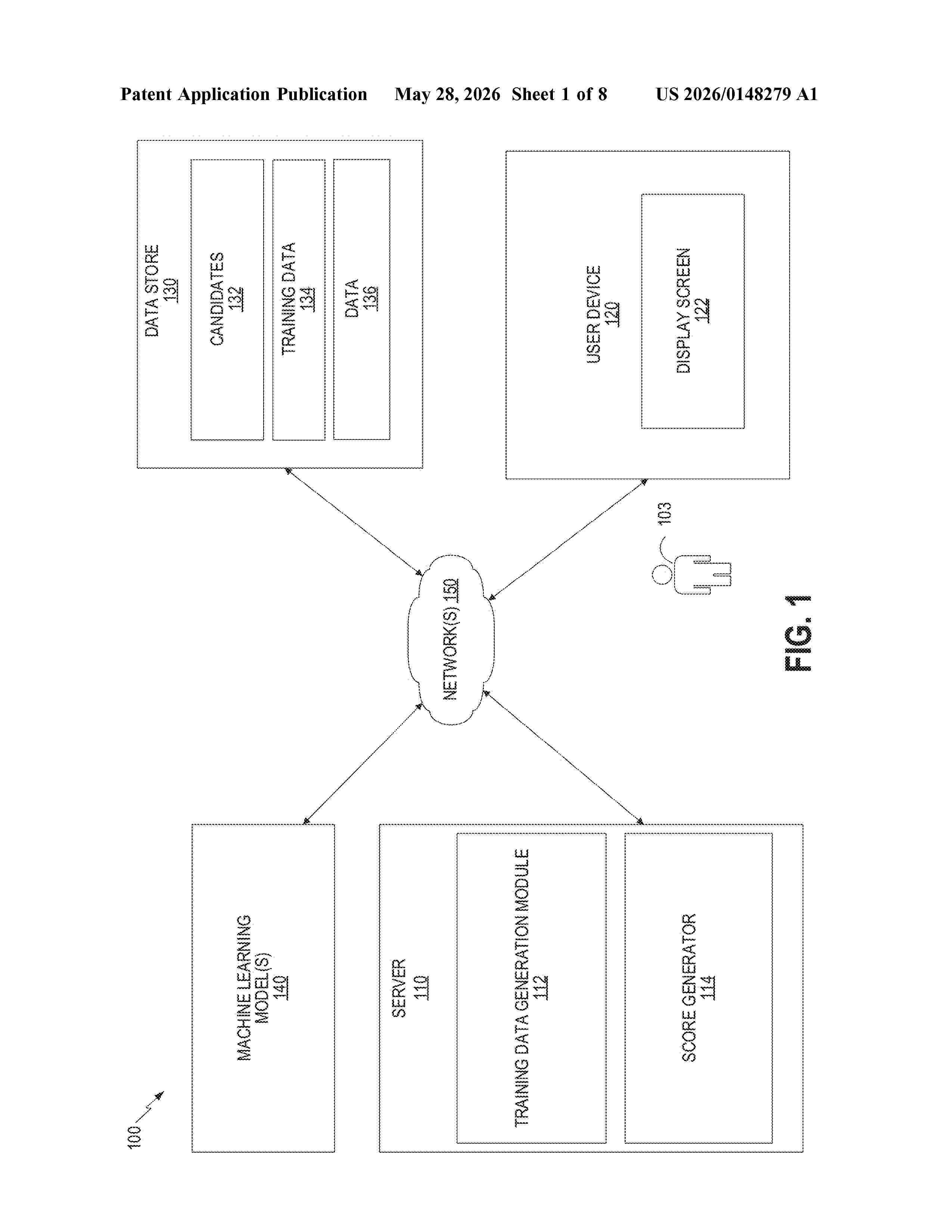
Resumen de: US20260148279A1
A method for training a machine learning model to automatically recommend substitute grocery products for a grocery product selected by a user is provided. The method includes generating a hierarchical structure defining a relationship between each of a plurality of different grocery products based, at least in part, on one or more of a plurality of different attributes associated with each of the grocery products. The method includes generating training data based on the hierarchical structure, the training data comprising, for each respective grocery product included in a subset of the plurality of different grocery products, a list of candidate substitute grocery products ranked from most substitutable to least substitutable. The method includes training the machine learning model using the training data.
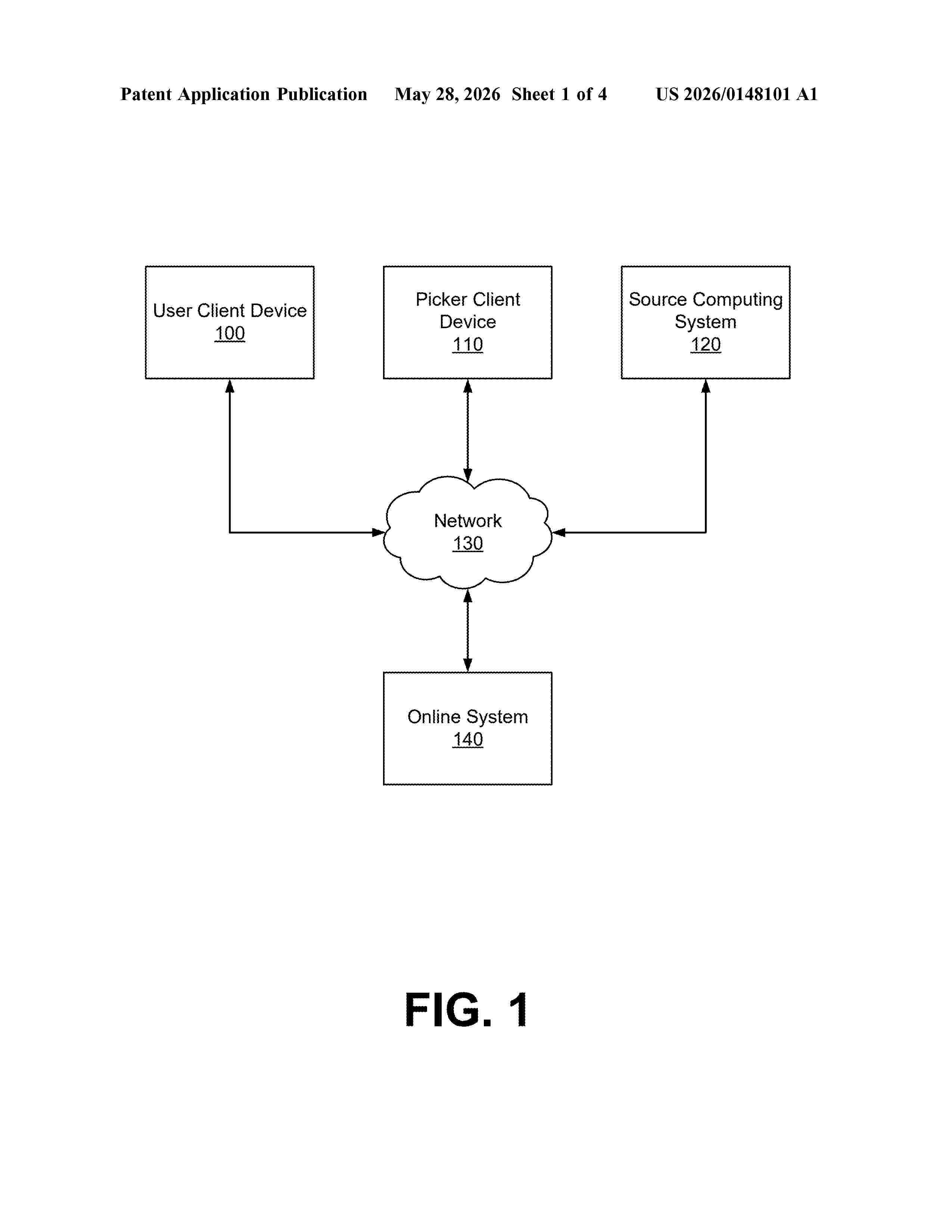
Resumen de: US20260148101A1
An online system receives a request from a client device associated with a user to place an order for pickup from a source location during a timeframe and identifies candidate remedial actions associated with the order based on the timeframe and a current time. The system retrieves user data for the user and accesses a machine-learning model. For each candidate remedial action, the system applies the model to predict, based on the user data and order data for the order, a likelihood the user will pick up the order if the candidate remedial action is taken and computes an associated value based on the likelihood. The system selects a remedial action from the candidate remedial actions based on the values, generates, based on the selected remedial action, a message associated with the order that includes a set of selectable options, and sends the message to the client device.
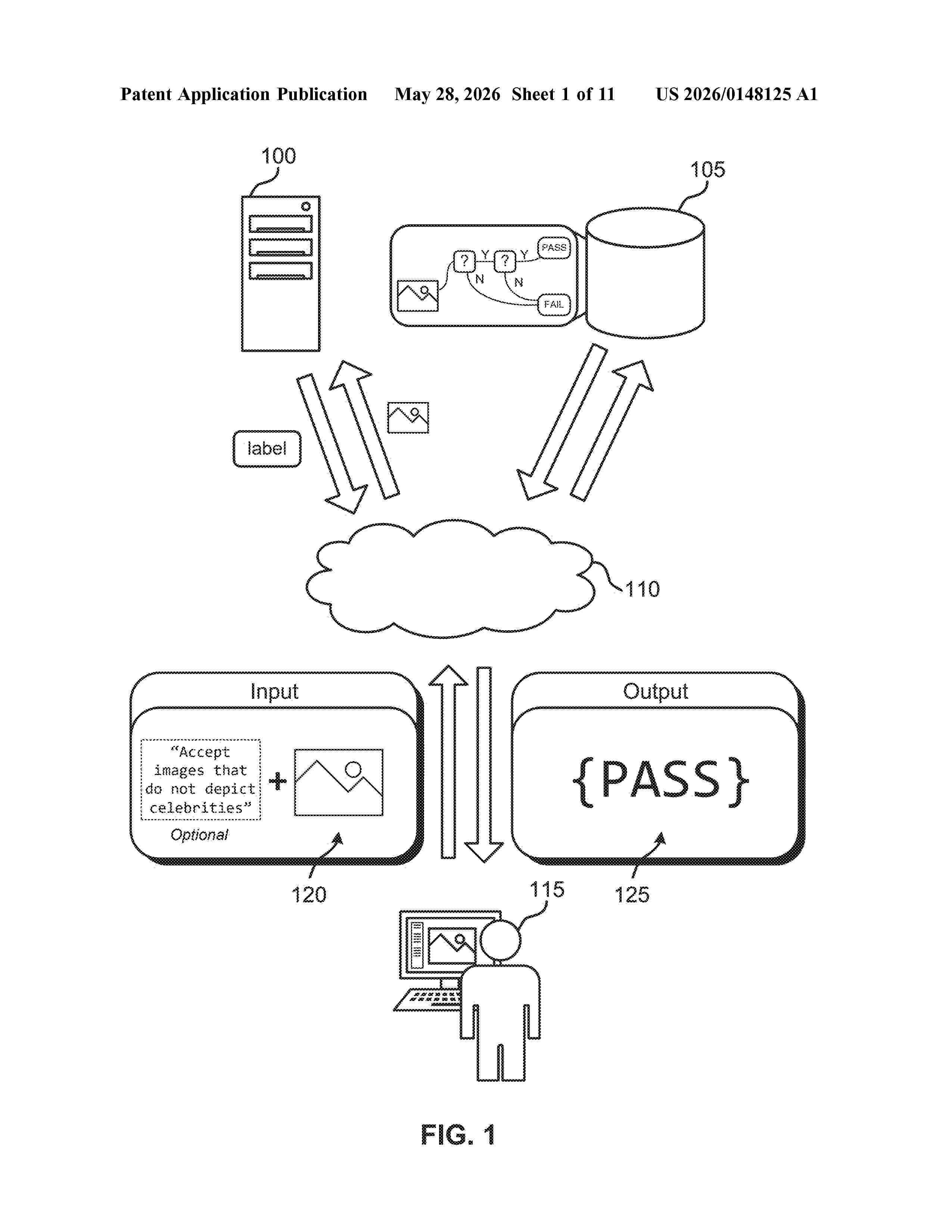
Resumen de: US20260148125A1
A method, apparatus, non-transitory computer readable medium, and system for data classification include obtaining input data and a policy graph. The policy graph includes a decision node indicating a machine learning classifier. Embodiments then generate, using the machine learning classifier, a classification result based on the input data and the decision node. Subsequently, embodiments generate a decision label for the input data based on the classification result.
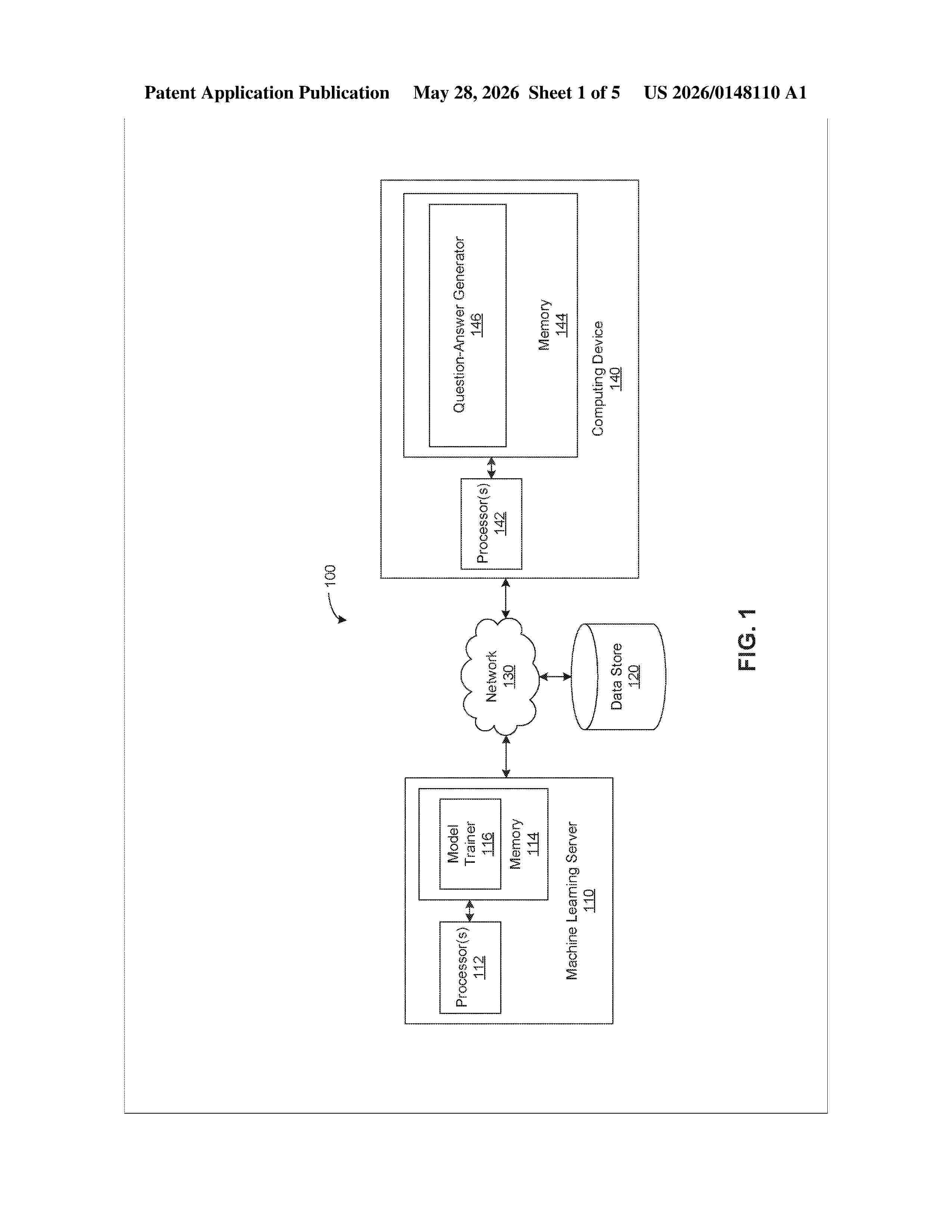
Resumen de: US20260148110A1
0000 One embodiment sets forth a technique for fine-tuning a machine learning model to perform physical reasoning. According to some embodiments, the method can include the steps of obtaining simulation annotations that describe interactions among simulated objects within a physics-based environment and one or more question templates, each question template defining a different parameterized reasoning query; generating, based on the simulation annotations and the one or more question templates, a plurality of question-answer pairs that represent physical reasoning examples; formatting the question-answer pairs into natural-language data compatible with the machine learning model; and fine-tuning the machine learning model based on the natural-language data.
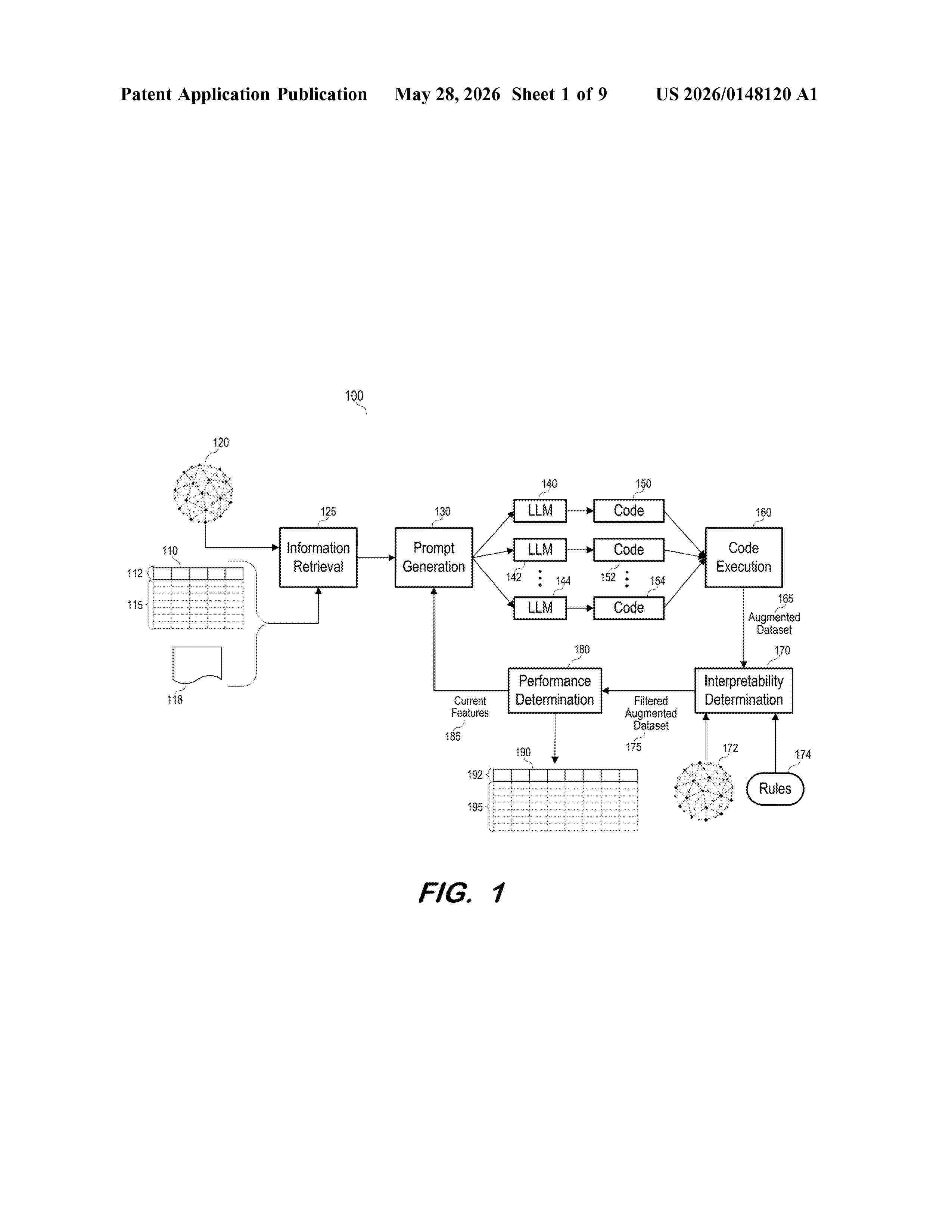
Resumen de: US20260148120A1
0000 Systems and methods include reception of a dataset comprising a plurality of features, prompting of each of a plurality of text generation models to generate code to create one or more features based on the dataset, execution of the code generated by each of the plurality of text generation models on the dataset to create a first set of candidate features, discarding of non-interpretable features of the first set of candidate features to create a second set of candidate features, determination of a performance of a machine learning model trained using the second set of candidate features, and determination to add the second set of candidate features to the dataset based on the determined performance.
Resumen de: US20260148108A1
A method for generating a logic-based evaluation result for an automated subsumption of a life situation, in particular under applicable legal norms. The steps may include: providing data documenting the facts of the case, the data comprising at least textual, pictorial, natural and/or other evidence; processing the provided data by a machine learning model to extract relevant information from the data and to present it in a structured form; matching the structured information with legal norms and/or requirements by a logic network that draws logical conclusions based on the extracted information and the legal requirements; assessment of the life situation by subsuming the extracted information under the applicable legal norms based on the results of the logic network; and output of an assessment result that includes an assignment of the life situation to the legal norms.
Resumen de: US20260148115A1
0000 Embodiments of the subject technology relate to systems, methods, and computer-readable media for using an LLM to generate an explanation of an output of an ML model. An input indicative of a scenario associated with an enterprise can be obtained. An output associated with the scenario can be generated based on the input via an ML model. An explanation of the output can be inferred by an LLM based on data associated with the ML model. A graphical representation of the output and the explanation can be generated.
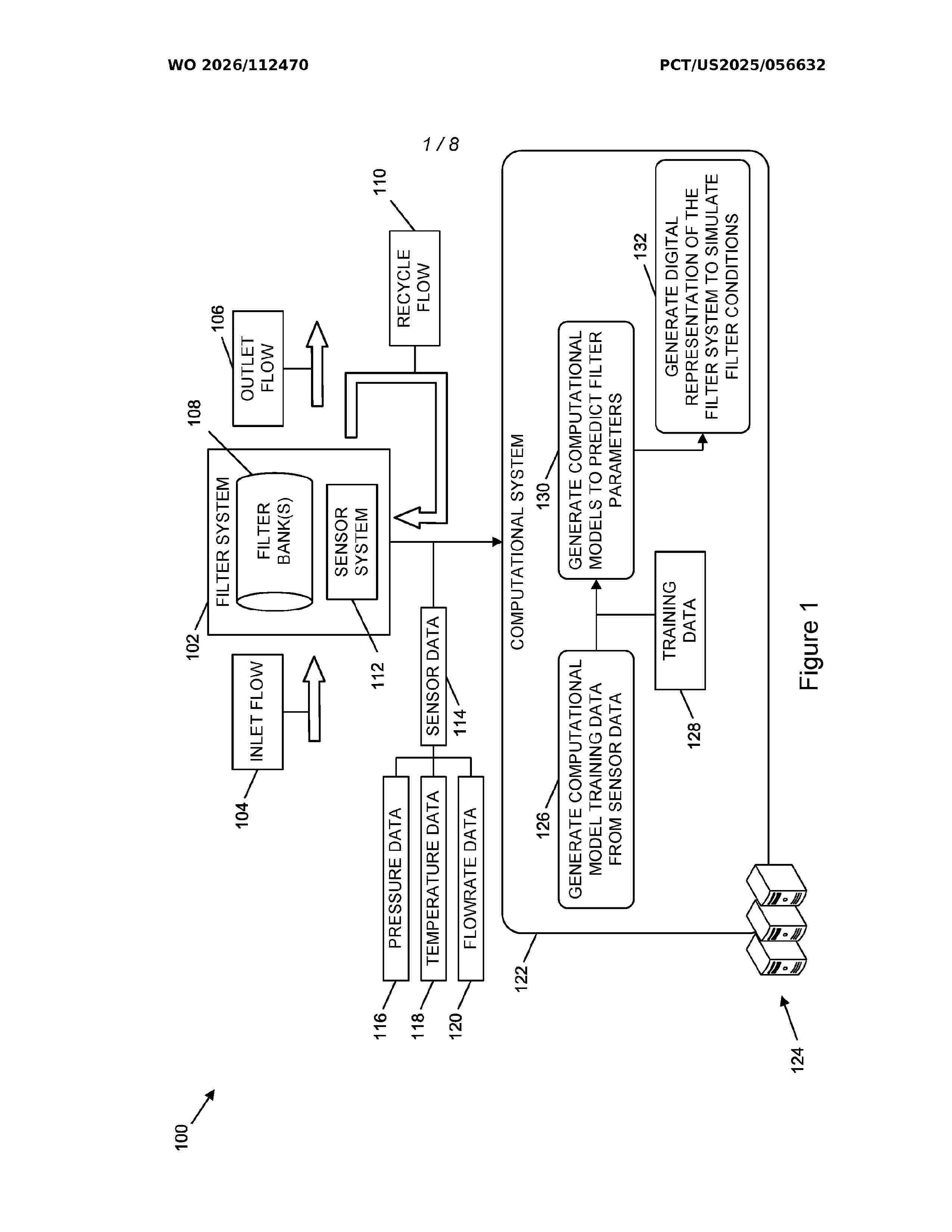
Resumen de: WO2026112470A1
The systems and processes described herein can be used to determine pressures and flowrates in a filter system that includes one or more filters. The systems and processes described herein can be used to determine a performance of the one or more filters. In one or more examples, machine learning computational models can be generated that determine when maintenance is to be performed with respect to the one or more filters. Additionally, machine learning computational models can simulate the operation of the filter system based on input obtained via one or more user interfaces.
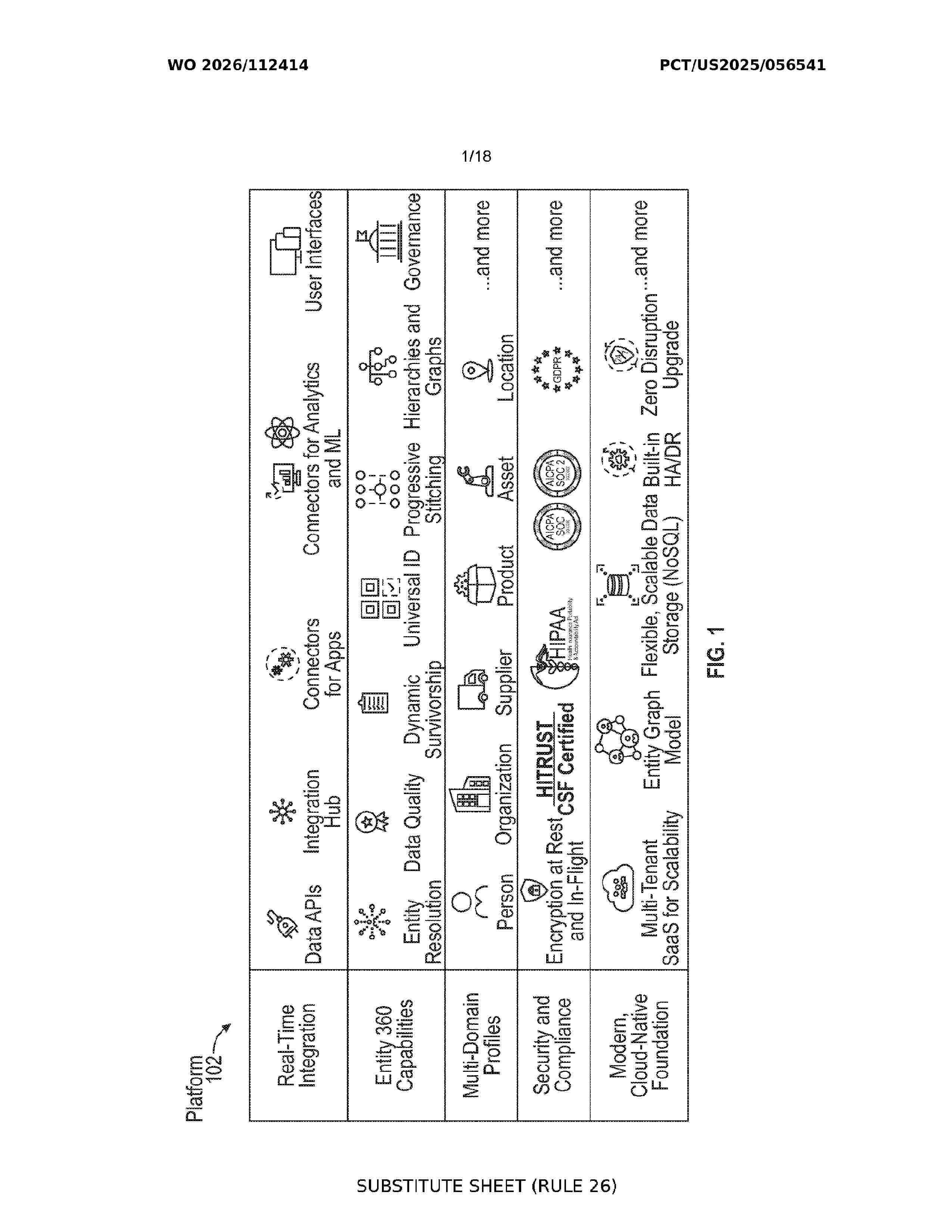
Resumen de: WO2026112414A1
Ingesting data from one or more data sources, wherein the data is associated with a tenant of a multi-tenant platform. Generating a machine learning model input based on the ingested data. Providing the generated machine learning model input to a machine learning model. Inferring, using the machine learning model, an inferred dynamic data structure, wherein the inferred dynamic data structure includes a subset of entity attributes inferred by the machine learning model from a set of the entity attributes, wherein at least a portion of the entity attributes include conditional entity attributes, wherein the conditional entity attributes depend on the values of one or more of the other entity attributes of the set of the entity attributes. Presenting, via a graphical user interface (GUI), a visual representation of the inferred dynamic data structure. Tracking user interactions received through the GUI associated with the visual representation of the inferred dynamic data structure. Dynamically adjusting, using one or more other machine learning models, the inferred dynamic data structure based on the tracked user interactions. Presenting, via the GUI, the dynamically adjusted inferred dynamic data structure.
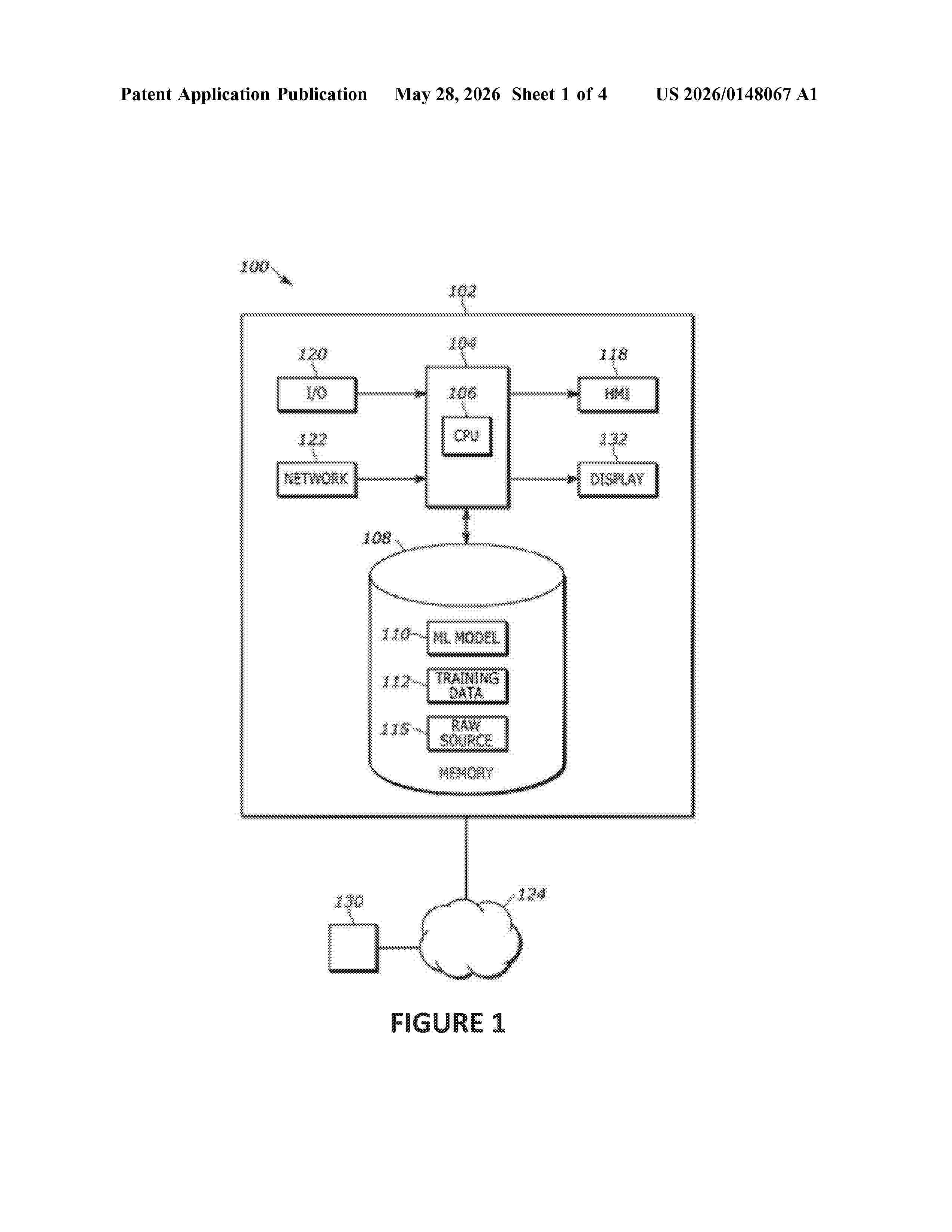
Resumen de: US20260148067A1
0000 A method and system for data classification in a multi-stage neural network system by obtaining a first physical activity sensed by the sensor and initiating a first-stage neural network trained using a subset of a dataset. The first neural network classifies the operating state of the first physical activity. A second-stage neural network, trained using the full dataset, is initiated when the first-stage neural network classifies the operating state of the first physical activity as not active. The second-stage neural network identifies features from a feature map that prevented the first-stage neural network from classifying the first activity and prunes these features. The system then obtains a second physical activity from the sensor and re-initiates the first-stage neural network to classify this second activity.
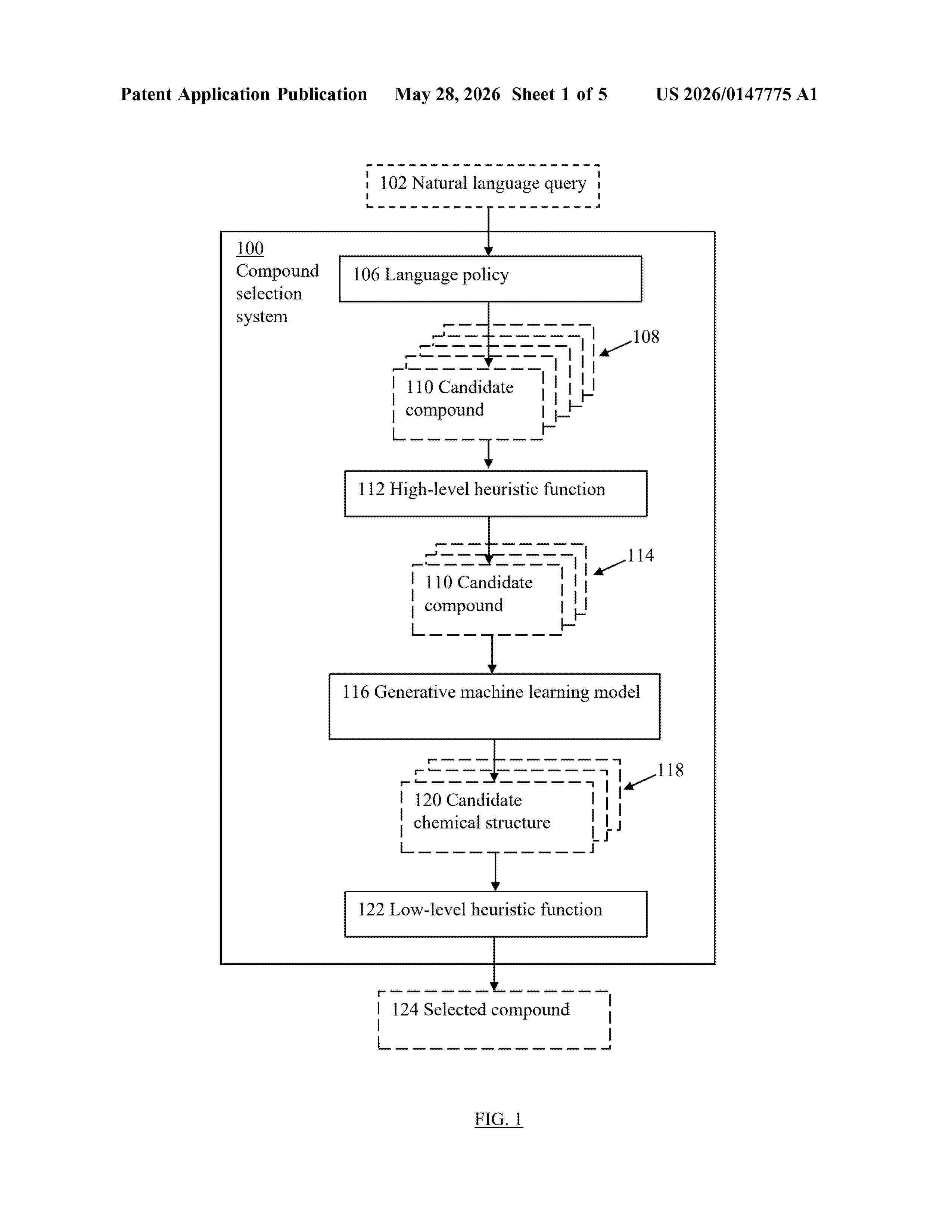
Resumen de: US20260147775A1
A method performed by one or more computers. The method comprises receiving a natural language query specifying requirements for a compound; processing the natural language query using a language policy to generate a plurality of representations of candidate compounds that each satisfy at least a subset of the requirements specified in the natural language query. Each representation specifies at least a chemical formula of the corresponding candidate compound. The method further comprises, for each representation in a subset of the representations, using a generative machine learning model conditioned on the representation to generate one or more candidate chemical structures, each candidate chemical structure comprising a respective spatial location for each of the atoms of the corresponding candidate compound; and selecting a chemical structure and corresponding compound from the plurality of candidate chemical structures.
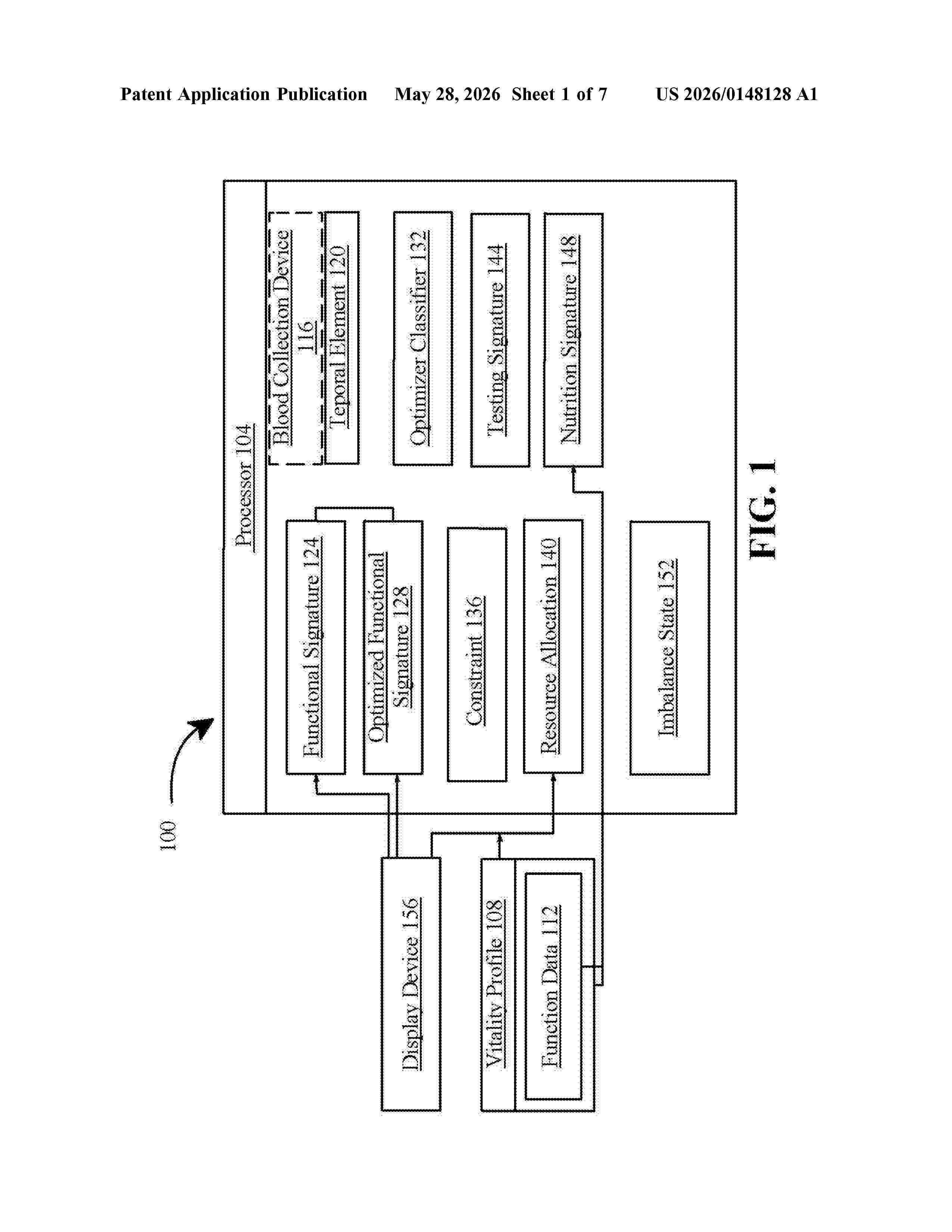
Resumen de: US20260148128A1
0000 An apparatus for calculating an optimized functional signature, comprising at least a processor; and a memory containing instructions configuring the at least a processor to receive a vitality profile relating to a user, wherein the vitality profile comprises a plurality of function data; analyze the plurality of function data to link a temporal element to each of the plurality of function data; calculate a functional signature as a function of the analyzed plurality of function data linked to a temporal element; generate an optimized functional signature as a function of the functional signature, wherein generating the optimized functional signature further comprises: identifying at least one constraint associated with the function signature using a vitality machine learning model; determining a resource allocation as a function of the optimized functional signature; and present the optimized functional signature and the resource allocation using a display device.
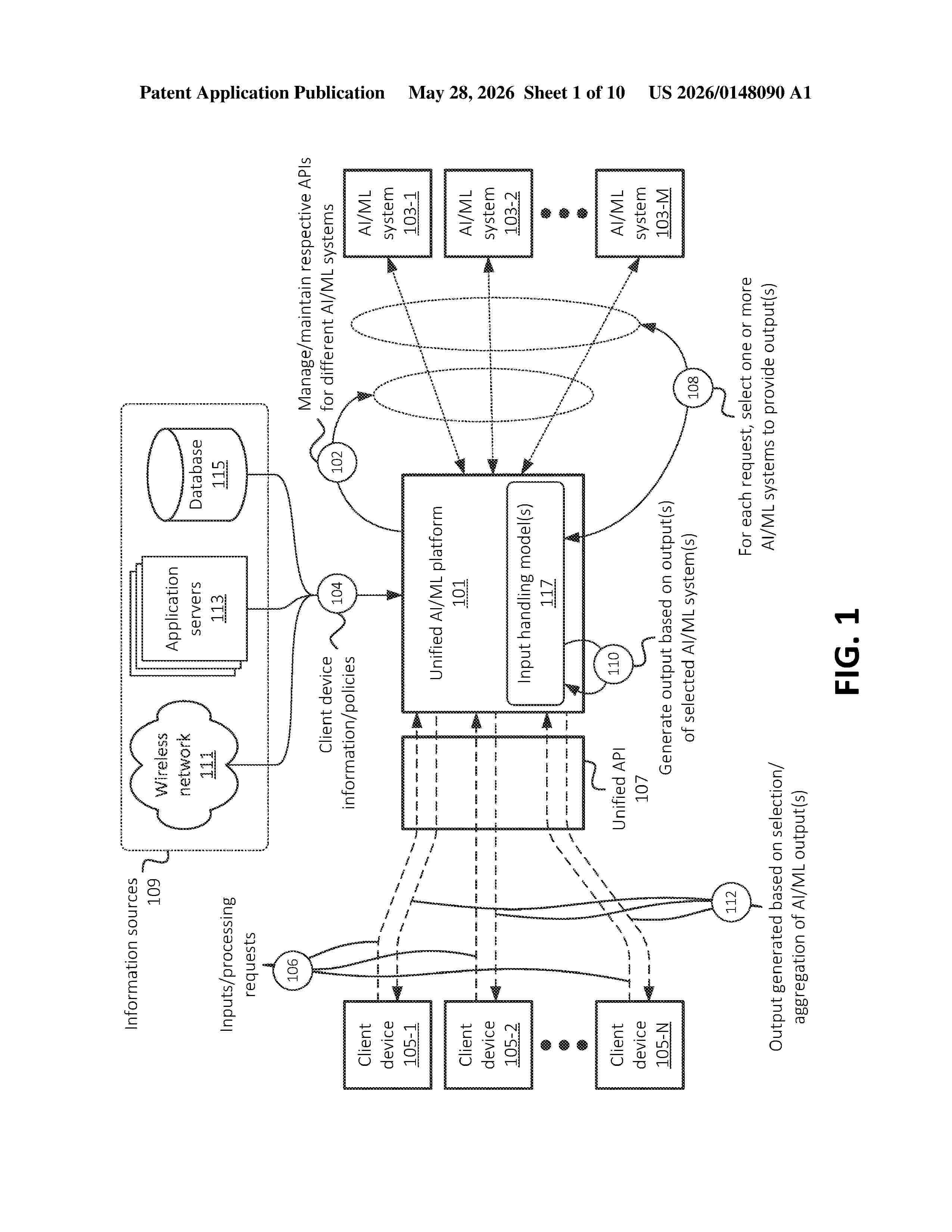
Resumen de: US20260148090A1
A system described herein may establish communications with a plurality of artificial intelligence/machine learning ("AI/ML") systems; provide an interface to a plurality of client devices; receive, via the interface and from a particular client device, of the plurality of client devices, a particular input; select, based on one or more input handling models, a particular subset of AI/ML systems to which the particular input should be forwarded; output the input to the selected subset of AI/ML systems; receive a set of outputs that are each associated with a particular AI/ML system of the selected subset of AI/ML systems; and output, via the interface and to the particular client device, at least one of one or more outputs, of the set of outputs received from the selected subset of AI/ML systems, or an aggregated output that is generated based on the set of outputs received from the subset of AI/ML systems.
Resumen de: WO2026110149A1
The present disclosure provides a method of determining a condition of a biological tissue sample. The method comprises receiving a target image depicting spatial single-cell omics data of cells in the tissue sample, constructing a multicellular network of interconnected nodes where each node represents a cell in the target image, enumerating subgraphs within the multicellular network to identify a set of spatial motifs where each spatial motif represents a multicellular pattern of interconnected cells of specific types, analyzing the set of spatial motifs to generate one or more motif-based features characterizing the biological tissue sample, and applying one or more trained machine learning models to the motif-based features to predict the condition of the biological tissue sample. The spatial motifs may include discriminative motifs that distinguish between different biological conditions such as cancer metastatic potential, survival prognosis, treatment response, or disease progression.
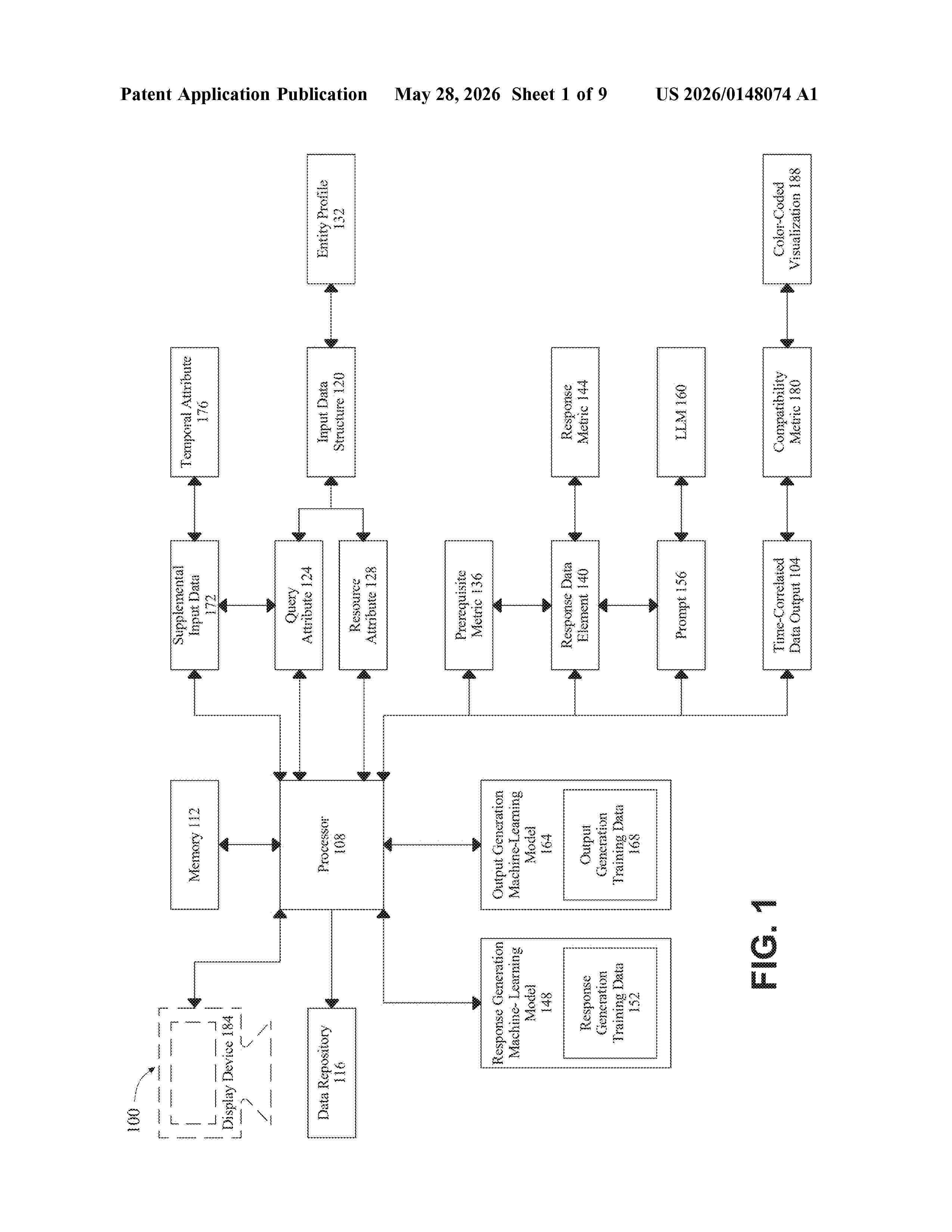
Resumen de: US20260148074A1
0000 Apparatus for generating time-correlated data outputs and methods used therein include a processor and a memory connected to the processor, wherein the memory contains instructions configuring the processor to receive from an entity an input data structure including at least a query attribute and at least a resource attribute, determine at least a response data element using a response generation machine-learning model trained on response generation training data, as a function of the input data structure, generate a prompt as a function of the at least a response data element, create at least a time-correlated data output as a function of the prompt, and display, using a graphical user interface, the at least a time-correlated data output, wherein the user interface comprises at least an event handler graphic.
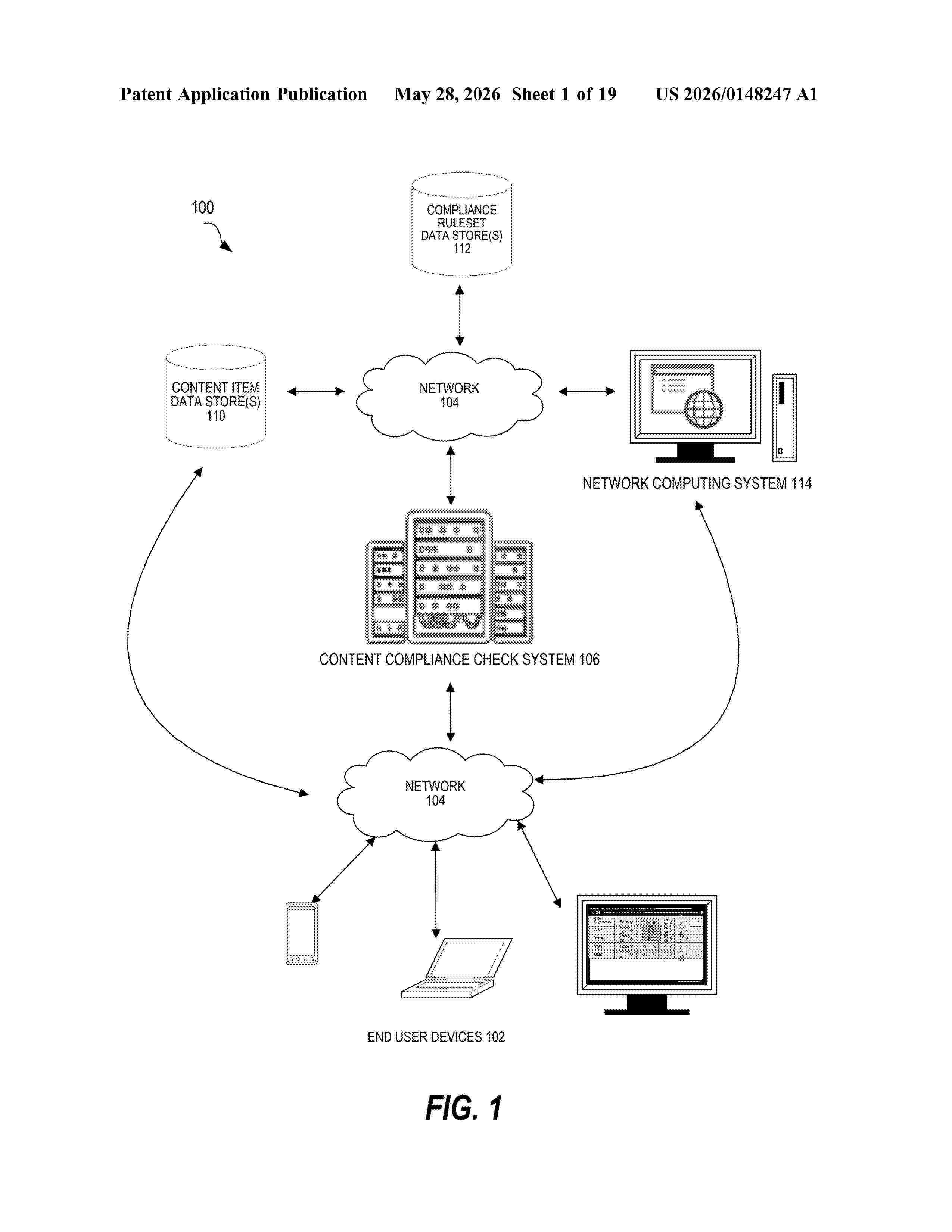
Resumen de: US20260148247A1
Computer-implemented systems and methods are disclosed, including systems and methods for performing compliance testing using language models or other machine learning models. A computer-implemented method may include, for example, accessing a content item; accessing a compliance ruleset; executing a compliance checker that utilizes a set of machine learning models; generating a prompt that includes the content item and the compliance ruleset; processing the prompt using the compliance checker; responsive to receiving a compliance determination dataset that indicates whether the content item satisfies one or more criteria within the compliance ruleset from the compliance checker; and generating an output based at least in part on the compliance determination dataset.
Nº publicación: US20260148160A1 28/05/2026
Solicitante:
DEVARAJU SUDHEER [US]
Devaraju Sudheer
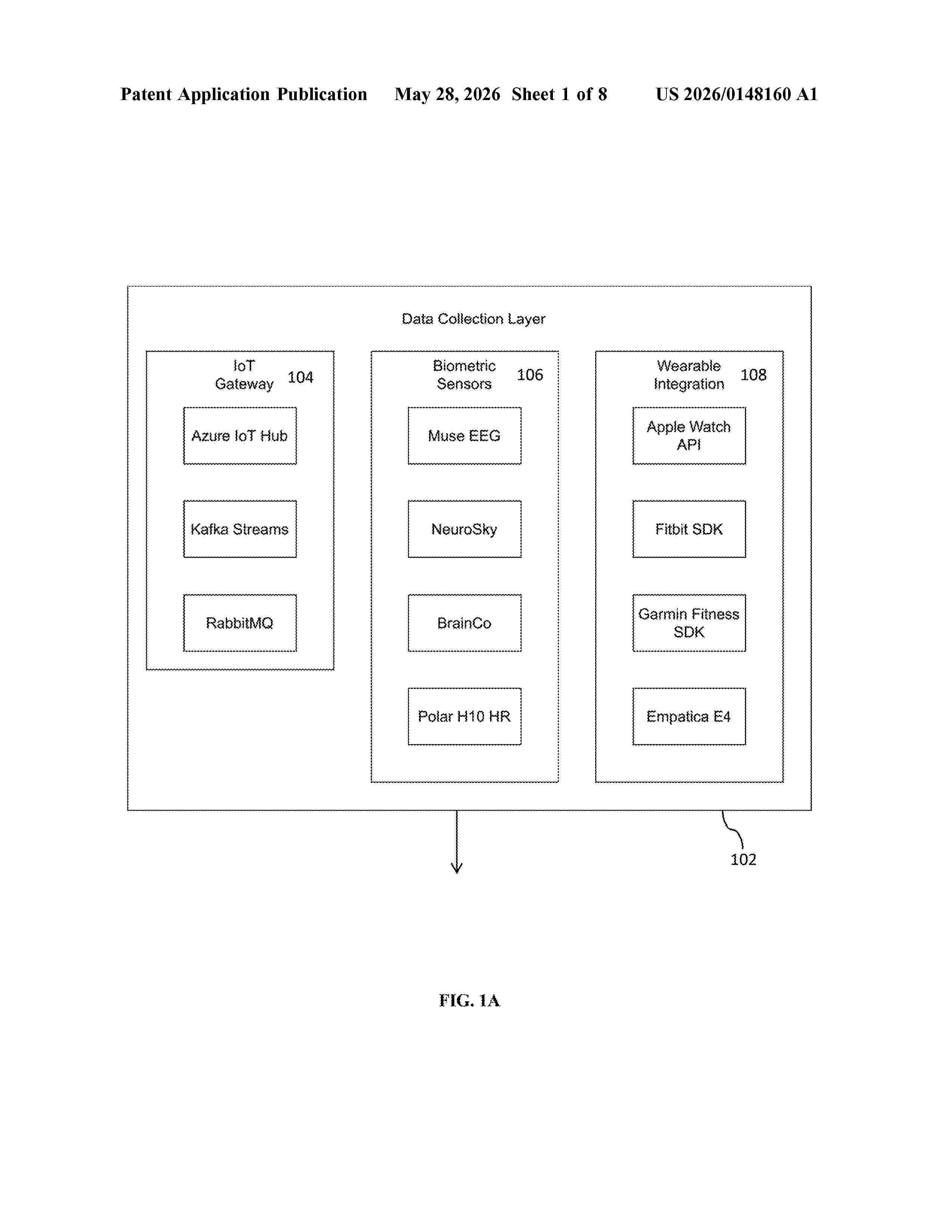
Resumen de: US20260148160A1
The invention relates to a system and method for optimizing task assignments in an enterprise environment using real-time biometric data collected from wearable devices. The system comprises a wearable device for capturing biometric signals such as heart rate, EEG data, and other physiological metrics, a data processor to filter and validate the data, a cognitive analyzer to calculate cognitive metrics including cognitive load, stress levels, and focus, and a workflow optimizer to assign tasks based on these metrics. The workflow optimizer leverages machine learning algorithms to analyze the cognitive state of users, compare it with historical performance data, and adjust workload distribution dynamically. The system integrates with enterprise resource planning (ERP) systems to synchronize optimized task assignments across the organization. By monitoring cognitive metrics in real time, the invention ensures efficient workload management, reduces employee fatigue, and enhances overall productivity.
 BOPI
BOPI
 Sede Electrónica
Sede Electrónica